How To Select the Right Vector Database for Your Enterprise GENERATIVE-AI Stack
We will explore the framework for choosing the correct Vector Database in an enterprise for building a GENERATIVE AI-based application.
Join the DZone community and get the full member experience.
Join For FreeDue to the surge in large language model adoption in the Enterprises, GENERATIVE AI has opened a new pathway to unlock the various business potentials and use cases. One of the main architectural building block for GENERATIVE AI is the semantic search powered by the Vector database. Semantic search, as the name suggests is, essentially involves a "nearest neighbor" (A-NN or k-NN) search within a collection of vectors accompanied by metadata. This system having an index to find the nearest vector data in the vector storage is called Vector Database where query results are based on the relevancy of the query and not the exact match. This technique is widely used in the popular RAG (Retrieval Augmented Generation) pattern where the a similarity search is performed in the Vector database based on the user's input query, and the similar results or relevant information is augmented to the input of an Large Language Model so that the LLM doesn't hallucinate for a query outside of its knowledge boundary to generate an unique response for the user. This popular GENERATIVE AI based pattern called, RAG can't be implemented without the support of Vector database as one of the main core component in the architecture. Because of more and more increase in GENERATIVE-AI use cases, as an engineer working on transitioning an LLM-based prototype to production, it is extremely crucial to identify the right vector database during early stage of development.
During the proof-of-concept phase, the choice of database may not be a critical concern for the engineering team. However, the entire perspective changes a lot as the team progresses toward the production phases. The volume of Embedding/vectors data can expand significantly as well as the requirement to integrate the security and compliance within the app. This requires a thoughtful considerations such as access control and data preservation in case of server failures. In this article we will explain a framework and evaluation parameters which should be considered while making the right selection of the Enterprise grade Vector database for the GENERATIVE-AI based use case considering both the Developer Experience as well as the technological experience combining into the Enterprise experience. We also need to keep in mind that numerous vector db products are available in the markets with closed or open source offering and, each catering to a specific use case, and no single solution fits all use cases. Therefore, it's essential to focus on the key aspects when deciding the most suitable option for your GENERATIVE AI based application.
What Is Vector Database and Why It Is Needed?
First we need to understand what is Vector or Embedding. Vector or Embedding represents the mathematical representation of the digital data such as texts, images, or multimedia content like audio or video having numerous dimensions. These embedding relates to the semantic meaning and proximity relationships among the represented data. The more dimensions are there the more accurately the data would convey the relatedness or similarity. When a search is done in the vector space it converts the input query in natural language into Vector Embedding and then it is used to identify the related vectors using the similarity algorithms that link vectors with the shortest distance between them. This feature in the database is really useful while building AI applications or designing recommendation engines or classifier application. The similarity search using Vector database is very useful for storing vectorized private domain data for an organization which can be augmented while building the GENERATIVE-AI products or adding GEN-AI feature in the existing application such as building content summarization, recommended content generation, document question & answering system, data classification engine.
As we know that, the traditional RDBMS or NoSQL databases struggle with storing vector data that has a significant number of dimensions along with other data types, and they face scalability challenges. Also, these databases only return results when the input query precisely matches with the stored data, whereas the purpose of Vector database is to provide results based on similarity or relevancy and not just exact match. Vector database uses various algorithms like N-th Nearest Neighbor (N-NN) or Approximate Nearest Neighbor (ANN) to index and retrieve related data with the shortest distance among them. So we can see that we still need the traditional database for building a secure ACID compliant transactional system. Still, the Vector database solves the puzzle when we look for some niche feature while building the GENERATIVE AI-based applications focusing on augmenting private business data or, classification of similar data from the cluster of nonrelated data or creating a user-friendly recommendation engine.
Framework for Choosing the Right Vector Database for Enterprise AI Application
Every project will have different requirements, and it is difficult to have only one solution that can fit all the requirements. As it’s impossible to list them all, we’ll use a framework to look at a few areas important not only for prototype building in the development phase but for the production of AI applications in general.
Our framework, as depicted in the image below, consists of two categories:
- Technology Experience that focuses on Enterprise based technical aspects of the database that can support the entire Enterprise AI apps in the longer period of time with strong security in place.
- Development Experience focuses on the seamless development experience for the Enterprise engineering team to rapidly build AI prototypes without managing infrastructure challenges.
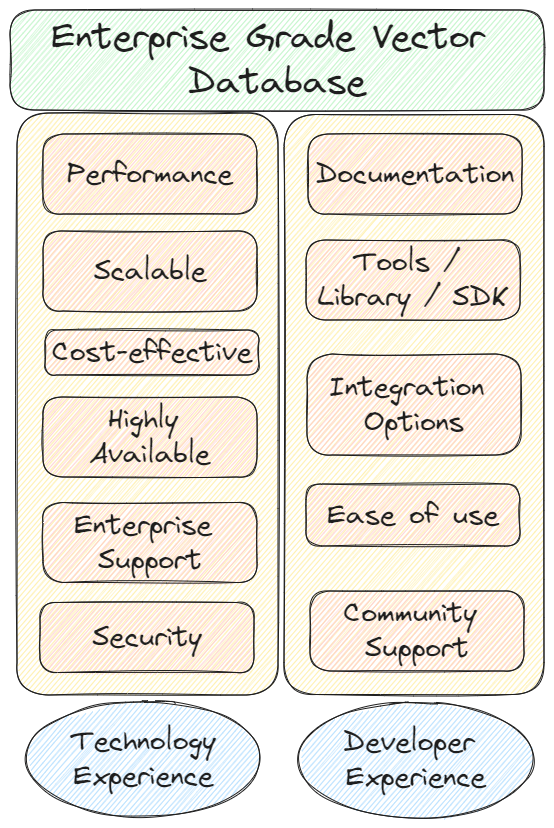
What Are the Building Blocks of the Technology Experience?
Technology experience majorly focuses on the operation and reliability side of the database involving the core infrastructure. We will discuss the major building blocks below.
Performance
Performance is one of the core aspect of the vector database. To implement the RAG pattern, an AI app needs to convert the company's own private data or knowledge into vector or embedding with the help of a Large Language Model (e.g., OpenAI's text-embedding-ada-002 model or Amazon's amazon.titan-embed-image-v1 foundation model) and then need to store that generated embedding into the vector database. As we know, in the Vector database, an index is required for efficient search in a large amount of records. An index is a data structure that speeds up retrieval operations in a database - the principle is the same as with an index in a book. The performance of the database heavily rely on how quickly and efficiently it can build the index so that the database search would yield a constant retrieval time no matter how much amount of data is stored in the system with varying dimensions. If you expect a huge number of knowledge or data that need to be stored in the vector database or if you expect them to grow exponentially down the line, then it is the best idea to choose a vector database that can support constant retrieval time from the storage, no matter how much data is stored.
Most commonly used vector indexing algorithms are IVF (Inverted File Index) and Hierarchical Navigable Small Worlds (HNSW). HNSW provides better quality search results with more speed as it takes more time to build or re-build the indexes, whereas IVF takes less memory. So in situation where we have memory constraint and no require to re-build the indexes quite often then we need to look for vector database using IVF algorithm. Otherwise, a vector database using the HNSW indexing algorithm is the default choice for better quality results and speed.
Scalable
Are you anticipating the rapid growth of your database? If so, it's desirable to plan ahead and consider the scalability of the candidate database. Scalability refers to a system's capacity to expand. Determine if there's a limit to the amount of vector embeddings the database provider can accommodate and explore scaling options.
One common approach for scaling out is "sharding" technique where the data is distributed across multiple databases copies, alleviating the load and enhancing performance by integrating the multiple read replicas of the same data. While this may seem a straightforward technique, practical implementation can be more complex. Adding additional shards to an existing deployment is not always straightforward and often involves some form of downtime. When the AI application has rapid growth then going with a managed service would be better choice than managing your own infrastructure, There are many SAAS (Software As A Service) based solution available which can scale immediately.
Cost-Effective
Cost is also another factor which carefully needs to be considered while building the GENERATIVE-AI based solution. When you are dealing with an outside vector database solution, you should consider an estimated number of embeddings you are expecting to scale and accordingly work with the vendor on the pricing based on quality, speed, and total number of embeddings.
Highly Available
Ensuring the continuous operation of your applications, particularly those facing customers, is crucial. We need to verify whether the provider can provide a service-level agreement (SLA) which is a formal commitment between the service provider and the client specifying the guaranteed uptime. In certain scenarios, it might be necessary to design a distributed system with a type of non-volatile storage to enhance the availability of the existing database.
Enterprise Support
When opting for a SAAS-based vector database solution, it's essential to establish a comprehensive SLA to ensure robust enterprise-grade support from the vector database vendor. This SLA should include pre-defined and mutually agreed upon RPO (Recovery Point Objective) and RTO (Recovery Time Objective). Additionally, whether it's a vendor-managed database solution or a self-managed open-source database solution, we should also consider having proper real-time monitoring in place. A robust monitoring system is vital for efficient vector database management, enabling the tracking of performance, health, and overall status through the real-time dashboard. Monitoring plays a critical role in detecting issues, optimizing performance, and ensuring seamless operations.
Security
In highly regulated sectors, there are instances where enterprise data must reside within the company's infrastructure. In such scenarios, a self-managed database solution could be considered an optimal choice. In the case of a vendor-managed solution, it's crucial to evaluate the product, ensuring that encryption in transit and encryption at rest is appropriately implemented to maintain the safety and security of the data. Additionally, it's important to confirm that the provider holds certifications such as SOC certification and is compliant with GDPR, as well as HIPAA-compliant for healthcare domains.
What Are the Building Blocks of the Developer Experience?
In this framework for choosing the right vector database for the Enterprise GENERATIVE AI solution, Developer experience holds equal significance alongside operational excellence. The goal should be to opt for a vector database that offers a user-friendly experience, allowing the engineering team to initiate experimentation with prototypes seamlessly, without the need for managing complexities. The various building blocks are:
Ease of Use
When implementing business logic into the GENERATIVE AI-based application, the engineering team greatly appreciates a database component that is user-friendly and easily portable to run in the development environment. It is truly a boon for an engineer to see if the vector database is available in docker-compose to run locally.
Documentation
The vector database solution needs to provide well-structured and straightforward documentation, accompanied by practical code examples in widely used programming languages like NodeJs, Java, etc. This ensures a smooth onboarding process for the engineering team.
Tools and SDKs
For the engineering team, it is vital that the database includes a library in their preferred programming language or a plugin compatible with their chosen framework. While Python packages are widespread in AI-based application development, for projects using other programming languages, it is advisable to explore options with existing support rather than investing valuable time in developing a custom client library.
Integration Options
In evaluating the developer experience, it is important to verify whether the vector database is accessible on the preferred cloud platform. The provision of multi-cloud support enhances the experience during prototype development and selecting the right deployment option.
Community Support
The vector database should be having a wide developer community to support ongoing features development and support. If this is a managed vendor product then ensure that the product should have a free tier offering or comprehensive free solution, enabling developers to run, view, modify, and experiment with working code across a majority of generic AI use cases.
Conclusion
In conclusion, I hope the high-level evaluation list presented here serves as a valuable guide, empowering you to make informed choices aligned with your unique organizational needs. In the next article, we will evaluate some of the popular vector database products to see how they fit within this framework depicted above.
Opinions expressed by DZone contributors are their own.
Comments