A Beginner’s Guide: Build RAG With Milvus in 10 Minutes
Learn how to build your first RAG application with Milvus Lite and LangChain and turn vector embeddings into a naive RAG application using Python.
Join the DZone community and get the full member experience.
Join For FreeMilvus is an open-source vector database for building high-performance AI applications such as semantic search engines, AI chatbots, natural language processing (NLP) systems, and retrieval-augmented generation (RAG). It can manage and search massive vector collections, making it ideal for handling large-scale datasets with billions of entries.
In this article, you'll learn the concept of vector databases, how to install Milvus, and a step-by-step guide on how to build RAG with Milvus in 10 minutes. Whether you're an ML engineer or a hobbyist exploring vector databases, this guide will help you better understand Milvus and its practical applications.
Understanding Vector Databases and RAG
Vector Databases
Let’s start with the concept of vector databases.
Vector databases are custom-designed systems that efficiently store, index, and query high-dimensional vector data. Unlike traditional databases, which are super fast at handling structured data in rows and columns, vector databases are optimized for working with complex, unstructured data (such as text, images, and videos) represented as mathematical vectors.
Their unique architecture shines in scenarios such as:
- Similarity Searches: Finding items that are "most like" a given query.
- Nearest Neighbor Queries: Identifying the closest matches to a specific data point.
- Clustering: Grouping similar items based on their vector representations.
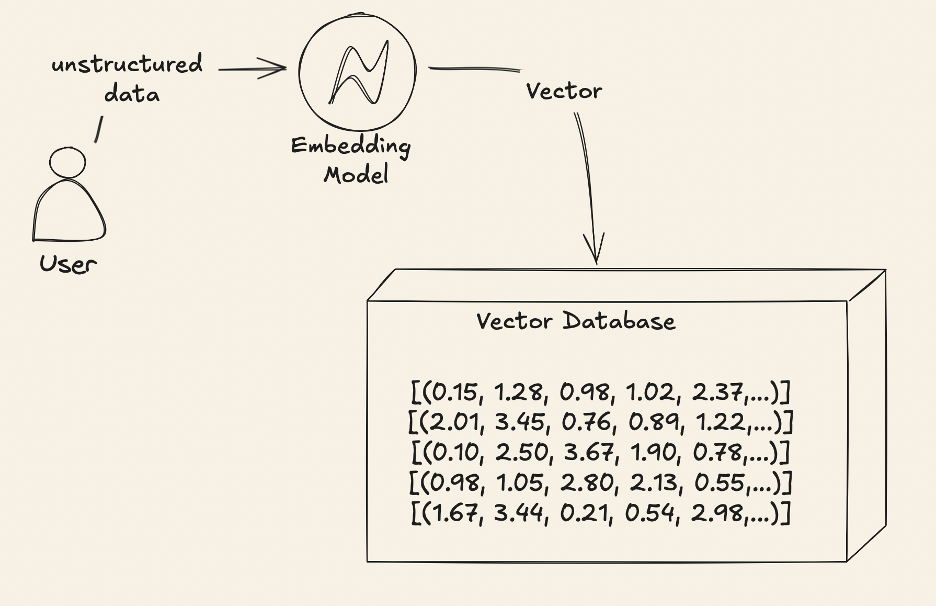
A vector similarity search workflow is built around four essential components:
- Unstructured Data: Raw data like text, images, or audio.
- Embedding Model: Transforms the unstructured data into numerical vectors, capturing key features.
- Vector: A numerical representation of the data, where each dimension reflects a specific characteristic of the original input.
- Vector Database: Stores these vectors and enables rapid similarity searches.
Info: Choosing the right embedding model is crucial as it determines how effectively your data's context and meaning are captured in the vector format. This directly impacts the accuracy and relevance of search results and AI-driven insights.
Retrieval Augmented Generation
Retrieval-Augmented Generation (RAG) is a technique for reducing LLM hallucinations and improving output accuracy by retrieving relevant contextual information from external sources. Vector databases play an important role in this process, and they serve as knowledge bases by storing, indexing, and retrieving embedded data representations. When a user submits a query, it is converted into a vector, and the database retrieves similar vectors by calculating distances between them in high-dimensional space.
Installing Milvus Lite
Now that we understand the fundamentals of vector databases and RAG, let's learn how to get Milvus up and running on your system.
Milvus offers various installation options that cater to your needs and environments.
- Milvus Lite: for quick experimentation, local development, and small-scale projects.
- Milvus Standalone: for medium-sized production deployments
- Milvus Distributed: for large-scale, high-performance production environments.
In this guide, we'll use Milvus Lite for simplicity. It offers a straightforward setup process using pip.
Prerequisites
Milvus Lite currently supports the following environments:
- Ubuntu >= 20.04 (x86_64 and arm64)
- MacOS >= 11.0 (Apple Silicon M1/M2 and x86_64)
Set Up Milvus Lite
Milvus Lite is included in pymilvus, the Python SDK of Milvus, and can be deployed simply by running pip install pymilvus.
pip install -U pymilvusImplement a Basic RAG With Milvus Lite and LangChain
Now, let's walk through a practical example of implementing a basic RAG pipeline using Milvus Lite and LangChain. We'll create a system to answer questions about Milvus by querying a Milvus vector store populated with the Milvus doc files.
Step 1: Setting Up the Environment
First, we'll install the necessary packages and import the required modules. These imports set up our environment with LangChain for document loading and embedding, Milvus for vector storage, and Rich for enhanced terminal output.
# Uncomment the line below to install the required packages
# %pip install langchain-community langchain-openai langchain-milvus rich
from langchain_community.document_loaders import GithubFileLoader
from langchain_openai import OpenAIEmbeddings
from langchain_milvus import Milvus
from rich import print as rprint
from rich.markdown import MarkdownStep 2: Configuring API Keys
To access GitHub and OpenAI services, we need to set up API keys. Remember to keep your API keys secure, preferably using environment variables.
# .env file!
OPENAI_API_KEY = ""
GITHUB_ACCESS_TOKEN = ""
# Generate a personal access token at: https://github.com/settings/tokens
# It's highly recommended to use a .env file in your project folder to secure API keys!
Step 3: Loading Documents from GitHub
We'll use LangChain's GithubFileLoader to fetch Markdown files from the Milvus repository. This step retrieves all Markdown files from the Milvus GitHub repository, which will serve as our knowledge base.
loader = GithubFileLoader(
repo="milvus-io/milvus",
branch="master",
access_token=GITHUB_ACCESS_TOKEN,
github_api_url="https://api.github.com",
file_filter=lambda file_path: file_path.endswith(".md")
)
# Load all the documents
documents = loader.load()Step 4: Setting Up the Embedding Model
We'll use OpenAI's text embedding model to convert our documents into vector representations. This embedding model transforms text into high-dimensional vectors, capturing semantic meaning.
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")Step 5: Creating and Populating the Vector Store
Now, we'll set up our Milvus vector store. This step creates a Milvus collection and populates it with vector representations of our documents.
# If you have a Milvus server, you can use the server URI (e.g., "http://localhost:19530").
# Otherwise, Milvus Lite will store everything in a local file.
URI = "./getting_started.db"
vector_store = Milvus.from_documents(
documents,
embeddings,
collection_name="getting_started",
connection_args={"uri": URI},
)
# Add documents to the vector store
vector_store.add_documents(documents=documents)Step 6: Querying the Vector Store
Finally, we'll perform a similarity search to answer a question about Milvus. This query searches for the most similar document to our question, effectively retrieving the most relevant information from our knowledge base.
result = vector_store.similarity_search(
"What's the best way to use Milvus on your small local machine?",
k=1 # top_k
)
rprint(Markdown(result[0].page_content))Here's the complete code to run in a single file:
# To install packages uncomment the line below
# %pip install langchain-community langchain-openai langchain-milvus rich
from langchain_community.document_loaders import GithubFileLoader
from langchain_openai import OpenAIEmbeddings
from langchain_milvus import Milvus
from rich import print as rprint
from rich.markdown import Markdown
# We’re using rich for pretty printing on the terminal
# To use github and openai, we should create api_keys on their platforms.
OPENAI_API_KEY = “”
GITHUB_ACCESS_TOKEN = “”
# You can generate a personal access token here: https://github.com/settings/tokens
# You should definitely use the .env file on your project folder to secure api keys!
# To load all github markdown files, we’re using langchain loader.
loader= GithubFileLoader(
repo="milvus-io/milvus", # the repo name
branch="master", # the branch name
access_token=GITHUB_ACCESS_TOKEN,
github_api_url="https://api.github.com",
file_filter=lambda file_path: file_path.endswith(
".md"
), # load all markdowns files.
)
# All the documents are loaded
documents = loader.load()
# Embedding model for vector store
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# If you have a Milvus server you can use the server URI such as "http://localhost:19530".
# otherwise, Milvus Lite is used where everything is stored in a local file.
URI = "./getting_started.db"
vector_store = Milvus.from_documents(
documents,
embeddings,
collection_name="getting_started",
connection_args={"uri": URI},
)
vector_store.add_documents(documents=documents)
# Query the vector store
result = vector_store.similarity_search(
"What's the best way to use Milvus on your small local machine?",
k=1
)
rprint(Markdown(result[0].page_content))At the end of running the script, your terminal should display output similar to the image below:
The retrieved content answers our previous question, demonstrating this RAG system's capability to pull information directly from Milvus' GitHub files.
Summary
In this guide, we've covered:
- The concept of vector databases and their importance in handling unstructured data
- An overview of Milvus and its advantages in the vector database landscape
- Setting up Milvus Lite for quick experimentation
- Implementing a RAG pipeline using Milvus Lite
If you’d like to learn more, check out all the tutorials and demos built with Milvus. You can also join the Milvus Discord community to connect with other AI developers and all the creators of Milvus.
Opinions expressed by DZone contributors are their own.
Comments