A Data Lake Architecture With Hadoop and Open Source Search Engines
"Big data" and "data lake" only have meaning to an organization’s vision when they solve business problems by enabling data democratization, re-use, exploration, and analytics. Read on to learn what a data lake is, its various benefits, and what's to come.
Join the DZone community and get the full member experience.
Join For Freeusing enterprise data lakes for modern analytics and business intelligence
"big data" and "data lake" only have meaning to an organization’s vision when they solve business problems by enabling data democratization, re-use, exploration, and analytics. at search technologies, we’re using big data architectures to improve search and analytics, and we’re helping organizations do amazing things as a result.
what is a data lake?
a data lake is a large storage repository that holds a vast amount of raw data in its native format until it is needed. an "enterprise data lake" (edl) is simply a data lake for enterprise-wide information storage and sharing.
what are the benefits of a data lake?
the main benefit of a data lake is the centralization of disparate content sources. once gathered together (from their "information silos"), these sources can be combined and processed using big data, search, and analytics techniques which would have otherwise been impossible. the disparate content sources will often contain proprietary and sensitive information which will require implementation of the appropriate security measures in the data lake.
 the security measures in the data lake may be assigned in a way that grants access to certain information to users of the data lake that do not have access to the original content source. these users are entitled to the information, yet unable to access it in its source for some reason.
the security measures in the data lake may be assigned in a way that grants access to certain information to users of the data lake that do not have access to the original content source. these users are entitled to the information, yet unable to access it in its source for some reason.
some users may not need to work with the data in the original content source but consume the data resulting from processes built into those sources. there may be a licensing limit to the original content source that prevents some users from getting their own credentials. in some cases, the original content source has been locked down, is obsolete, or will be decommissioned soon; yet, its content is still valuable to users of the data lake.
once the content is in the data lake, it can be normalized and enriched . this can include metadata extraction, format conversion, augmentation, entity extraction, cross-linking, aggregation, de-normalization, or indexing. read more about data preparation best practices. data is prepared "as needed," reducing preparation costs over up-front processing (such as would be required by data warehouses). a big data compute fabric makes it possible to scale this processing to include the largest possible enterprise-wide data sets.
users, from different departments, potentially scattered around the globe, can have flexible access to the data lake and its content from anywhere. this increases re-use of the content and helps the organization to more easily collect the data required to drive business decisions.
information is power, and a data lake puts enterprise-wide information into the hands of many more employees to make the organization as a whole smarter, more agile, and more innovative.
searching the data lake
data lakes will have tens of thousands of tables/files and billions of records. even worse, this data is unstructured and widely varying.
in this environment, search is a necessary tool:
to find tables that you need - based on table schema and table content
to extract sub-sets of records for further processing
to work with unstructured (or unknown-structured) data sets
and most importantly, to handle analytics at scale
only search engines can perform real-time analytics at billion-record scale with reasonable cost.
search engines are the ideal tool for managing the enterprise data lake because:
search engines are easy to use–everyone knows how to use a search engine.
search engines are schema-free–schemas do not need to be pre-defined. search engines can handle records with varying schemas in the same index.
search engines naturally scale to billions of records.
search can sift through wholly unstructured content.
the state of data lake adoption
radiant advisors and unisphere research recently released the definitive guide to the data lake , a joint research project with the goal of clarifying the emerging data lake concept.
two of the high-level findings from the research were:
- data lakes are increasingly recognizable as both a viable and compelling component within a data strategy, with small and large companies continuing to adopt.
- governance and security are still top-of-mind as key challenges and success factors for the data lake.
more and more research on data lakes is becoming available as companies are taking the leap to incorporate data lakes into their overall data management strategy. it is expected that, within the next few years, data lakes will be common and will continue to mature and evolve.
using data lakes in biotech and health research – two enterprise data lake examples
 we are currently working with two world-wide biotechnology / health research firms. there are many different departments within these organizations and employees have access to many different content sources from different business systems stored all over the world. the data includes:
we are currently working with two world-wide biotechnology / health research firms. there are many different departments within these organizations and employees have access to many different content sources from different business systems stored all over the world. the data includes:
manufacturing data (batch tests, batch yields, manufacturing line sensor data, hvac and building systems data)
research data (electronic notebooks, research runs, test results, equipment data)
customer support data (tickets, responses)
public data sets (chemical structures, drug databases, mesh headings, proteins)
our projects focus on making structured and unstructured data searchable from a central data lake. the goal is to provide data access to business users in near real-time and improve visibility into the manufacturing and research processes. the enterprise data lake and big data architectures are built on cloudera, which collects and processes all the raw data in one place, and then indexes that data into a cloudera search, impala, and hbase for a unified search and analytics experience for end-users.
multiple user interfaces are being created to meet the needs of the various user communities. some will be fairly simple search uis and others will have more sophisticated user interfaces (uis), allowing for more advanced searches to be performed. some uis will integrate with highly specialized data analytics tools (e.g. genomic and clinical analytics). security requirements will be respected across uis.
being able to search and analyze their data more effectively will lead to improvements in areas such as:
drug production trends – looking for trends or drift in batches of drugs or raw materials which would indicate potential future problems (instrument calibration, raw materials quality, etc.) which should be addressed.
drug production comparisons – comparing drug production and yields across production runs, production lines, production sites, or between research and production. knowing historical data from different locations can increase size and quality of a yield. such improvements to yields have a very high return on investment.
traceability – the data lake gives users the ability to analyze all of the materials and processes (including quality assurance) throughout the manufacturing process. bio-pharma is a heavily regulated industry, so security and following industry standard practices on experiments is a critical requirement.
factors which contribute to yield – the data lake can help users take a deeper look at the end product quantity based on the material and processes used in the manufacturing process. for example, they can analyze how much product is produced based on raw material, labor, and site characteristics are taken into account. this helps make data-based decisions on how to improve yield by better controlling these characteristics (or how to save money if such controls don’t result in an appreciable increase in yield).
