A Sub-Query Does Not Hurt Performance
Just because it's on the Internet, does it make it necessarily true? What about the case of sub-queries affecting database performance? Read on to find out the truth.
Join the DZone community and get the full member experience.
Join For Freeoh, the things you read on the internet. for example, “don’t use a sub-query because that hurts performance.”
truly?
where do people get these things?
let’s test it
i’ve written before about the concept of cargo cult data professionals . they see one issue, one time, and consequently extrapolate that to all issues, all the time. it’s the best explanation i have for why someone would suggest that a sub-query is flat out wrong and will hurt performance.
let me put a caveat up front (which i will reiterate in the conclusion, just so we’re clear), there’s nothing magically good about sub-queries just like there is nothing magically evil about sub-queries. you can absolutely write a sub-query that performs horribly, does horrible things, runs badly, and therefore absolutely screws up your system. just as you can with any kind of query. i am addressing the bad advice that a sub-query is to be avoided because they will inherently lead to poor performance.
let’s start with a simple test, just to validate the concept of how a sub-query performs within sql server:
select sd.orderqty,
pr.name
from
(select *
from sales.salesorderdetail as sod
) as sd
join
(select *
from production.product as p
) as pr
on pr.productid = sd.productid
where sd.salesorderid = 52777;
select sod.orderqty,
p.name
from sales.salesorderdetail as sod
join production.product as p
on p.productid = sod.productid
where sod.salesorderid = 52777;if there is something inherently wrong with a sub-query, then there is something twice as wrong with two sub-queries. here are the resulting execution plans:

huh. looks sort of, i don’t know, almost identical. let’s compare the plans using the new ssms plan comparison utility:
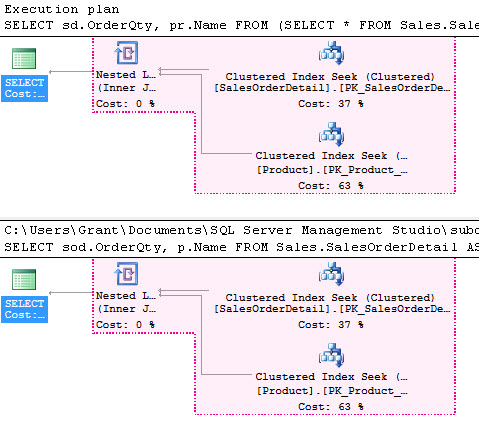
well, darn. displayed in pink are the common sets of operations between the two plans. in other words, for these plans, everything except the properties of the select operator are exactly the same. let’s take a look at those properties:

ok. now we have some interesting differences and some especially interesting similarities. let’s start with the similarities. first of all, we have exactly the same queryplanhash value in both plans. in addition, we also have identical estimated rows and costs. in short, the optimizer created two identical execution plans. now, this is where things get a little bit interesting. see, the optimizer actually worked a little harder to create the first plan than the second. it took an extra tic on the cpu and just a little more compilememory and compiletime. interesting.
what about execution times? with a few runs on average, the execution times were identical at about 149mc with 11 reads. however, running a query once or twice isn’t testing. let’s get a few thousand runs of both queries. the average results from the extended events sql_batch_completed event were 75.9 microseconds for both queries.
however, what about that extra little bit of compile time in the query that used sub-queries? let’s add in a statement to free the procedure cache on each run and retry the queries. there is a measurable difference now:
| query | duration |
| sub-query | avg: 5790.20864172835 |
| query | avg: 4539.49289857972 |
more work is done by the optimizer on the sub-query to compile the same execution plan. we’re adding work to the optimizer, requiring it to unpack the, admittedly, silly query written above. when we refer only to the compile time and not the execution time, there is a performance hit. once the query is compiled, the performance is identical. whether or not you get a performance hit from a sub-query then, in part, depends on the degree to which you’re experiencing compiles or recompiles. without the recompile, there is no performance hit. at least in this example.
let’s test it again, harder
i firmly believe in the old adage; if you ain’t cheatin’, you ain’t fightin’. it’s time to put the boot in.
let’s go with much more interesting queries that are more likely to be written than the silly example above. let’s assume some versioned data like in this article on simple-talk . we could express a query to bring back a single version of one of the documents in one of three ways from the article. we’re just going to mess with two of them. one that uses a sub-query, and one that does not:
--no sub-query
select top 1 d.documentname,
d.documentid,
v.versiondescription,
v.versionid,
row_number() over (order by v.versionid desc) as rownum
from dbo.document d
join dbo.version v
on d.documentid = v.documentid
where d.documentid = 9729;
--sub-query
select d.[documentname],
d.[documentid],
v.[versiondescription],
v.[versionid]
from dbo.[document] d
cross apply (select top (1)
v2.versionid,
v2.versiondescription
from dbo.[version] v2
where v2.documentid = d.documentid
order by v2.documentid,
v2.versionid desc
) v
where d.[documentid] = 9729;as per usual, we can run these once and compare results, but that’s not really meaningful. we’ll run them thousands of times. also, to be sure we’re comparing apples to apples, we’ll force a recompile on every run, just like in the first set of tests. the results this time:
| query | duration |
| sub-query | avg: 1852.14114114114 |
| query | avg: 2022.62162162162 |
you’ll note that, even with the compile on each execution, the query using a sub-query actually out-performed the query that was not using a sub-query. the results are even more dramatic when we take away the compile time:
| query | duration |
| sub-query | avg: 50.8368368368368 |
| query | avg: 63.3103103103103 |
we can also look to the execution plans to get an understanding of how these queries are being resolved:
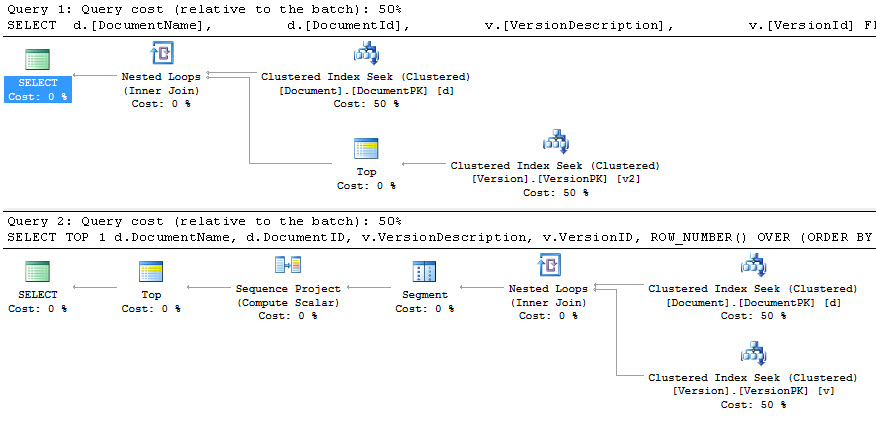
the plan on top is the sub-query plan, and the plan on the bottom is the plan for just the plain query. you can see that the regular query is doing a lot more work to arrive at an identical set of data. the differences are visible in the average execution time, about a 20% improvement.
you could argue that we’re comparing two completely different queries, but that’s not true. both queries return exactly the same result set. it just so happens that the query using the sub-query performs better overall in this instance. in short, there’s no reason to be scared of using a sub-query.
sub-query conclusion
is it possible for you to write horrid code inside of a sub-query that seriously negatively impacts performance? yes. absolutely. i’m not arguing that you can’t screw up your system with poor coding practices. you absolutely can. the query optimization process within sql server deals well with common coding practices. therefore, the queries you write can be fairly sophisticated before, by nature of that sophistication, you begin to get serious performance degradation.
you need to have a method of validation for some of what you read on the internet. people should provide both the queries they are testing with and the numbers that their tests showed. if you’re just seeing completely unsupported, wildly egregious statements, they’re probably not true.
in conclusion, it’s safe to use sub-queries. just be careful with them.
Published at DZone with permission of Grant Fritchey. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments