A Pattern for Intelligent Ticket Routing in ITSM
Manual ticket routing is a hidden tax on IT efficiency. Here is an architectural pattern for using Logistic Regression and Skype status APIs to automate this.
Join the DZone community and get the full member experience.
Join For FreeIn the world of IT Service Management (ITSM), the Service Desk often acts as a human router. A ticket comes in, a coordinator reads it, checks a spreadsheet to see who is on shift, remembers who is good at databases versus networking, and then assigns the ticket.
This process is slow, subjective, and prone to cherry-picking (where engineers grab easy tickets and ignore hard ones). It creates a bottleneck that increases Mean Time to Resolution (MTTR).
This article explores a solution architecture pattern that combines Machine Learning (ML) for competency analysis with real-time availability checks to automate ticket assignment with high precision.
The Problem: The Coordinator Bottleneck
The decision to assign a ticket involves multiple variables:
- Technical context: Is this a database issue or a network issue?
- Competency: Which engineer has the skills to fix it?
- Availability: Is that engineer online, at lunch, or overloaded?
Traditional rule-based automation fails here. Rules can route by category (e.g., “All DB tickets go to the DB Team”), but they cannot determine which specific human is best suited to resolve a vague error message at 2:00 PM on a Tuesday.
The Solution Architecture
The AIC solution effectively replaces the human dispatcher with two integrated modules: a Machine Learning Core (for understanding the ticket) and a Workload Calculation Module (for understanding the workforce).
The system is hosted as a SaaS-style internal service that interacts with the ITSM tool (such as ServiceNow) via API.
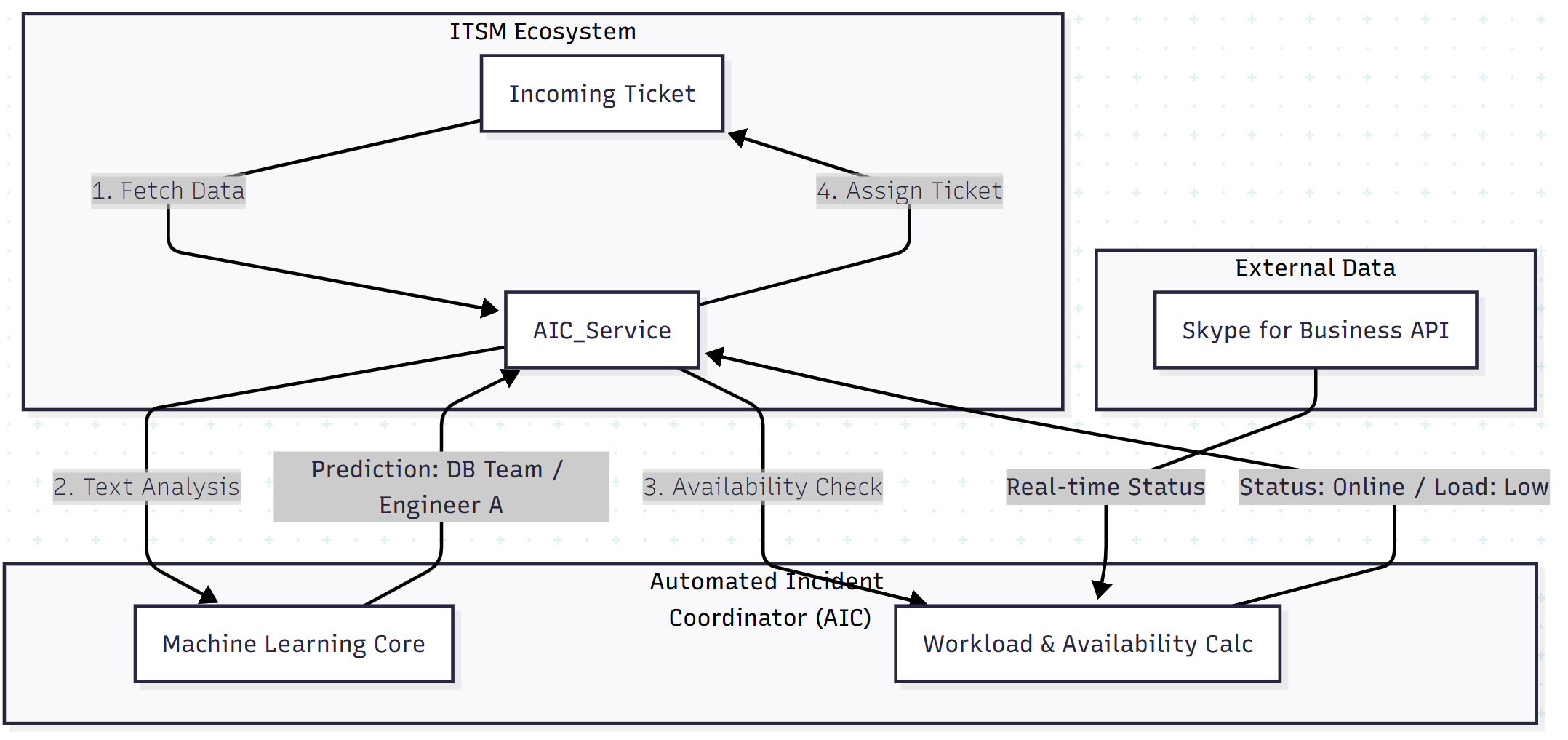
Module 1: The Machine Learning Core (The “Brain”)
This module determines who can solve the ticket based on historical data. It uses a Logistic Regression algorithm from the scikit-learn library.
Data Preparation Pipeline:
- Input: Historical ticket data (subject, description, resolution notes) from the last 1–2 years
- Normalization: Convert text to lowercase and remove stop words (e.g., “the,” “and”)
- Vectorization: Use TF-IDF (Term Frequency–Inverse Document Frequency) to convert text into numerical vectors that the algorithm can understand
- Training: The model learns which engineers historically resolved which types of tickets
Why Logistic Regression?
While deep learning is popular, Logistic Regression is lightweight, interpretable, and requires less training data. For text classification tasks like “Assign this ticket to Team A or Team B,” it offers an excellent balance of accuracy and speed.
Module 2: Workload & Availability Calculation (The “Scheduler”)
Knowing who can fix it isn’t enough; you also need to know who is available. This module (WAC) introduces real-time context.
- Availability: It queries the Skype for Business API (or Teams/Slack APIs) to check presence status. If the ML model selects “Engineer Bob” but Bob is marked as “Away,” the system moves to the next best candidate.
- Workload balancing: It tracks the number of open tickets per engineer and uses a Normal Harmonical Distribution to ensure tickets are spread evenly, preventing burnout among top performers.
The Feedback Loop: Auto-Retraining
Static models decay over time. New error messages appear, and teams change. To address this, the system implements an auto-retraining pipeline.
Every night, the system:
- Downloads the day’s closed tickets
- Compares its initial prediction with the actual resolver
- Retrains the model using this new ground truth
This ensures the AI adapts to organizational changes (for example, new hires joining the team) without manual reconfiguration.
Implementation Details
The solution was built using a Python-centric stack, chosen for its rich data science ecosystem.
- Language: Python
- Libraries: Pandas (data processing), scikit-learn (ML algorithms), NumPy (math)
- Integration: REST API calls to the ITSM platform (e.g., ServiceNow Table API)
- Security: A dedicated service account processes sensitive data within the secure perimeter, ensuring GDPR compliance
Sample Python Logic (Conceptual):
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
# 1. Load Data
tickets = load_ticket_data() # Pandas DataFrame
# 2. Vectorize Description
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(tickets['description'])
y = tickets['resolver_group']
# 3. Train Model
model = LogisticRegression()
model.fit(X, y)
# 4. Predict New Ticket
new_ticket_desc = ["Database connection failed on server DB-01"]
new_X = vectorizer.transform(new_ticket_desc)
prediction = model.predict(new_X)
print(f"Assign to: {prediction[0]}")Results and ROI
Deploying this pattern in a real-world data center services environment yielded significant benefits:
- Speed: The cycle from ticket creation to assignment dropped to three minutes
- Efficiency: Manual routing effort was effectively eliminated, freeing coordinators for technical work
- Fairness: The workload module ensured uniform ticket distribution, reducing cherry-picking
- Accuracy: The auto-retraining mechanism allowed the model to maintain high accuracy even as the infrastructure evolved
Conclusion
Automation in ITSM is no longer just about scripts — it’s about decision support. By combining the probabilistic power of machine learning with the deterministic data from presence APIs, organizations can build automated coordinators that are faster, fairer, and more reliable than human dispatchers.
For organizations looking to introduce AI incrementally, ticket routing is a high-value, low-risk starting point. The data already exists in ticket histories — you just need to put it to work.
Opinions expressed by DZone contributors are their own.
Comments