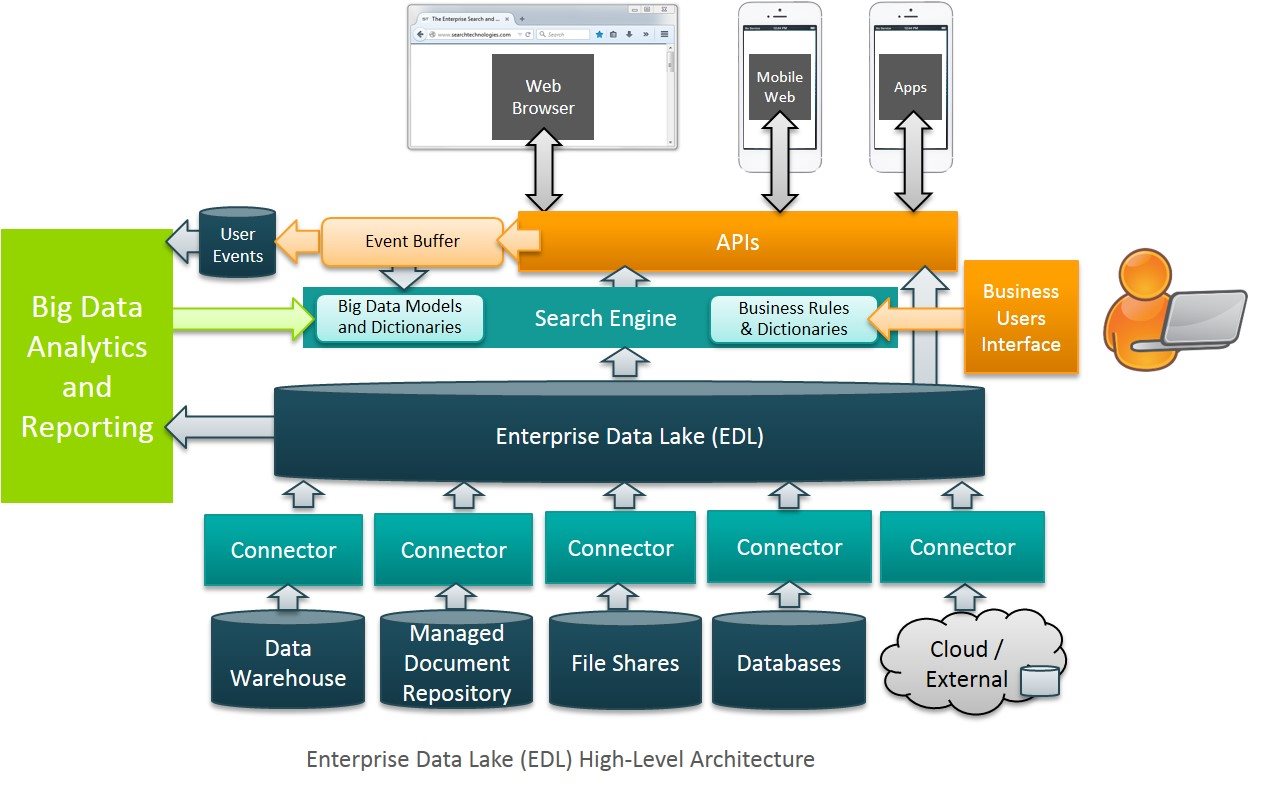
a data lake architecture
all content will be ingested into the data lake or staging repository (based on cloudera) and then searched (using a search engine such as cloudera search or elasticsearch). where necessary, content will be analyzed and results will be fed back to users via search to a multitude of uis across various platforms.
what’s on the horizon?
at this point, the enterprise data lake is a relatively immature collection of technologies, frameworks, and aspirational goals. future development will be focused on detangling this jungle into something which can be smoothly integrated with the rest of the business.
the future characteristics of a successful enterprise data lake will include:
- common, well-understood methods and apis for ingesting content
- make it easy for external systems to push content into the edl
- provide frameworks to easily configure and test connectors to pull content into the edl
corporate-wide schema management
- methods for identifying and tracking metadata fields through business systems
- so we can track that “eid” is equal to “employee_id” is equal to “csv_emp_id” and can be reliably correlated across multiple business systems
business user’s interface for content processing
- format conversion, parsing, enrichment, and denormalization (all common processes which need to be applied to data sets)
text mining
- unstructured text such as e-mails, reports, problem descriptions, research notes, etc. are often very difficult to leverage for analysis.
- we anticipate that common text mining technologies will become available to enrich and normalize these elements.
integration with document management
- the purpose of 'mining the data lake' is to produce business insights which lead to business actions.
- it is expected that these insights and actions will be written up and communicated through reports.
- therefore, a system which searches these reports as a precursor to analysis–in other words, a systematic method for checking prior research–will ultimately be incorporated into the research cycle.
we really are at the start of a long and exciting journey! we envision a platform where teams of scientists and data miners can collaboratively work with the corporation’s data to analyze and improve the business. after all, "information is power" and corporations are just now looking seriously at using data lakes to combine and leverage all of their information sources to optimize their business operations and aggressively go after markets.
this article was first published on search technologies' blog .
Published at DZone with permission of Carlos Maroto. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments