A Developer’s Introduction to the Pulsar Streaming Messaging System
Apache Pulsar is an open-source distributed pub-sub messaging system that's currently undergoing incubation. Get introduced to it here!
Join the DZone community and get the full member experience.
Join For FreeWith more and more data flowing between sources, applications, and users, messaging and streaming technology have become critical building blocks for data-driven applications. As demands on messaging and streaming systems have exploded, new technology solutions have emerged that are designed to support the resiliency, scalability, and performance requirements of these applications while providing the flexibility and manageability needed by developers and DevOps teams.
One of these new solutions is Apache Pulsar, an enterprise-grade messaging solution originally developed and deployed by Yahoo! to support major applications including Yahoo! Mail, Yahoo! Finance, Yahoo! Sports, Flickr, and the Gemini ads platform. Pulsar was released as open-source in 2016 and is now undergoing incubation within the Apache Software Foundation. Pulsar supports both publish-subscribe and queuing semantics and is designed to provide resiliency, durability, scalability, and performance, making it ideal for a broad variety of applications.
Pulsar’s key features include:
Guaranteed message delivery
Very low publish and end-to-end latency
Seamless scalability to millions of topics
Multiple subscription modes for topics (exclusive, shared, and failover)
Support for multiple delivery semantics (including at most once, at least once, and effectively once)
Support for geo-replicated clusters across datacenters
A simple client API with bindings for Java, Python, and C++
More information about Pulsar features can be found in this blog post.
Key Concepts
Pulsar is built on the publish-subscribe model (aka pub-sub) used by a number of messaging systems including Apache Kafka, RabbitMQ, ActiveMQ, and similar technologies. In this model, there are two types of application users:
Producers: Applications that publish data to Pulsar.
Consumers: Applications that receive and process data from Pulsar.
As in other pub-sub systems, the topic is the core resource in Pulsar. Loosely speaking, a topic represents a named channel into which producers push data and from which consumers pull data. Producers publish messages to topics while consumers subscribe to those topics, process incoming messages, and send an acknowledgment when processing is complete.

To support multi-tenancy, Pulsar uses the concepts of properties and namespaces. A property represents a tenant in the system. Each property could represent a team in the enterprise, a core feature, or a product line, for example. Each property, in turn, can contain several namespaces; for example, one namespace for each application or use case. A namespace can then contain any number of topics. This hierarchy is illustrated below:

Each Pulsar topic can have multiple consumers connected to it by a subscription. Once a subscription has been created, Pulsar automatically retains all messages in the topic, even if the consumer gets disconnected, until the consumer acknowledges that they’ve been successfully processed.
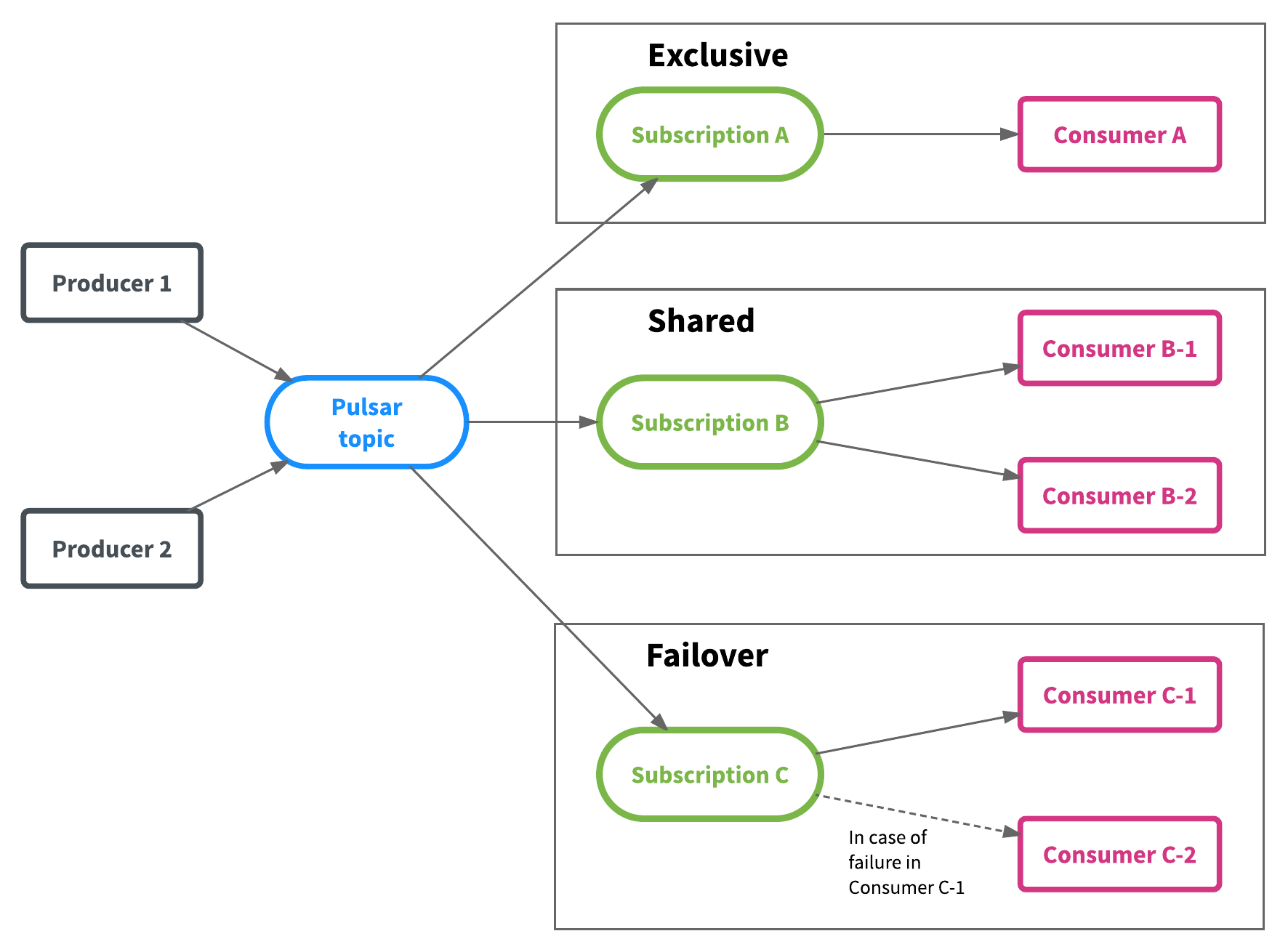
Pulsar offers three different types of subscriptions for consumers to choose from:
Exclusive: For this type of subscription, there can be only a single consumer at any given time.
Shared: In this case, multiple consumers can attach to the same subscription and each consumer will receive a fraction of the messages.
Failover: With failover subscriptions, multiple consumers are allowed to connect to a topic, but only one consumer will receive messages at any given time. The other consumers will start receiving messages only when the current receiving consumer fails.
The three different types of subscriptions are illustrated below:
Pulsar Architecture
Pulsar is a distributed, multi-tenant solution designed to ensure data durability, consistent performance, and easy scalability with minimal management. Pulsar’s architecture consists of two layers:
Message processing: Consists of one or more “brokers” that coordinate the entire system, including receiving incoming messages from producers and dispatching messages to consumers.
Storage: A distributed storage layer, built on Apache BookKeeper, consisting of one or more “bookies” that handle persistent storage of messages.

Because the message processing and storage layers can be scaled independently by adding more brokers (to scale message throughput) or bookies (to scale persistent storage), scaling a Pulsar cluster does not require redistributing data.
This scalable architecture, which also provides performance isolation between message ingestion and message distribution, ensures high performance even during high rates of message arrival and in cases with large numbers of consumers.
Data durability is ensured by the use of a persistent storage layer (avoiding data loss in the case of server failures) and by built-in geo-replication, which provides full-mesh replication among active-active Pulsar clusters located in two or more datacenters.
Getting Started With Pulsar
Applications use the Pulsar client libraries to communicate with Pulsar. These libraries (currently available for Java, C++, and Python), have a number of important built-in features to simplify development, including:
Automatic service discovery for connecting to a Pulsar instance
Transparent recovery from transient errors
Queuing of messages until acknowledged by a broker
Heuristics such as connection retries with backof
To illustrate how to develop an application using Pulsar, we’ll use a simple example of a producer that is sending event data from an augmented reality application (similar to Pokemon Go) to Pulsar for distribution to downstream applications for processing. In this example, there are two consumers: one that will process location information and another that will process information about user interactions with the application.

We’ll create this example using Pulsar’s Python client libraries.
We start by creating an instance of a Pulsar Client that is connected to a running Pulsar deployment reachable at the URL below:
client = pulsar.Client('pulsar://pulsar-instance:6650')Next, we will connect the consumers to the topic. Pulsar topics are named with URLs that have a well-defined structure of the form:
[persistence]://[property]/[cluster]/[namespace]/[topic]persistence specifies whether messages should be durably stored in BookKeeper for durability or only stored in memory on the broker for at-most-once processing. property, cluster, and namespace uniquely identify and isolate the specified topic, supporting multi-tenancy. In our example, we'll have a persistent topic using this name:
EVENTS_TOPIC = ’persistent://example/global/eventprocessor/events’Now, let’s create our producer:
producer_events = client.create_producer(EVENTS_TOPIC)Note: We do not need to explicitly create the topic — Pulsar automatically creates the topic when the producer is created if the topic does not already exist.
As our producing application collects event data, it puts that data internally in an event string and then publishes it to our Pulsar topic:
producer_locations.send(event) Now, let’s set up our consumers. We have two consumers, which will both want to see all messages in the topic. Each consumer is an independent Python process. Each consumer process first creates a client instance:
client = pulsar.Client('pulsar://pulsar-instance:6650')Next, we create our consumers and create a subscription for them to the topic they will be consuming. We create each of these as shared subscriptions.
consumer1 = client.subscribe(EVENTS_TOPIC, ‘location_subscription’, pulsar.ConsumerType.Shared)
consumer2 = client.subscribe(EVENTS_TOPIC, ‘action_subscription’, pulsar.ConsumerType.Shared)Our consumers then receive messages from their subscription, process them, and let the Pulsar broker know that that they have consumed them.
Consumer 1:
while True:
event_msg = consumer1.receive()
process_event_location(event_msg)
consumer1.acknowledge(event_msg)Consumer 2:
while True:
event_msg = consumer2.receive()
process_event_action(event_msg)
consumer2.acknowledge(event_msg)The Pulsar broker automatically tracks the position of each consumer in the message stream so that a consumer does not see messages a second time.
Now that you've seen the basics of creating a Pulsar application, what’s next? Here are some additional resources that can help you learn more and try out your own Pulsar projects:
Read more about Pulsar and how it works
Dive into the Pulsar documentation
See more Pulsar examples
Copy the Pulsar client and server code from GitHub
Opinions expressed by DZone contributors are their own.
Comments