A Serverless Sequence Diagram
Serverless is fast becoming very common in the world of APIs and web applications. Take a look at a diagram that lays out how a typical serverless interaction might occur.
Join the DZone community and get the full member experience.
Join For FreeI thought I’d put a diagram together that shows some of the ways I think about the general serverless facility and a key difference from the old world of application composition and deployment. Two-time former colleague, Mike Roberts, knows serverless stuff way better than me, and hopefully, I’m doing a fair job here of showing an alternate diagrammatic description of one piece of it:
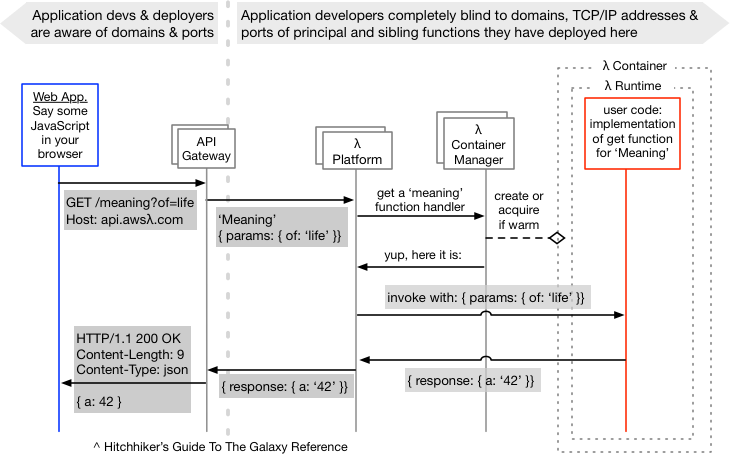
Ports, Processes and All That
The key (to me) is the fact that the functions deployed to the serverless infra don’t have domain names (even internal ones), nor TCP/IP addresses, nor listen on ports. At least for us, as the users of this system, that is true — all routing is by a logical name alone. If my serverless function needed zipCodeService, then that’s all it would need to know before being able to invoke it (as well as a platform-provided API for lookup).
This design is so smooth that it’s easy to have wholly separated (shared nothing) environments that are easy to define the daily cost for. This would include per-developer environments and plenty for the CI-controlled automation that high-throughput dev teams rely on.
Ephemeral environments are even possible, as it matters far less with serverless whether the environment is “up” (by some definition) and yet not used. There are charges for use of serverless, but they are fine-grained and traceable to each environment’s functional handlers that did the servicing so that you know where your dollars are going each week.
Back to named dependencies, which are sibling deployments in the serverless infra: There’s no notion of services that would be named to include the environment. So you’d not see a zipCodeService_QA1 function. Your functions that would need that service look it up by a canonical name (zipCodeService), as it could not use one from an adjacent env for the same application — as they’re invisible.
There’s no need to think of that as a side-firewall constrained capability (although it may be, too) because there’s no notion of sockets to the developer/deployer. Functions in a serverless infrastructure don’t have them. Well, there are sockets involved if you’re calling out to the likes of https://api.github.com for some purpose, but that’s a different thing and subject to its own best practice/worst practice considerations.
Key Advances for Our Industry
This stuff and the abandonment of names:ports in the config is a key advancement for our industry. It is like a limiting Unix problem has been overcome. While it is still is impossible for two processes on one server to listen on the same port (say port 443), it is now not important, as we have a mechanism for efficiently stitching together components (functions) of an application together via the simplest thing — a name. A name that is totally open for my naming creativity (ports were restricted if they were numbered below 1024 and also tied to specific purposes).
We’re also relieved of the problem of having to think of processes now, and whether they’ve crashed and won’t be receiving requests anymore. Here’s a really great, but rambling, rant on a bunch of related topics by Smash Company that you should read, too, as it touches on some of the same things but goes much broader.
Notes on the Diagram
In the diagram above, I’ve not shown any Backend as a Service (BaaS) pieces for this “meaning of life” invocation, but rather functions as a service (FaaS), which are very much part of the “serverless” proposition.
Also not shown in the diagram are some things in the serverless infra itself (right of the vertical dotted line):
- The use of a store during Container Manager’s lookup and instantiation of function handlers.
- The purging of function handler instances/containers on any basis.
- Caching at any level.
- Perhaps even the immense scale potential for the hosting infra itself and the apps within it.
Published at DZone with permission of Paul Hammant. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments