LLM: Trust, but Verify
Understand the challenges of developing, testing, and monitoring non-deterministic software; this is a new and significant challenge for observability.
Join the DZone community and get the full member experience.
Join For FreeMy most-used Gen AI trick is the summarization of web pages and documents. Combined with semantic search, summarization means I waste very little time searching for the words and ideas I need when I need them. Summarization has become so important that I now use it as I write to ensure that my key points show up in ML summaries. Unfortunately, it’s a double-edged sword: will reliance on deep learning lead to an embarrassing, expensive, or career-ending mistake because the summary missed something, or worse because the summary hallucinated?
Fortunately, many years as a technology professional have taught me the value of risk management, and that is the topic of this article: identifying the risks of summarization and the (actually pretty easy) methods of mitigating the risks.
Determining the Problem
For all of the software development history, we had it pretty easy to verify that our code worked as required. Software and computers are deterministic, finite state automata, i.e., they do what we tell them to do (barring cosmic rays or other sources of Byzantine failure). This made testing for correct behavior simple. Every possible unit test case could be handled by assertEquals(actual, expected), assertTrue, assertSame, assertNotNull, assertTimeout, and assertThrows. Even the trickiest dynamic string methods could be handled by assertTrue(string.Contains(a), string.Contains(b), string.Contains(c) and string.Contains(d).
But that was then. We now have large language models, which are fundamentally random systems. Not even the full alphabet of contains(a), contains(b), or contains(c) is up to the task of verifying the correct behavior of Gen AI when the response to an API call can vary by an unknowable degree. Neither JUnit nor Nunit nor PyUnit has assertMoreOrLessOK(actual, expected). And yet, we still have to test these Gen AI APIs and monitor them in production. Once your Gen AI feature is in production, traditional observability methods will not alert you to any potential failure modes described below.
So, the problem is how to ensure that the content returned by Gen AI systems are consistent with expectations, and how can we monitor them in production? For that, we have to understand the many failure modes of LLMs. Not only do we have to understand them, we have to be able to explain them to our non-technical colleagues - before there’s a problem.
LLM failure modes are unique and present some real challenges to observability. Let me illustrate with a recent example from OpenAI that wasn’t covered in the mainstream news but should have been. Three researchers from Stanford University UC Berkeley had been monitoring ChatGPT to see if it would change over time, and it did.
Problem: Just Plain Wrong
In one case, the investigators repeatedly asked ChatGPT a simple question: Is 17,077 a prime number? Think step by step and then answer yes or no. ChatGPT responded correctly 98% of the time in March of 2023. Three months later, they repeated the test, but ChatGPT answered incorrectly 87% of the time!
It should be noted that OpenAI released a new version of the API on March 14, 2023. Two questions must be answered:
- Did OpenAI know the new release had problems, and why did they release it?
- If they didn’t know, then why not?
This is just one example of your challenges in monitoring Generative AI. Even if you have full control of the releases, you have to be able to detect outright failures.
The researchers have made their code and instructions available on GitHub, which is highly instructive. They have also added some additional materials and an update. This is a great starting point if your use case requires factual accuracy.
Problem: General Harms
In addition to accuracy, it’s very possible for Generative AI to produce responses with harmful qualities such as bias or toxicity. HELM, the Holistic Evaluation of Language Models, is a living and rapidly growing collection of benchmarks. It can evaluate more than 60 public or open-source LLMs across 42 scenarios, with 59 metrics. It is an excellent starting point for anyone seeking to better understand the risks of language models and the degree to which various vendors are transparent about the risks associated with their products. Both the original paper and code are freely available online.
Model Collapse is another potential risk; if it happens, the results will be known far and wide. Mitigation is as simple as ensuring you can return to the previous model. Some researchers claim that ChatGPT and Bard are already heading in that direction.
Problem: Model Drift
Why should you be concerned about drift? Let me tell you a story. OpenAI is a startup; the one thing a startup needs more than anything else is rapid growth. The user count exploded when ChatGPT was first released in December of 2022. Starting in June of 2023, however, user count started dropping and continued to drop through the summer. Many pundits speculated that this had something to do with student users of ChatGPT taking the summer off, but commentators had no internal data from OpenAI, so speculation was all they could do. Understandably, OpenAI has not released any information on the cause of the drop.
Now, imagine that this happens to you. One day, usage stats for your Gen AI feature start dropping. None of the other typical business data points to a potential cause. Only 4% of customers tend to complain, and your complaints haven’t increased. You have implemented excellent API and UX observability; neither response time nor availability shows any problems. What could be causing the drop? Do you have any gaps in your data?
Model Drift is the gradual change in the LLM responses due to changes in the data, the language model, or the cultures that provide the training data. The changes in LLM behavior may be hard to detect when looking at individual responses.
- Data drift refers to changes in the input data model processes over time.
- Model driftrefers to changes in the model's performance over time after it has been deployed and can result in:
- Performance degradation: the model's accuracy decreases on the same test set due to data drift.
- Behavioral drift: the model makes different predictions than originally, even on the same data.
However, drift can also refer to concept drift, which leads to models learning outdated or invalid conceptual assumptions, leading to incorrect modeling of the current language. It can cause failures on downstream tasks, like generating appropriate responses to customer messages.
And the Risks?
So far, the potential problems we have identified are failure and drift in the Generative AI system’s behavior, leading to unexpected outcomes. Unfortunately, It is not yet possible to categorically state what the risks to the business might be because nobody can determine beforehand what the possible range of responses might be with non-deterministic systems.
You will have to anticipate the potential risks on a Gen AI use-case-by-use-case basis: is your implementation offering financial advice or responding to customer questions for factual information about your products?
LLMs are not deterministic; a statement that, hopefully, means more to you now than it did three minutes ago. This is another challenge you may have when it comes time to help non-technical colleagues understand the potential for trouble. The best thing to say about risk is that all the usual suspects are in play (loss of business reputation, loss of revenue, regulatory violations, security).
Fight Fire With Fire
The good news is that mitigating the risks of implementing Generative AI can be done with some new observability methods. The bad news is that you have to use machine learning to do it. Fortunately, it’s pretty easy to implement. Unfortunately, you can’t detect drift using your customer prompts - you must use a benchmark dataset.
What You’re Not Doing
This article is not about detecting drift in a model’s dataset - that is the responsibility of the model's creators, and the work to detect drift is serious data science.
If you have someone on staff with a degree in statistics or applied math, you might want to attempt to drift using the method (maximum mean discrepancy) described in this paper:
Uncovering Drift In Textual Data: An Unsupervised Method For Detecting And Mitigating Drift In Machine Learning Models
What Are You Doing?
You are trying to detect drift in a model’s behavior using a relatively small dataset of carefully curated text samples representative of your use case. Like the method above, you will use discrepancy, but not for an entire set. Instead, you will create a baseline collection of prompts and responses, with each prompt-response pair sent to the API 100 times, and then calculate the mean and variance for each prompt. Then, every day or so, you’ll send the same prompts to the Gen AI API and look for excessive variance from the mean. Again, it’s pretty easy to do.
Let’s Code!
Choose a language model to use when creating embeddings. It should be as close as possible to the model being used by your Gen AI API. You must be able to have complete control over this model’s files, and all of its configurations, and all of the supporting libraries that are used when embeddings are created and when similarity is calculated. This model becomes your reference. The equivalent of the 1 kg sphere of pure Silicon that serves as a global standard of mass.
Java Implementation
The how-do-I-do-this-in-Java experience for me, a 20-year veteran of Java coding, was painful until I sorted out the examples from Deep Java Learning. Unfortunately, DJL has a very limited list of native language models available compared to Python. Though over-engineered, for example, the Java code is almost as pithy as Python:
Setup of the LLM used to create sentence embedding vectors.

Code to create the text embedding vectors and compare the semantic similarity between two texts:

The function that calculates the semantic similarity.

Put It All Together
As mentioned earlier, the goal is to be able to detect drift in individual responses. Depending on your use case and the Gen AI API you’re going to use, the number of benchmark prompts, the number of responses that form the baseline, and the rate at which you sample the API will vary. The steps go like this:
- Create a baseline set of prompts and Gen AI API responses that are strongly representative of your use case: 10, 100, or 1,000. Save these in Table A.
- Create a baseline set of responses: for each of the prompts, send to the API 10, 50, or 100 times over a few days to a week, and save the text responses. Save these in Table B.
- Calculate the similarity between the baseline responses: for each baseline response, calculate the similarity between it and the response in Table A. Save these similarity values with each response in Table B.
- Calculate the mean, variance, and standard deviation of the similarity values in table B and store them in table A.
- Begin the drift detection runs: perform the same steps as in step 1 every day or so. Save the results in Table C.
- Calculate the similarity between the responses in Table A at the end of each detection run.
- When all the similarities have been calculated, look for any outside the original variance.
- For those responses with excessive variance, review the original prompt, the original response from Table A, and the latest response in Table C. Is there enough of a difference in the meaning of the latest response? If so, your Gen AI API model may be drifting away from what the product owner expects; chat with them about it.
Result
The data, when collected and charted, should look something like this:
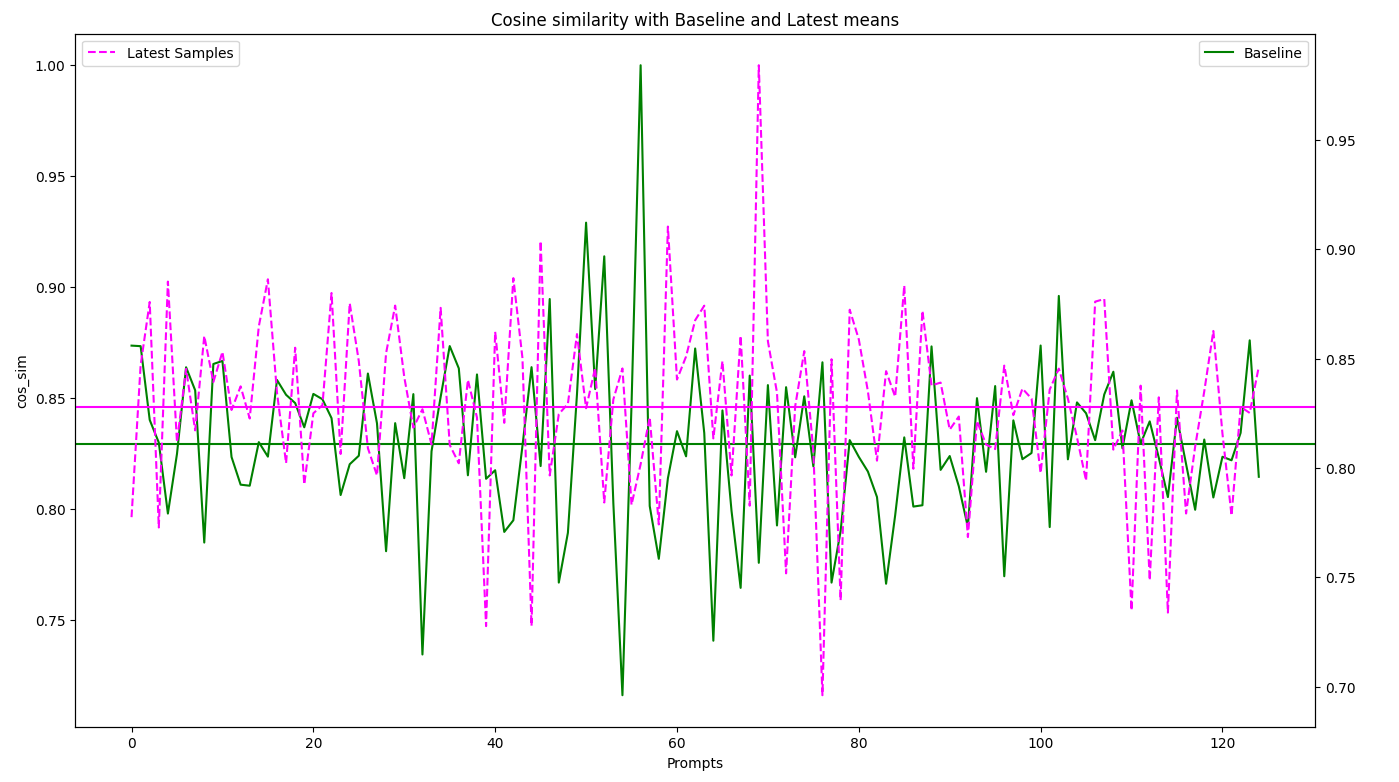
The chart shows the result of a benchmark set of 125 prompts sent to the API 100 times over one week - the Baseline samples. The mean similarity for each prompt was calculated and is represented by the points in the Baseline line and mean plot. The latest run of the same 125 benchmark samples was sent to the API yesterday. Their similarity was calculated vs the baseline mean values, the Latest samples. The responses of individual samples that seem to vary quite a bit from the mean are reviewed to see if there is any significant semantic discrepancy with the baseline response. If that happens, review your findings with the product owner.
Conclusion
Non-deterministic software will continue to be a challenge for engineers to develop, test, and monitor until the day that the big AI brain takes all of our jobs. Until then, I hope I have forewarned and forearmed you with clear explanations and easy methods to keep you smiling during your next Gen AI incident meeting. And, if nothing else, this article should help you to make the case for hiring your own data scientist. If that’s not in the cards, then… math?
Opinions expressed by DZone contributors are their own.
Comments