Contract-Driven ML: The Missing Link to Trustworthy Machine Learning
Model accuracy means nothing if data breaks in production. Learn how data contracts ensure reliability, prevent silent failures, and protect ML performance.
Join the DZone community and get the full member experience.
Join For FreeIn the age of machine learning and AI-driven decision-making, model accuracy is often touted as the holy grail. Teams boast of hitting 95%+ F1 scores or outshining baselines by double digits. However, high accuracy in development environments means very little if the model is fed garbage in production. That’s where data contracts come in: the unsung hero of reliable, scalable machine learning systems.
Without robust data quality, schema validation, and pipeline reliability, even the most accurate model is nothing more than a fragile sandbox experiment. In this article, we’ll explore the critical role of data contracts in ML systems, why accuracy metrics can be deceptive, and how enforcing contracts can save your models from silent failure in production.
The Mirage of High Accuracy
It’s easy to become enamored by metrics like AUC, precision, recall, and RMSE during experimentation. But here’s the trap: your model accuracy is only as valid as the data it was trained and is being served on. High scores during offline evaluation are based on static, curated datasets, not on the dynamic, often messy nature of real-world data pipelines.
Let explore a real-world scenario:
Imagine a fraud detection model trained on financial transactions with a transaction_amount field. If, in production, that field starts arriving as a string instead of a float (e.g., "1,000.00" instead of 1000.0), your model may:
- Fail to parse values
- Produce NaNs or defaults
- Continue serving predictions that are now fundamentally misinformed
Yet the system might not crash, and your dashboards may still show high accuracy, until someone audits the decisions and realizes the model has been making erroneous predictions for months.
This type of silent failure is preventable, with data contracts.
What Is a Data Contract?
A data contract is a formal agreement between producers and consumers of data. It defines the schema, semantics, validity constraints, and guarantees for the data being exchanged.
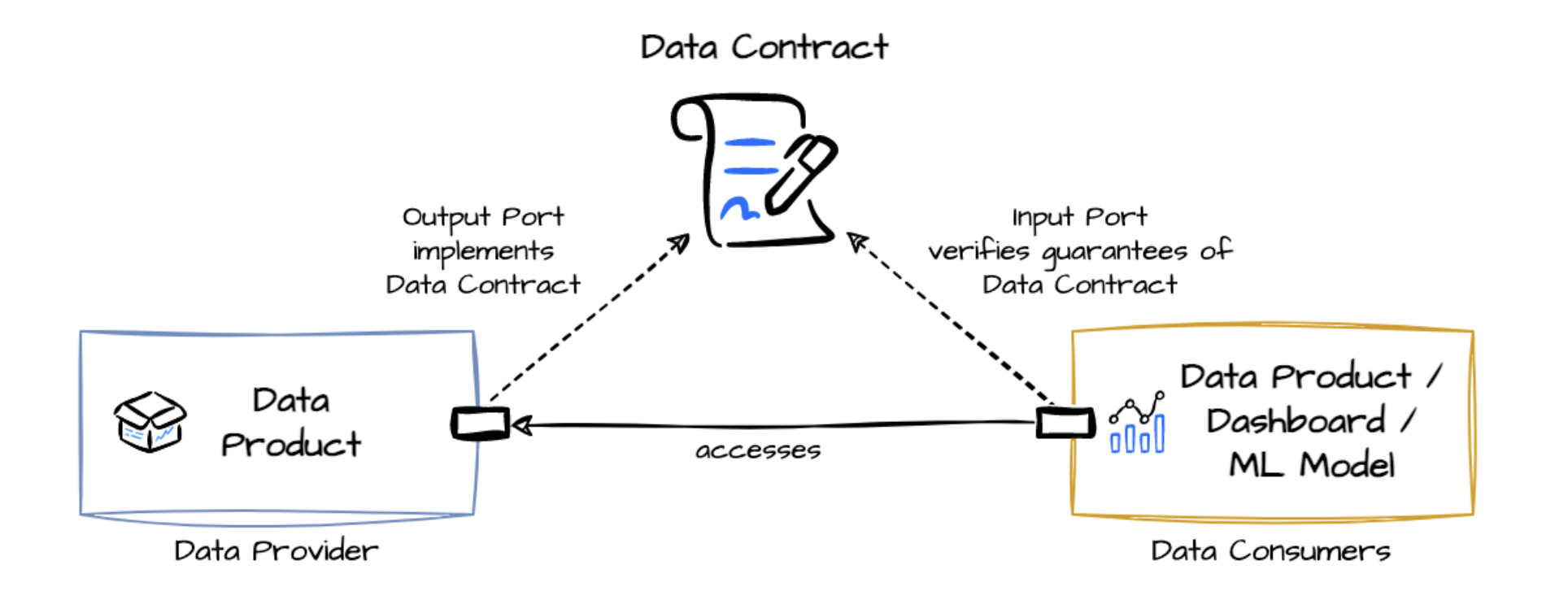
Data contracts align producers and consumers with clear expectations.
Key Components of a Data Contract:
- Schema: Data types, required/optional fields, naming conventions.
- Validations: Value ranges, enum constraints, timestamp formats.
- Semantics: What each field represents and how it should be interpreted.
- Change Management: Versioning rules and backward compatibility guarantees.
By codifying these elements, data contracts enforce trust boundaries in a pipeline, ensuring that upstream changes don’t silently break downstream consumers like ML models.
Why Data Quality > Model Accuracy
Your model doesn’t understand the world. It only understands the data it’s fed. Without a mechanism to ensure that input data retains its integrity and structure, your model is essentially blindfolded.
The Cost of Low Data Quality
According to a 2020 study by MIT Sloan, poor data quality costs the U.S. economy over $3 trillion annually. For ML systems, consequences include:
- Incorrect predictions
- Loss of user trust
- Compliance violations (e.g., due to PII leaks or missing fields)
- Drift in production performance
High model accuracy on bad data is worse than a low-accuracy model on clean data because it creates a false sense of reliability.
Schema Validation: Your First Line of Defense
One of the most critical features of data contracts is schema validation. It ensures that the structure of data being sent aligns with what your model or pipeline expects.
Example:
If your model expects:
{
"user_id": "string",
"age": "int",
"signup_date": "datetime"
}And suddenly age becomes a float, or signup_date is in ISO string format instead of epoch time, schema validation will fail fast. Without contracts, these inconsistencies may pass through, corrupt feature values, and degrade model performance over time.
Tools for Schema Validation:
- Great Expectations
- Pydantic / Marshmallow (Python)
- Protocol Buffers / Avro / JSON Schema
- Datafold for testing pipeline diffs
Pipeline Reliability and Change Propagation
Machine learning pipelines aren’t just code, they’re dataflows. Data from different teams, sources, APIs, and formats flow into a common pipeline and eventually feed into your models.
Without Contracts:
- A change in upstream format can silently break your downstream pipeline.
- Dev teams may deploy a new version of the event stream without realizing it breaks models.
- Bugs go unnoticed because failures are not explicit.
With Contracts:
- Upstream teams are required to version and validate changes.
- CI/CD can enforce schema checks.
- Pipeline failures are surfaced early, often during development, not post-deployment.
Data contracts create a culture of accountability, where data quality is everyone's job, not just the data science team’s problem.
Detecting and Mitigating Data Drift
While schema validation protects against structural changes, semantic drift is another silent killer. For example:
- A gender field suddenly starts accepting new values like "non-binary" or "undisclosed"
user_activity_scoreis redefined to a new formula without documentation
Without contracts or metadata management, semantic shifts in data, like a field changing meaning or usage, often go unnoticed, yet they can drastically degrade model performance. Data contracts address this by enforcing consistent metadata and thorough documentation, ensuring that everyone understands what each field represents. They also help track the evolution of field meanings over time, preventing silent changes from impacting downstream consumers. Additionally, contracts support logging and monitoring of value distributions, enabling early detection of data drift before it undermines model accuracy or reliability.
Real-World Case Studies of Failure
The consequences of ignoring data contracts can be severe:
- Airbnb once faced model degradation due to a feature value being inadvertently bucketed differently after a schema change.
- Netflix emphasizes “data contracts” in their ML platform to manage schema evolution across hundreds of teams.
- A large fintech company suffered a $3M trading error due to a decimal-to-integer conversion bug in input data, undetected because no validation was in place.
What changed wasn’t the model, but the data it was exposed to. This disconnect illustrates why model accuracy is meaningless in isolation.
Integrating Data Contracts in ML Lifecycle
The future of reliable machine learning lies in the evolution toward contract-driven ML, an approach that brings the same discipline and structure to data systems that software engineering has long enjoyed. In this paradigm, data contracts are not just a formality but an integral part of the ML lifecycle. For instance, contract-aware feature stores are emerging as a foundational element, ensuring that all ingested features comply with pre-defined schema and semantic rules. These contracts act as gatekeepers, preventing invalid data from polluting training or prediction workflows. Similarly, the concept of CI/CD for data is gaining traction. Just as code undergoes automated testing and validation before deployment, data pipelines now include rigorous quality checks, schema validations, and approval steps to catch issues early and avoid silent failures in production. Most importantly, this transformation encourages cross-functional collaboration. Data engineers, scientists, and product owners must work together to define, maintain, and evolve data contracts, ensuring that everyone has a shared understanding of what each dataset represents and how it should behave. This cultural shift echoes the maturation of software development, from the chaotic, unregulated early days to today’s structured, type-safe, and test-driven practices. It is time for data systems to embrace the same rigor, turning unreliable, ad hoc pipelines into robust, contract-governed ecosystems.
Here’s how data contracts integrate into the modern ML lifecycle:
- Model Design:
- Define expected schema and constraints for input features.
- Collaborate with data engineers to define contracts.
- Development:
- Simulate schema validation in local/CI tests.
- Use synthetic data that adheres to the contract.
- Deployment:
- Validate incoming data against the contract before inference.
- Log schema violations or anomalies.
- Monitoring:
- Continuously check for schema drift, missing fields, or unexpected distributions.
- Set up alerts when contracts are violated.
- Evolution:
- Update contracts with versioning.
- Ensure backward compatibility where possible.
Conclusion: Your Model’s Worst Enemy Is Assumed Data
Accuracy metrics look great in a vacuum. But in the wild, your model is at the mercy of data it receives. Without enforcing strict contracts, you’re effectively hoping nothing breaks, a risky gamble in production systems. Data contracts bring structure, reliability, and trust to your ML pipelines. They turn assumptions into enforceable rules. They empower both data producers and consumers to communicate clearly, track changes, and ensure that models always see data in the format they were designed to consume.
So next time your team hits 98% accuracy, ask this: Can we trust our data flow? Because without data contracts, accuracy is just a comforting illusion.
Disclaimer: The views presented in this article are the views of the author and do not necessarily reflect the views of the authors' employers or their member firms.
Opinions expressed by DZone contributors are their own.
Comments