A Disk-Based Collection in Java
Feeling constrained by your heap? Want to store more elements in a collection than your memory can hold? Check out this project designed to handle big collections.
Join the DZone community and get the full member experience.
Join For FreeThe FileBasedCollection was developed to store more elements in a collection than the memory can hold. This is not necessarily big data, but it is a technique to deal with a lot of data. Big in relation to the heap size. In Java, this threshold is easily reached because the heap size is usually limited to some level far below the actual amount of available memory. The FileBasedCollection is developed for a use case where the heap would have to be several dozens of Gigabytes. This is not a problem for 64-bit JVMs, but you can't size the heap space to exactly fit the job. The FileBasedCollection is a semi-modifiable collection with an iterator, which swaps to disk if the internal store is filled up to a certain threshold. The iterator allows the programmer to go through the data from beginning to the end. The total number of elements that can be stored is unlimited, but at some point, your hard disk will run out of space.
Use FileBasedIterator With Try-With-Resources
This example creates a FileBasedCollection with the try-with-resources syntax. The FileBasedIterator is also created with the try-with-resources syntax. First, a million integers are added to the FileBasedCollection, then the FileBasedIterator iterates over the collection and sums the values. If try-with-resources isn't used then the iterator and collection must be closed with the close() statement. It is therefore recommended to use try-with-resources.
try(FileBasedCollection<Integer> fbc = new FileBasedCollection<>()) {
for(int i = 1; i < 1000_000; i++) {
fbc.add(i);
}
long sum = 0;
try(FileBasedIterator<Integer> iter = fbc.iterator()) {
while(iter.hasNext()) {
Integer i = iter.next();
sum += i;
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("sum: " + sum);
}Methods
Add
The add() method delegates to the internal store, which is an ArrayList. The add() method of the FileBasedCollection, therefore, has the same performance characteristics as the ArrayListís add() method. If the chunkSize threshold is reached, the internal store will be flushed to disk. An extra feature of the FileBasedCollection is to add elements and assign a weight which counts for calculating the threshold. The interface method add(E e) assigns a weight of 1. The method add(E e, int size) can be used to specify the size of the element. This is useful if objects of different sizes are added and you don't want to treat every element the same. It is important to note that the chunkSize keeps track of the number of elements, or of the size of the element as provided by the programmer. This feature has proved to be very useful when dealing with elements with very different sizes. In our usage scenario, we were able to improve throughput and keep the memory footprint constant, even with varying inputs which would otherwise lead to OutOfMemoryExceptions because the amount of data would suddenly be much higher than expected.
Contains
The contains() method is basically the same implementation as the contains() method from the abstract base class AbstractCollection. The most notable difference is that the FileBasedCollection's implementation of contains() uses the FileBasedIterator. The FileBasedIterator is backed by a file, performs IO, and is auto-closeable. The FileBasedIterator must be closed, otherwise, the InputStream will not be closed and a resource leak will occur.
AddAll
The addAll() method delegates to the AbstractCollection for all collections, except if the programmer adds one FileBasedCollection to another. The implementation is different because the FileBasedIterator needs to be closed. An IOException while reading from the FileBasedCollection to add will lead to a RuntimeException. The FileBasedCollection tries to clean up resources in this case but it can't be guaranteed that the backing file will be deleted. The addAll method is efficient because it adds elements to the internal ArrayList, and flushes to disk when the list is full. The performance is thus O(n) in relation to the size of the internal store, which is determined by the chunkSize plus a fixed cost for flushing to disk.
RemoveAll and RetainAll
These two methods share the same semantics, they are each otherís mirror image so to say. They delegate to the same private method. The difference is that removeAll retains the elements that are not in the collection to remove. The retainAll method retains all elements from the collection to retain. The internal private retainAll operation to which removeAll and retainAll delegate are implemented as a copy operation. A new FileBasedCollection is created with the elements to retain. The internal Store of the FileBasedCollection is then replaced with the new Store and all resources are cleaned up.
This method performs a contains() call on the collection to remove or retain for each element in the base collection. The add() call is negligible because add() is performed on the internal ArrayList. For large FileBasedCollection, in relation to the chunkSize, the size of the internal collection is vanishingly small. The performance is thus O(n^2).
Close
The FileBasedCollection implements Closeable. This means that the FileBasedCollecton is auto-closeable. Using the FileBasedCollection safely and responsibly is thus made easy. A shutDownHook is available as last resort to clean up resources, but it is the responsibility of the developer to clean up the FileBasedCollection when it is not needed anymore. Calling this method closes all resources and deletes the backing file.
Flush
The flush() method writes the current chunk to disk and creates a new empty chunk. This method could interfere with other operations, such as add(). The FileBasedCollection is not thread-safe so calling this method must be done with care.
Clear
The clear() method overrides the clear() method from the AbstractCollection. A new FileBasedCollection is created and the Stores are swapped and all resources are cleaned up thereby emptying the FileBasedCollection.
GetChunkSize
This method returns the chunkSize that is used by this FileBasedCollection. The default chunkSize is set to 100. A custom chunkSize can be set with a constructor.
Size and GetRealSize
The size() method overrides the size() method from the AbstractCollection. The size of the FileBasedCollection is only limited by the size of the hard disk. It is important to note that size() returns an integer. The real size of the collection is kept in a long field. The size() method downcasts the real size to an integer. For large collections, this means that the size() method may return incorrect results.
The getRealSize returns the actual size as a long value. This reports up to 2^63 -1 elements and that should be enough for most use cases. In theory, the FileBasedCollection can grow beyond this amount. The size methods will not return reliable results in that case.
Iterator
The iterator() method returns a FileBasedIterator, which is auto-closable. The FileBasedIterator uses a Store with a File. The InpuStream needs to be closed otherwise it is not possible to delete the backing file when closing the FileBasedCollection by hand or through the shutDownHook. It is recommended to use the FileBasedIterator with the try-with-resources syntax, for example:
try(FileBasedIterator iter = iterator()) {
while(iter.hasNext()) {
E next = iter.next();
}
}Multiple iterators can be open at the same time. The implementation is not thread-safe, nor are any guards present against concurrent access.
The FileBasedIterator is surprisingly fast. When a new chunk is loaded, the iterator actually only iterates over the internal ArrayList. Iterating thus has a cost for loading the next chunk and then a cost for iterating over an ArrayList. The cost is thus a function of the number of elements in the internal store, which may be small in comparison to large FileBasedCollections. The iterator runs in O(n) in relation to the size of the FileBasedCollection.
Sort and Sort(int)
The FileBasedCollection is sortable. An internal class, the FileBasedCollectionSorter uses a merge sort algorithm for external sorting, see https://en.wikipedia.org/wiki/External_sorting. The sort() method has two varieties: one with a default bucket size of 10, and one with a custom bucket size. First, elements are stored in buckets of the specified size, then the buckets are sorted. The merge phase merges the heads of the buckets and sorts the list of heads by taking the minimum value of the list of heads. The resulting collection is sorted according to the internal logic of the elements. The elements of the FileBasedCollection must implement Comparable.
Unsupported Operations
Remove
The remove() method is unsupported because the FileBasedCollection doesn't support random access. The removeAll() method can be used instead, but removeAll is a rather heavy operation that doesn't scale well.
ToArray
The toArray methods aren't supported because they require that all elements are in memory at once, which defies the purpose of the FileBasedCollection.
Implementation
AbstractCollection
Modifiable Collection
According to the documentation of the AbstractCollection: To implement a modifiable collection, the programmer must additionally override this class's add method (which otherwise throws an UnsupportedOperationException), and the iterator returned by the iterator method must additionally implement its remove method.
The FileBasedCollection is thus not modifiable in the sense that the AbstractCollection describes because the remove operation isn't supported. The next and hasNext methods are supported as well as the size method.
Constructor
A copy constructor is not provided. A void no-argument constructor is available. The default constructor uses a default value for the chunk size of 100.
Store and Snappy
The internal Store class uses a regular Java File object and a SnappyOutputStream to compress the data. The default Java serializer is used. The backing file is created in the java.io.tmpdir location. The file is named FileBasedCollection, appended with a UUID and the .bin extension. The file will usually be in a temporary directory on the system. The FileBasedColection provides several methods to make resource management easy. A shutDownHook is added to try to clean up any left-over resources. If the process fails, then resources can't be cleaned up and it is possible that the hard disk overflows at some point.
Resource leakage with implicit Iterators
A Java for-loop implicitly opens an iterator, but doesn't close it, because normally, iterators don't implement Closable. The FileBasedIterator is Closable and must be closed, otherwise, the InpuStream will not be closed and the backing file can't be removed. Using any construct with an implicit iterator will thus lead to resource leakage. The Java 8 methods, such as forEach and streams, are supported but be warned that at some point, your hard disk will be full. It is left to the developer to decide whether to use these methods or not. If possible, you can always clean up afterwards.
The FileBasedCollection's Backing File and Memory Consumption
The FileBasedCollection is backed by a file and flushes to disk if the internal store is full. The size of a FileBasedCollection is therefore in principle only limited by the size of the hard disk.
In the following example, a FileBasedCollection is filled with Long values. After each million new values, the disk size in bytes was computed. As you can see, the backing file was over a gigabyte large, while the heap remained very modest at around 50 Mb.
Heap usage after 200 million Longs were added: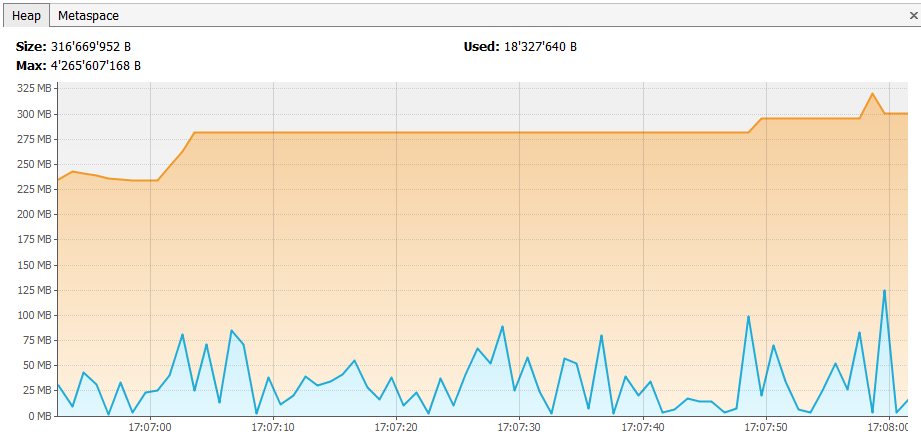
The available disk size decreases proportionally to the number of elements added to the FileBasedCollection. This is expected as the collection, and thus the backing file, grows, the disk will be filled. During testing, I encountered out of disk space issues regularly!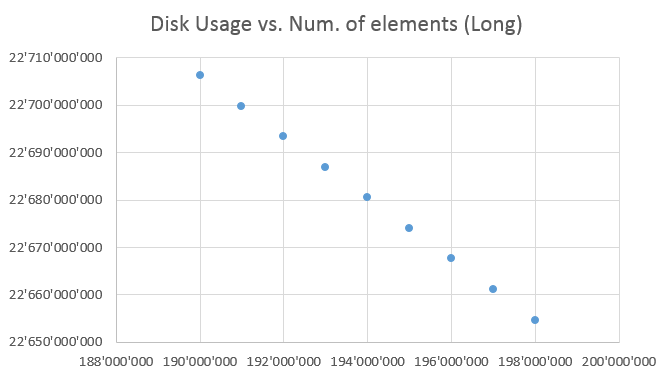
Conclusion
I hope that for some, the FileBasedCollection is just what they've been looking for to solve their big data problems. The source code is available here.
Opinions expressed by DZone contributors are their own.
Comments