5 Agent CI/CD Evaluation Best Practices
5 lessons for AI agent evaluations we've learned the hard way: utilizing soft failures, automatic retries, explanations, avoiding flaky tests, and localized triggers.
Join the DZone community and get the full member experience.
Join For FreeBuilding reliability into your production applications isn’t flashy, but evaluations are critical to success.
This is especially true when it comes to testing the impact of system changes, as small tweaks to your AI agents — like prompt versions, agent orchestration, and model changes — can have a large impact.
The unique challenge, as we quickly found out, is that agents are non-deterministic. In other words, the same input can produce two different outputs.
This means a traditional CI/CD evaluation framework, which leverages tests with explicitly defined outputs, doesn’t work for agentic systems.

So, we rethought CI/CD for agents from first principles. In this post, we’ll share our learnings, including a new key concept that has proven pivotal to ensuring reliability at scale.
Production-grade agent reliability: Why evaluations are critical
Monte Carlo recently launched the Troubleshooting Agent, a complex AI feature that leverages hundreds of sub-agents to investigate and validate hypotheses to determine the root cause of a data reliability incident.
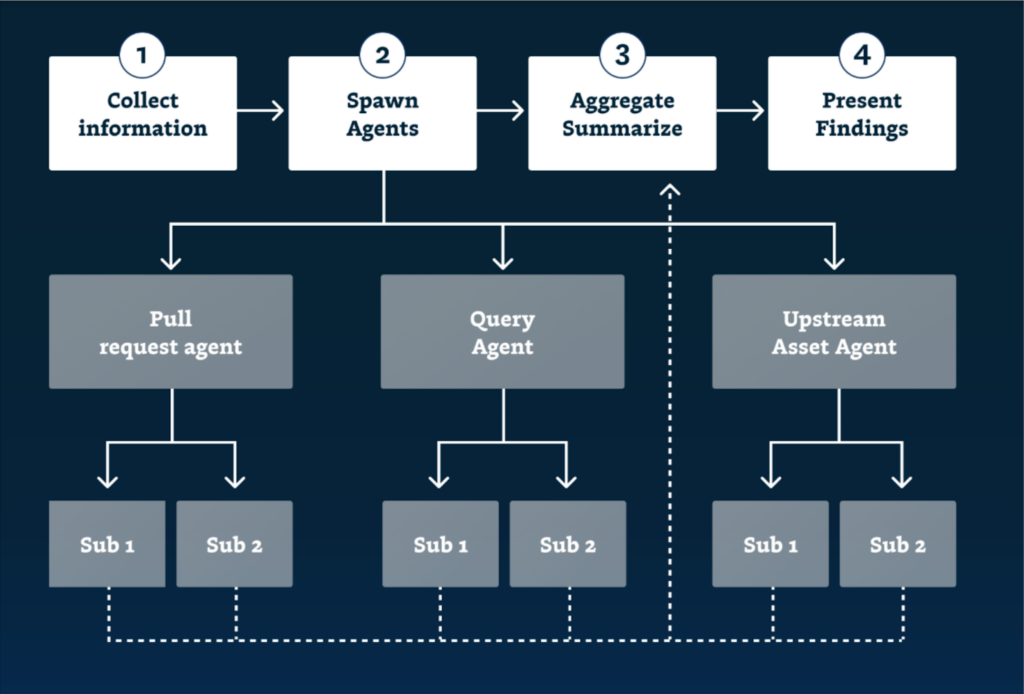
Once it became customer-facing, we needed to be as certain as possible that pushing changes wouldn’t impact agent performance. Otherwise, we risk the feature failing to deliver the desired value and becoming poorly adopted.
Our evaluation suite
There are three main categories of issues we evaluate for the Troubleshooting Agent:
- Semantic distance: How similar is the actual response to the expected output? Is the meaning intact but with different wording, or is it substantially incorrect?
- Groundedness: Did the agent retrieve the right context, and if so, did it use it correctly?
- Tool usage: Did the agent use the right tools in the right way?
For semantic issues, we leverage LLM-as-judge evaluations. We provide our LLM judge the expected output from the current configuration and ask it to score on a 0-1 scale the similarity of the new output.
We also leverage deterministic tests when appropriate, as they are clear, explainable, and cost-effective. For example, it is relatively easy to deploy a test to ensure one of the subagents’ outputs is in JSON format or to make sure the guardrails are being called as intended.
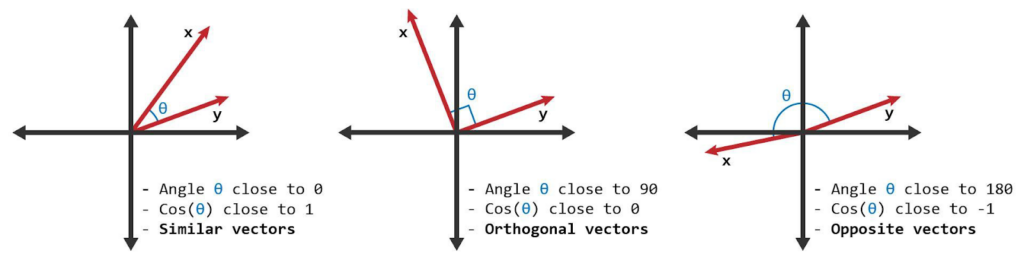
However, there are times when deterministic tests won’t get the job done. For example, we explored embedding both expected and new outputs as vectors and using cosine similarity tests. We thought this would be a cheaper and faster way to evaluate semantic distance between observed and expected outputs.
However, we found there were too many cases in which the wording was similar, but the meaning was different.
We use a series of LLM-as-judge evaluations to evaluate groundedness and tool usage. We want to make sure the agent has and uses the context it’s been provided and that it uses the right tools, the right way.
Groundedness checks cover two behaviors:
1. When the key context is present, the answer must be grounded in it: accurate, supported, and free of unsupported claims.
2. When the key context is missing or the question is out of scope (per guardrails), the agent should decline to answer. Any invented facts or capabilities is a failure.
For tool usage, we have an LLM-as-judge evaluate whether the agent performed as expected for the pre-defined scenario, meaning:
- No tool was expected, and no tool was called
- A tool was expected, and a permitted tool was used
- No required tools were omitted
- No non-permitted tools were used
This agent evaluation suite has worked very well, but the key to it all is a series of five best practices that make nondeterministic systems testable.
5 agent evaluation best practices
By far the most significant unlock for our evaluation framework was the introduction of the concept of a “soft failure.”
With traditional CI/CD testing everything is a hard failure. If the code you are pushing causes a test to fail then that code isn’t merging to production. Full stop. Black and white.
In the gray world of agentic systems, this doesn’t make as much sense. Not only is the underlying system nondeterministic, but so are the majority of the tests (or LLM-as-judge evaluations). You are testing for hallucinations with evaluations that can hallucinate.
Soft failures
We quickly realized you need to build a little breathing room into your tests, which is what a soft failure provides.
The LLM-as-judge evaluation comes back with a score between 0-1. Anything less than a .5 is a hard failure, while anything above a .8 is a pass. Soft failures occur for scores between .5 to .8.
Changes can be merged for a soft failure. However, if a certain threshold of soft failures is exceeded, it constitutes a hard failure, and the process is halted. For our agent, it is currently configured so that if 33% of tests result in a soft failure or if there are any more than two soft failures total, then it is considered a hard failure. This prevents the change from being merged.
Automatic retries
The second AI agent evaluation best practice is to automate re-evaluations for this type of aggregated hard failure. In our experience, about one in ten tests produces a spurious result where the output is fine but the tests are hallucinating. In these cases, a retry mechanism is triggered, and if the resulting tests pass, we assume this was a one-time random effect.
Explanations
When a test fails, you need to understand why it failed. This is very easy with traditional CI/CD tests with very defined conditions, but much harder with non-deterministic agents. We now ask every LLM judge not only to provide a score, but also to explain it. This helps build trust in the evaluation and can even speed debugging.
Evaluating evaluators
We don’t think AI agent evaluation is what Juvenal meant when he asked, “Who will guard the guards?” but it’s apropos. It’s very meta, but yes, you have to test your tests. We run tests multiple times, and if the delta is too large, we will revise or remove the flaky test.
Localized tests and conservative triggers
Compared to traditional testing, agent evaluations are expensive and time-consuming. We spoke with one data + AI team that told us the cost of their evaluations crept up to 10x the cost of running the agent itself!
Once we started scaling ourselves, we began to see why. There are multiple gates, and the underlying computer is more expensive. To save both time and money, we have been very deliberate about how and when we test.
Our tests are typically localized. We won’t spin up the agent and do an entire run to test the outputs of one LLM call. For example, we’ll often supply the root cause analysis information the subagent would have collected.
For now, we have also decided to be more selective when we run our evaluations. Tests are only triggered when a team member is merging a PR that modifies specific components of the agent. At this moment, our goal is not to cross a 1:1 ratio for testing to operation costs.
What causes evaluations to fail
We are still relatively early in our journey, but there are clear patterns in the types of changes that will cause tests to fail and can introduce reliability issues into your agentic systems. We’ve categorized these within a data, systems, code, and model framework. A few quick examples:
Data
- Real-world changes and input drift. For example, if a company enters a new market and there are now more users speaking Spanish than English, this could impact the language the model was trained in.
- Unavailable context. We recently wrote about an issue where the model was working as intended, but the context on the root cause (in this case, a list of recent pull requests made on table queries) was missing.
System
- Any change to what tools are provided to the agent or changes in the tools themselves.
- Changes to how the agents are orchestrated.
Code
- Updates to prompts.
- Changes impacting how the output is formatted.
Model
- Platform updates their model version.
- Changes to which model is used for a specific call.
Monitoring in production
AI agent evaluation and CI/CD testing are new and challenging, but it’s a walk in the park compared to monitoring agent behavior and outputs in production. Inputs are messier, there is no expected output to baseline, and everything is at a much larger scale.
Not to mention the stakes are much higher! System reliability problems quickly become business problems. This is our current focus.
This article was co-written with Elor Arieli, Alik Peltinovich, and Michael Segner.
Published at DZone with permission of Lior Gavish. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments