15 Reasons to Choose Hibernate Over JDBC
JDBC has its place, but Hibernate comes ready with an arsenal of helpful tools and capabilities that make connecting to your database a much easier prospect.
Join the DZone community and get the full member experience.
Join For Free
hey java developer,
- have you ever felt irritated by repeating the same lines of code over and over again in your application for fetching data from a database?
- are you struggling to map objects to your database tables?
- is it difficult for you to implement oops with your jdbc code?
- does it takes too much rework while migrating from one database to another?
- have you ever found it difficult to create associations between tables using jdbc?
if you are wondering whether there is a way to avoid these problems, i am very much pleased to inform you that there is an orm tool called hibernate that you can use to overcome this.
before getting into that, i would like to explain what is hibernate and jdbc.
what is jdbc?

jdbc stands for java database connectivity . it is a free open source application programming interface for java that enables applications to access databases. it enables developers to create queries and update data to a relational database using the structured query language (sql).
jdbc workflow

source: avaldes
- open a database connection
- send sql queries to database using a jdbc driver
- jdbc driver connects to the database
- execute the queries to get the result set
- send the data to the application via the driver manager
- when results are returned, it processes the data
- finally, the connection is closed
what is hibernate?

source: j2eebrain
hibernate is a free, open source object-relational mapping library for java designed to map objects to an rdbms and to implement the object-oriented programming concepts in a relational database.
hibernate workflow

source: cloudsopedia
- unlike jdbc, hibernate connects with the database itself and uses hql (hibernate query language) to execute the queries, then maps the results to java objects.
- the results are mapped to objects based on the properties given in the hibernate configuration xml file.
- the database connection from an application is created using the session, which also helps in saving and retrieving the persistent object.
- session factory is an interface that helps to create an instance of a session. there must be only one session factory per database. for example, if you are using mysql and oracle in your application, one session factory for mysql and one session factory for oracle is maintained. there will not be more than one session factory for mysql alone.
so, without further ado, let's take a look at all the reasons why you should consider hibernate over jdbc.
impedance mismatch
hibernate mainly solves the object-relational impedance mismatch problems that arise when a relational database is connected by an application written in an object-oriented programming language style. object-relational impedance mismatches arise due to data type differences, manipulative differences, transactional differences, and structural and integrity differences. click here to see more details.
object mapping
in jdbc, you need to write code to map the object model’s data representation to a relational model and its corresponding schema. hibernate itself maps java classes to database tables using xml or by using annotations. the following example will help you understand how object mapping is done in hibernate
//jdbc
list<user> users=new arraylist<user>();
while(rs.next()) {
user user = new user();
user.setuserid(rs.getstring("userid"));
user.setname(rs.getstring("firstname"));
user.setemail(rs.getstring(“email”));
users.add(user);
}
//hibernate
@entity
@table(name = "user")
public class usermodel {
@id
@generatedvalue(strategy = generationtype.identity)
private biginteger id;
@notempty
@column(name = "email", unique = true)
private string email;
@notempty
@column(name = "name")
private string name;
public biginteger getid() {
return this.id;
}
public void setid(biginteger id) {
this.id = id;
}
public string getemail() {
return email;
}
public void setemail(string email) {
this.email = email;
}
public string getname() {
return this.name;
}
public void setname(string name) {
this.name = name;
}
}
in the above example, you can see that by using jdbc, you need to set every property of an object upon fetching the data each and every time. but in hibernate, we need to map the table with the java class as mentioned above.
hql
hibernate uses hql (hibernate query language), which is similar to sql, but hibernate’s hql provides full support for polymorphic queries . hql understands object-oriented concepts like inheritance, polymorphism, and association . for a detailed understanding of polymorphic hql queries, refer to this link.
database independent
hibernate’s code is database independent because you do not need to change the hql queries (with a few exceptions) when you change databases like mysql, oracle, etc. hence, it is easy to migrate to a new database. it is achieved by using a friendly dialect to communicate with the database. the database can be specified using a dialect in the hibernate configuration xml as follows.
<property name="dialect">org.hibernate.dialect.mysql</property>
for example, consider the following scenario. you need to fetch the first 10 entries of a table. how this is implemented in different databases is explained below:
#mysql
select column_name from table_name order by column_name asc limit 10;
#sql server
select top 10 column_name from table_name order by column_name asc;
in hibernate, this can be done as follows
session.createquery("select e.id from employee e order by e.id asc").setmaxresults(10).list();
thus your query statement need not change, irrespective of the database you are using.
minimize code changes
hibernate minimizes code changes when we add a new column to a database table.
jdbc
- you have to add a new field in your pojo class.
- change your jdbc method that performs the “select” to include the new column.
- change your jdbc method that performs the “insert” to add a new value into the new column.
- change your jdbc method that performs the “update” to update an existing value in your new column.
hibernate
- add the new field into your pojo class.
- modify the hibernate xml mapping file to include the new column.
thus, database table changes can be easily implemented using hibernate with less effort.
reduce repeat code
hibernate reduces the amount of repeating lines of code , which you can often find with jdbc. for your understanding, i have left a simple scenario below.
class.forname("com.mysql.jdbc.driver");
connection con = drivermanager.getconnection( "jdbc:mysql://localhost:3306/sonoo",
"root","root");
preparedstatement stmt=con.preparestatement("insert into emp values(?,?)");
stmt.setint(1,101);
stmt.setstring(2,"ratan");
stmt.executeupdate();
con.close();
in jdbc, as mentioned above for inserting a record, you will be creating a prepared statement and will be setting each column of a table. if the number of columns increases, the statements will also increase. but in hibernate, we just need to save the object with
persist(object);
.
lazy loading
we can achieve lazy loading using hibernate. consider an example where there is a list of users in the user table. the identity proof documents uploaded by the users are stored in the identity_proof table. the user has a ‘one to many’ relationships with the identity_proof. in this case, the user is the parent class and identity_proof is the child class. if you fetch the parent class, i.e the user, all the documents associated with the user will also be fetched. imagine the size of each document. as the number of documents increases, the size of data to be processed also increases, and hence it will slow up the application.
with hibernate, you can specify the fetch type for data as lazy. if you do so when you fetch a user, documents will not be fetched. you can fetch the documents where you want using hibernate’s initialize() method.
// declaring fetch type for one to many association in your pojo
@onetomany(cascade = cascadetype.all, fetch = fetchtype.lazy)
private set<proof> prooflist = new hashset<proof>();
// to fetch user with document use initialize() method as follows
gethibernatetemplate().initialize(user.getprooflist());
avoiding try-catch blocks
jdbc will throw sqlexception, which is a checked exception. so you will be writing “try-catch” blocks in your code. hibernate handles this by converting all jdbc exceptions to unchecked exceptions. therefore, you need not waste your time implementing try-catch blocks.
transaction management

source: devarticles
a transaction is a group of operations to be performed under one task. if all the operations in a group succeed, then the task is finished and the transaction is successfully completed. if one of the operations fails, then the whole task fails, and thus the transaction also fails. . in jdbc, if a transaction is a success you need to commit. otherwise, you need to perform a rollback with the following commands:
-
con.commit(); -
con.rollback();
in hibernate, you don’t have to commit and roll back these transactions, as it is implicitly provided.
associations
it is easy to create an association between tables using hibernate. associations like one-to-one, one-to-many, many-to-one, and many-to-many can be achieved easily in hibernate by using annotations, mapping the object entity of the required table. to read more about these associations, kindly go through this link . an example for creating association is given below:
@entity
@table(name = "college")
public class college {
@id
@generatedvalue
private integer id;
@column(name="college_name")
private string name;
@onetomany(mappedby="college", cascade=cascadetype.all)
private set<department> departments;
}
@entity
@table(name = "department")
public class department {
@id
@generatedvalue
private integer id;
@column(name="department_name")
private string departmentname;
@manytoone
@joincolumn(name = "college_id")
private college college;
}
hibernate caching
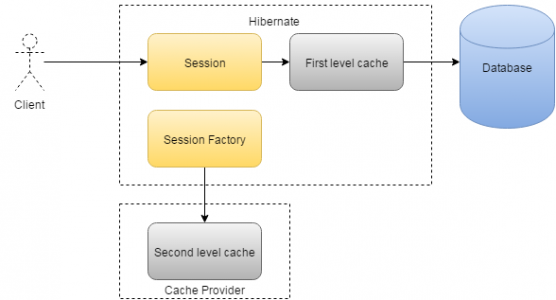
source: quora
hibernate provides a caching mechanism , which helps reduce the number of hits, as much as possible, that your application makes to the database server. this will have a considerable effect regarding the performance of your application. there is no such caching mechanism available in jdbc. this is because hibernate stores the object in session, which is available until the transaction is active. when a particular query is executed repeatedly, the value stored in the session is used. when a new transaction begins, the object is fetched again from the database and is stored in the session. in fact, two levels of caches are provided by hibernate. to learn more about hibernate caching, refer to this link .
versioning
database versioning is an important feature of hibernate. hibernate enables developers to define version type fields in an application, which is updated when data is updated every time. the advantage is if two different users retrieve the same data and then modify it, and one user saved their modified data to the database before the other user, the version is updated. now when the other user tries to saves their data, it will not allow it because this data is not up to date. in jdbc, this check is performed by the developer.
audit functionality
hibernate provides a library called “envers” , which enables us to easily gain audit functionality. it creates tables and stores the audited data with version number from where we can track the changes made to the entity. let me explain how auditing is done using envers.
@entity
@table(name = "user")
@audited
public class user {
// ... the body of the entity
}
when we add the @audited annotation in our entity class, hibernate will create a table called user_aud to store the audited entries. the table will contain two additional fields — revtype and rev. revtype is the type of the revision. it can store the values as add for inserting, mod for modifying, and del for deleting. the rev field contains the revision number of the stored entry. hibernate creates an extra table called revinfo in which the rev number is mapped with a timestamp when the change of the entity happened. you can also customize the revision table using @revisionentity.
jpa annotation support
hibernate provides support to jpa annotations like @entity, @table, @column, etc. these annotations make the code portable to other orm frameworks. you can find some of the annotations explained with an example in this link .
connection pooling
as explained on wikipedia , connection pooling is a mechanism in which the database connections, when created are stored in the cache by an external tool so that these connections can be reused from the cache when the application tries to connect to the same database in future. connection pooling helps increase performance. we can achieve this connection pooling in hibernate. hibernate supports the following pools:
you need to set the properties in hibernate.cfg.xml as required to enable connection pooling. a sample property is shown below.
<property name="hibernate.c3p0.min_size">5</property>
<property name="hibernate.c3p0.max_size">20</property>
<property name="hibernate.c3p0.timeout">300</property>
<property name="hibernate.c3p0.max_statements">50</property>
<property name="hibernate.c3p0.idle_test_period">3000</property>
conclusion
from the above-mentioned points, it is crystal clear that hibernate will definitely increase the performance of your application and help you reduce the development time for your application — and hence the cost. so by considering the above-mentioned advantages, i will recommend that everyone use hibernate over jdbc.
note: you can find some of the other open source persistence frameworks in java by following this link .
Published at DZone with permission of Mohanakrishnan Aruloli. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments