Infrastructure Automation for Modern Applications
GitOps is an operational framework that utilizes Git as the single source of truth for managing various components of an application (e.g., infrastructure, configuration, etc.). Since its introduction in 2017, GitOps has become the de facto standard for managing and deploying cloud-native applications. At its core, GitOps marries the principles of X-as-Code paradigms (e.g., Infrastructure as Code, Configuration as Code, Policy as Code) for declarative management and continuous integration/delivery (CI/CD) for automated deployments. In GitOps, the state of a deployed system is always reflected in Git. Any changes to the system, including infrastructure, configuration, and policy components, must invoke a new commit to Git before being pushed out to deployed environments.
GitOps builds on DevOps best practices used for application development, such as version control, collaborative reviews via pull requests (PR), CI/CD, and compliance measures, and applies them to infrastructure automation. By tying the system state to Git, a versioned, immutable snapshot is created on every commit. This provides several benefits, including reliable deployments and rollbacks, a comprehensive audit trail for transparency and traceability, and stronger guardrails against drift in the system. Best of all, keeping the entire system definition in Git also means that your engineers can use familiar, Git-based tooling and workflows to manage both application and infrastructure changes.
Although the benefits of GitOps are well documented, the best practices for implementing GitOps in different organizations are still being formulated. In this Refcard, we’ll dive into the core principles of GitOps and its benefits, and introduce common tools and methods used to implement GitOps in practice.
GitOps practices aren't dependent on any specific technology. While logically GitOps is simply managing operations via Git, three core practices make up a mature GitOps practice: X-as-code (XaC), merge requests (MRs) as the request for change and system of record, and continuous integration/continuous delivery (CI/CD).
GitOps = XaC + MRs + CI/CD
Core Practice: X as Code
X as Code (XaC) is the practice of keeping all components of the application, such as infrastructure, configurations, policies, and more, stored as code. By shifting your environment definitions from manual configuration to configuration by code, you gain access to an array of benefits such as version control, code collaboration, and auditability. You also unlock Git as the user interface for your infrastructure, thus leveraging developer tooling, training, and knowledge associated with Git for your infrastructure operations. It is important to note that while IaC is the most well-known practice, GitOps applies to any operation that can be defined as code (e.g., network, policy, security).
Core Practice: Using Pull Requests for Changes
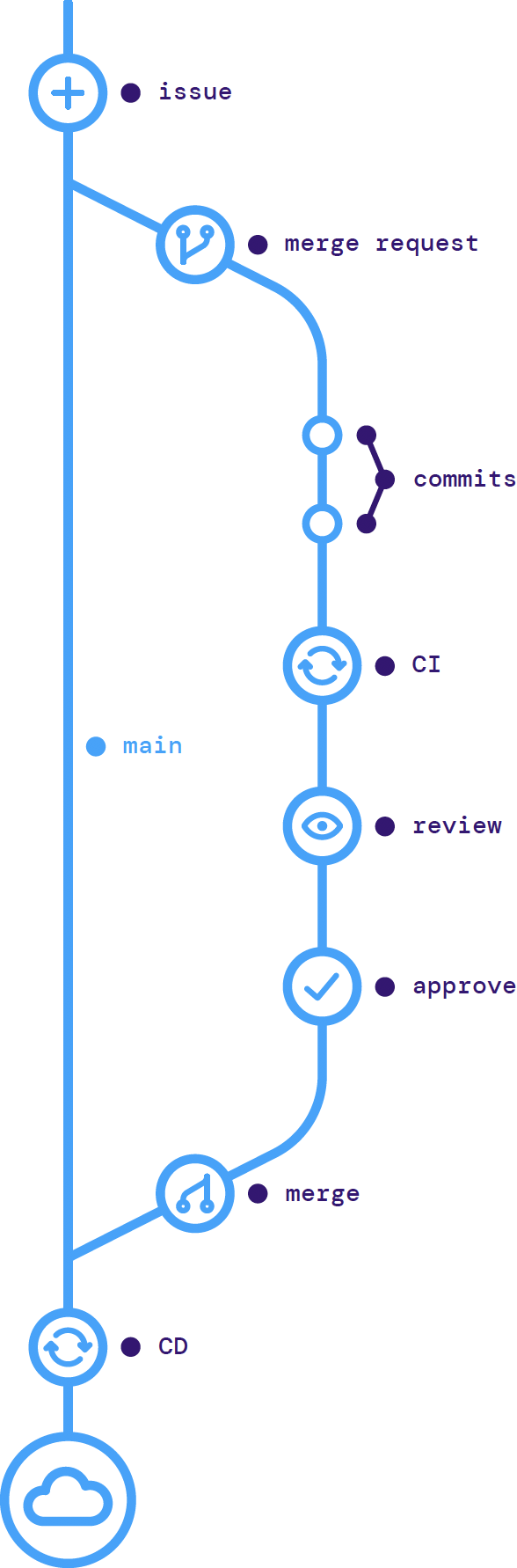
It may be surprising to learn that the underlying Git version control system used to power tools such as Bitbucket, GitHub, and GitLab doesn't include a way to request that your branch be merged back into the branch it was created or forked from. This was a later advancement introduced by Git management tools. GitHub and Bitbucket use the term pull request (PR) while GitLab uses the term merge request (MR), but functionally, they operate as a central point of developer collaboration for code review and change orchestration.
Without a proper version control and branching strategy, collaboration on new changes is a frustrating endeavor. When anyone can modify a file without a way to track who made which change, it can be almost impossible to ensure the correct version is used. A typical application development workflow uses a main branch as a centralized collaboration point. Feature branches are created from the main branch, where new work is developed, and merged back into the main branch using a pull request. Leveraging this best practice for all your infrastructure code nets you the same benefits that developers enjoy.
In an infrastructure model, the main branch represents a particular environment (e.g., dev or production), as well as the state running in that environment. Changes are proposed on a feature branch, and a PR is made to merge the changes into the main branch. This PR allows for collaboration between operations engineers for peer review, along with the development teams, security teams, and other stakeholders.
This powerful model for collaboration permits anyone to propose a change while also allowing you to maintain compliance by limiting the number of people who can merge the changes.
Figure 1: GitOps workflow
Core Practice: CI/CD Automation
The final component of a robust GitOps strategy is automating all changes made to environments via CI/CD. In an ideal scenario, no manual changes are made to a GitOps-managed environment. Instead, CI/CD serves as a type of reconciliation loop. Each time a change is made, the automation tool compares the state of the environment to the source of truth defined in the Git repository. If the Git repository shows a change, the automation tool reconciles this difference by configuring the environment to match the canonical desired state.
This type of automation serves as a powerful protection against configuration drift. There are many reasons configurations can fall out of sync. It can occur when there is a manual change for a hotfix during an outage or from natural drift over time if there are no mechanisms in place to keep all state in sync. Regardless of the reason, GitOps can rectify the drift as it overwrites the existing state with the Git source of truth on every deployment.
GitOps Models
Different models for GitOps automation have emerged, namely agentless and agent-based, each with its own pros and cons.
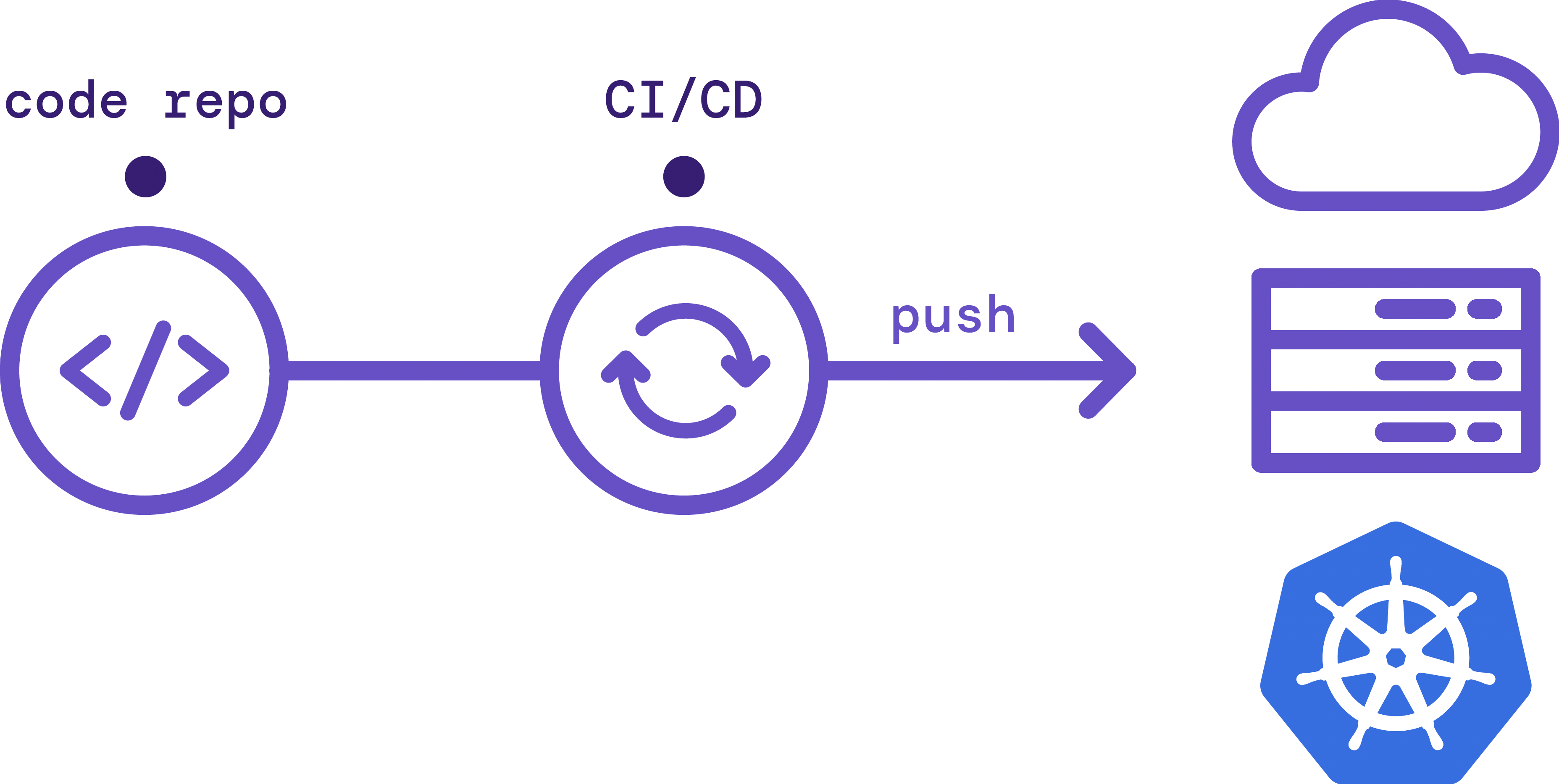
Agentless GitOps is a traditional model, also known as "push-based GitOps", in which your CI/CD tool reads from your Git repository and pushes changes into your environment.
- Pro: It's simpler and more flexible as it can be used with any infrastructure, from physical servers and VMs to Kubernetes clusters.
- Con: You must give your CI/CD tool access to make writes to your environment. Requiring your environment to be open to writes from the external internet can cause security and compliance issues.
Figure 2: Agentless GitOps model
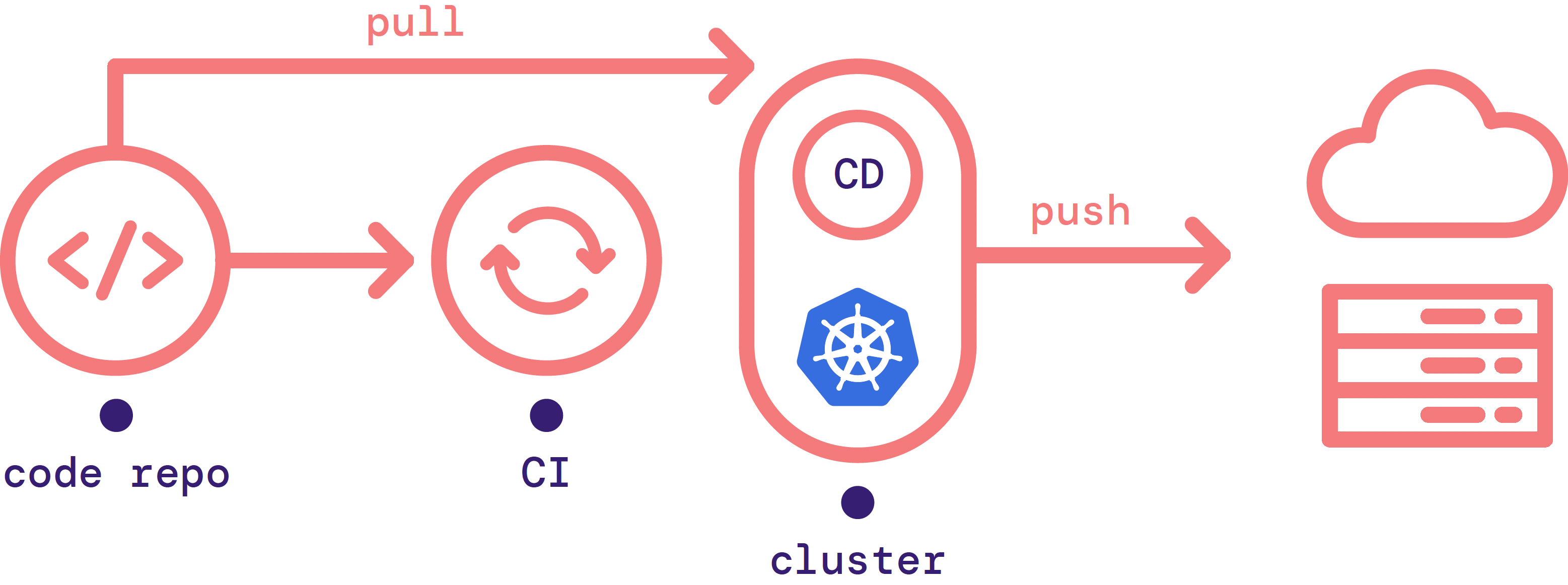
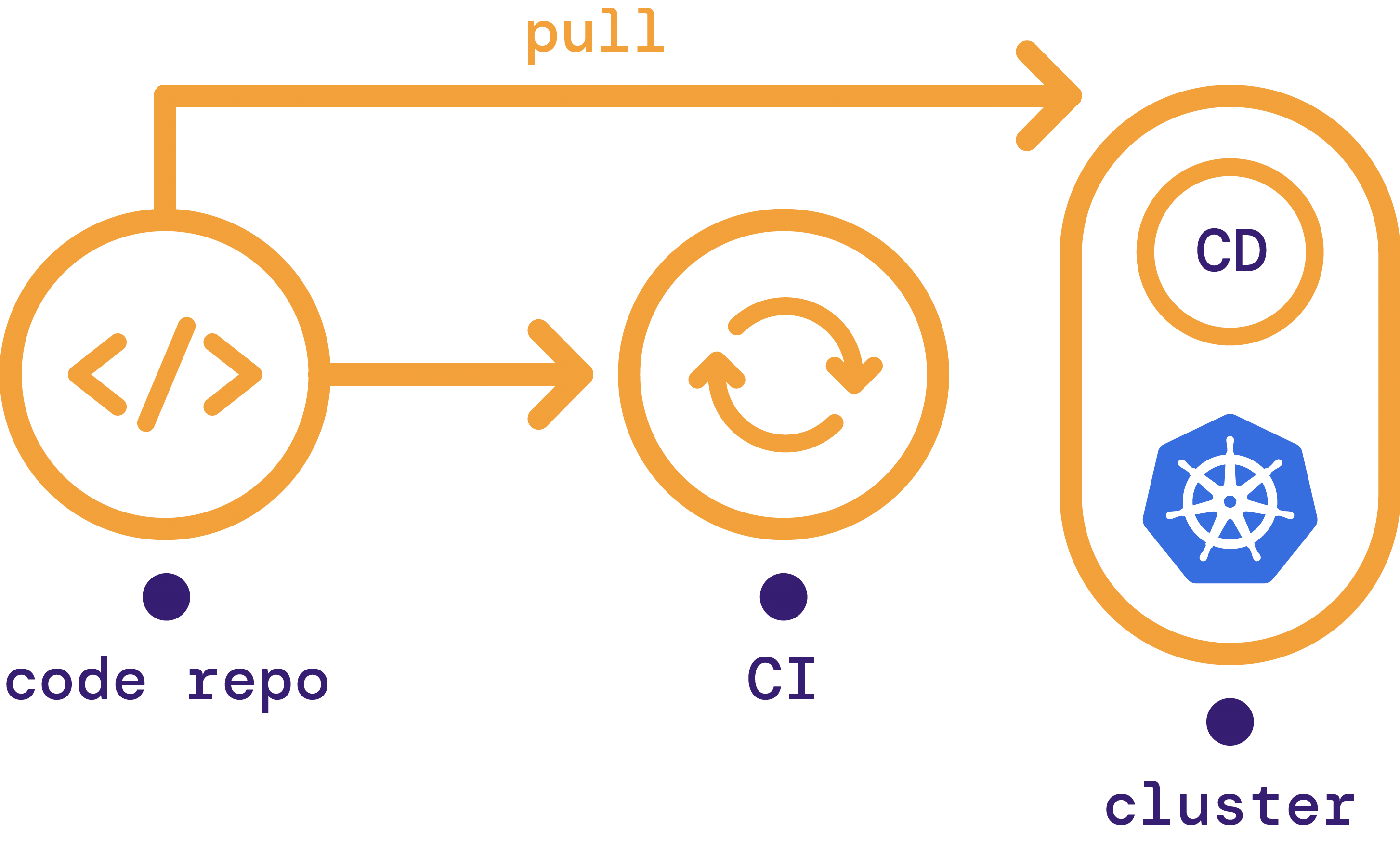
Agent-based GitOps, also known as pull-based GitOps, uses an agent that runs inside your infrastructure. This agent pulls changes in from an external Git repository when it detects that the state of the environment is out of sync with the source of truth.
- Pro: CD agents can allow you to operate in a more secure and compliant way without opening inbound ports in your firewall.
- Con: Agents must be custom-designed to the type of infrastructure you want to use.
Figure 3: Agent-based GitOps model
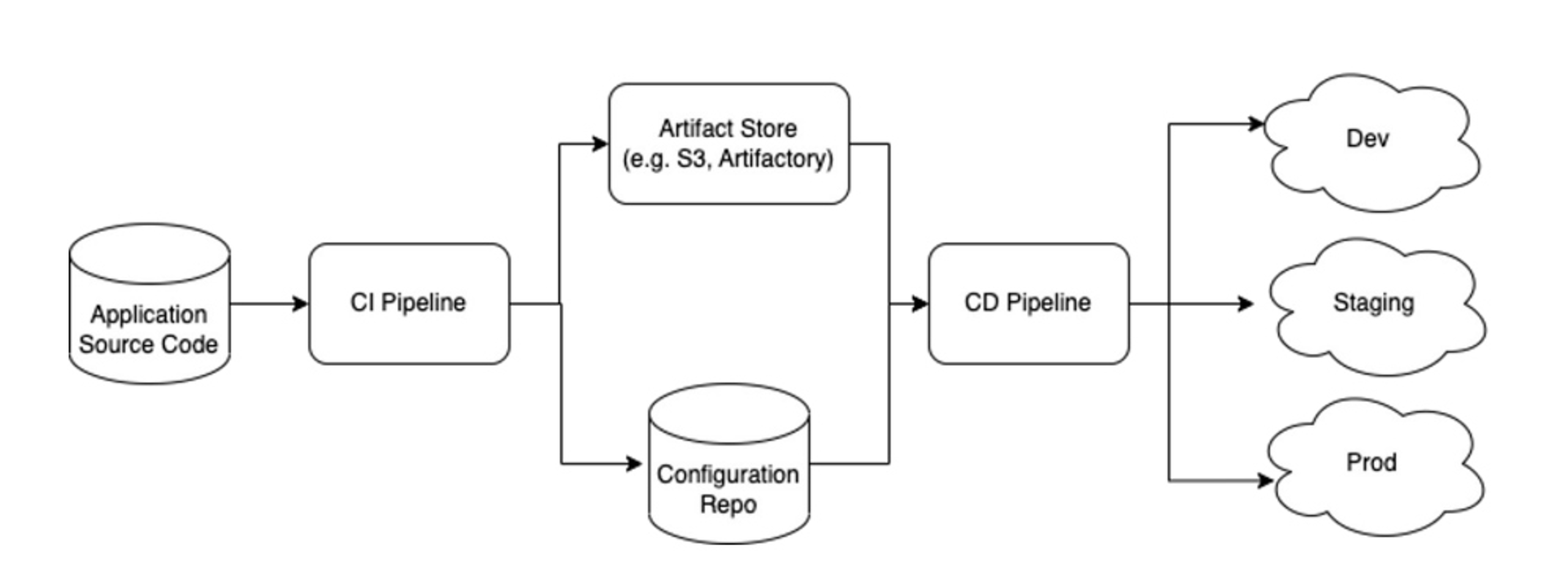
 Today, most GitOps agents, such as the GitOps Engine, are designed specifically for Kubernetes. For example, these agents won't run inside a VM-based cluster. A workaround requires setting up a Kubernetes cluster dedicated to orchestration. The CD agent runs inside the orchestration cluster and enacts changes to external infrastructure.
Today, most GitOps agents, such as the GitOps Engine, are designed specifically for Kubernetes. For example, these agents won't run inside a VM-based cluster. A workaround requires setting up a Kubernetes cluster dedicated to orchestration. The CD agent runs inside the orchestration cluster and enacts changes to external infrastructure.
Figure 4: GitOps Engine model