Accelerate Innovation by Shifting Left FinOps: Part 5
This part of the series covers cost optimization techniques for data components in your solution architecture.
Join the DZone community and get the full member experience.
Join For FreeIn the previous parts of this series, you learned the techniques to optimize the cost for Infrastructure and Application components. In this part, we will look at the ways to review the design and optimize the cost for components in your data layer.
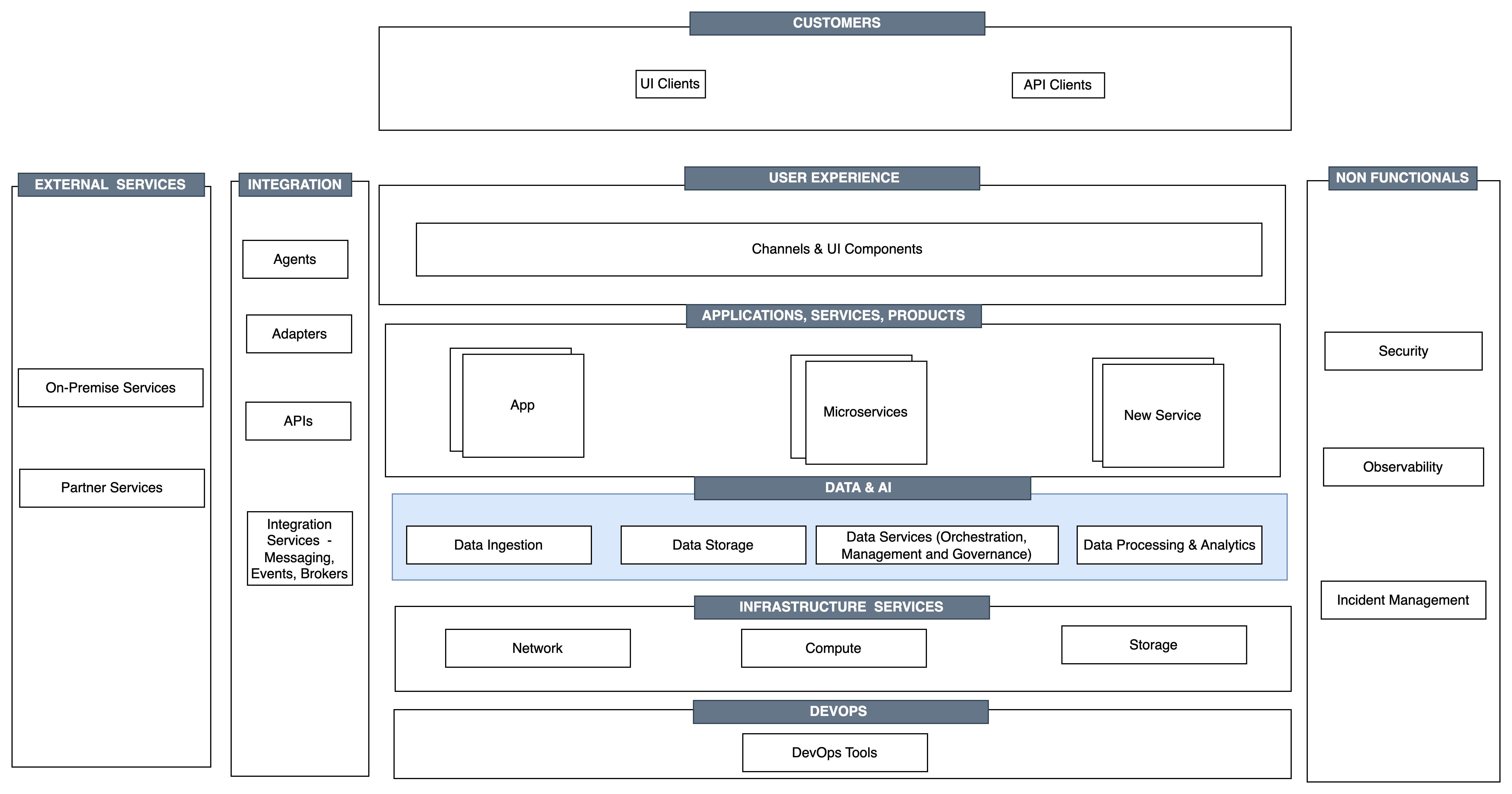 Key architecture components for a cloud-deployed workload.
Key architecture components for a cloud-deployed workload.
The techniques for cost optimization for data touches several data domains, including but not limited to
- Data Ingestion
- Data pipelines
- Data Analysis and AI/ML
- Data Storage, Retention and Archival
This is another layer of the architecture that's fast changing, and little time upfront can create a lot of savings with the solution.
Data Ingestion
This can be a time-consuming resource, intensive, and a costly process depending on the domain and the volume of data. In this step, the application either pulls data from external sources or domain data sources pushes data to the application. The protocol selection also can have a cost impact. If the push or pull is via APIs, there can be cost associated with it like, based on the volume of API invocations. In case you select a file-based protocol, there will be costs associated with the storage. Depending on whether the data is streamed or batched, the cost could vary. The component where this data is stored needs to be optimized for data ingestion throughput and storage.
The data format is another important consideration that needs to be agreed by the application with the data sources. The data ingestion times and, correspondingly, the cost could vary depending on the data format. You need to select the data format that meets the functional requirement and at the same cost-optimized. Based on the format, the cost for various other factors such as storage, transfer, and processing also could varry. For example;
- CSV is a format that's simple and widely used, but it is not storage-efficient from a cost perspective.
- JSON is a text-based data format that is more flexible than CSV, but again. However, it is also not very space-efficient, and data compression may not be very effective for this format, resulting in higher storage and transfer costs, especially for large datasets.
Protobuf: Protobuf is a binary data format that is optimized for high performance and compactness. It can be a good choice or the format for high-performance computing applications with complex schemas.
- Avro: Avro is again a binary data format that is compact and efficient and supports schema evolution.
- Parquet is a columnar storage format that supports efficient compression and is a preferred format that is space-efficient and optimized for use with downstream processing platforms like Hadoop.
Guidance
Space-efficient and optimized data formats like Avro, Protobuf, and Parquet can help lower storage and transfer costs compared to text-based formats like CSV and JSON. These efficient data formats help store and process more data with fewer resources and hence less cost. However, it is important to pick the right format and protocol for data ingestion depending on other factors as well, like support for different clients and data being available efficiently for downstream processing clients.
Data Pipelines
The services and components in this layer involve data processing that typically does data transformation and enrichment.
The initial step is to do validation of the incoming data and convert it to a standard data format where necessary. Further data manipulation includes schema matching, encoding, indexing, and compressing the data. Another technique that helps save costs at this stage is to filter out unwanted data. This will help reduce the storage and transfer costs as well as improve processing times. Compression of data is performed to store and transfer optimally. This may be done as part of the data ingestion step or as part of data pipelines leveraging compression libraries and algorithms like gzip, Lempel–Ziv (LZ), etc.
Data access and data transfer is another important cost to be considered. Faster data access means faster throughput from the application components and services. This overall reduces the cost of the solution as well. There are various techniques to implement faster data access.
- Caching is a commonly used technique for storing frequently accessed data in memory rather than the need to make resource-heavy calls to the backend for data access. While caching requires new solution components to be added, it also helps reduce the overall cost by increasing the throughput and reducing the data access costs.
- Indexing is another proven technique to speed up performance with queries. Again, while there's cost to adding indexes to your data, the cost is often offset by the performance improvements and overall efficiency delivered for the queries.
- In certain cases, columnar storage, like the parquet format, provides better responses to queries through faster and more efficient data retrieval that helps reduce data access costs.
- Data partitioning and schema design is another critical element to be reviewed from a cost perspective. Partitioning involves dividing data into smaller, more manageable parts based on specific criteria such as date or category. Partitioning data can help optimize query performance and reduce data access costs. Depending on the domain and type of data, you can decide whether to go with one monolithic schema versus creating a separate schema for sub-domains or categories to speed up the data ingestion and retrieval.
- Use of serverless technologies such as AWS Lambda or Azure Functions can further help reduce the data processing cost as these services only charge for the resources that are actually used, which can be more cost-effective than using dedicated servers.
- Refer to the network section above to leverage various options at the network layer for data transfer to meet the security requirements and keep the cost minimum for your use case.
Guidance
Data access, transformation, and enrichment are core processes executed in this step as part of data pipelines. The use of a canonical standard format for getting data in and out of the application helps in keeping the transformation cost minimal. By implementing the above best practices, you can optimize your data ingestion costs in the cloud and improve efficiency without sacrificing data quality or performance.
Data Analysis
This set of components is involved in driving insights from the data ingested on the solution side. Picking the right service as well as from the right service provider is very important. The analysis cost can go up exponentially and make your product unviable. So selection of the right service based on the nature of our workload is important.
For instance, there are Cloud Service Provider services like GCP BigQuery provided by Google and Redshift provided by AWS. BigQuery from Google uses a serverless architecture that automatically scales to handle high volumes of queries, making it a good choice for organizations with dynamic data analytics needs. BigQuery's pricing is based on the amount of data processed and starts at $5 per terabyte. Redshift is a cloud-based data warehousing solution from Amazon Web Services (AWS) that allows users to store and analyze large amounts of data. Redshift's pricing is based on the amount of data stored and the number of compute nodes used. The cost for storage starts at $0.023 per gigabyte per month, and the cost for compute nodes starts at $0.25 per hour.
There are other third-party services like Databricks and Snowflake that you might want to consider based on your use case and budget. Databricks is a cloud-based data engineering and analytics platform that is built on top of Apache Spark. Databricks pricing is based on the number of virtual machines (VMs) used and starts at $0.15 per hour per VM. Databricks pricing is based on the number of virtual machines (VMs) used per hour, and the cost can range from $0.15 per hour for a single VM to $3.20 per hour for a cluster of 128 VMs. Similarly, Snowflake is a cloud-based data warehousing platform that offers automatic scaling and instant elasticity, which makes it a good choice for organizations with variable data analytics workloads. Snowflake's pricing is based on the amount of data stored and the amount of data processed, with costs starting at $23 per terabyte per month for storage and $2 per terabyte for processing.
Guidance
Data analysis is an important component of the solution. Use of the right cloud service for data analysis from cloud service providers or third parties is necessary to best fit your solution needs and within budget. So, while comparing these platforms, each would bring a different set of values and capabilities for the solution, providing different levels of flexibility at various price points. In terms of cost comparison, Snowflake and Redshift have similar pricing structures, but Snowflake's pricing may be more expensive for smaller amounts of data, while Redshift may be more expensive for larger amounts of data. Databricks pricing is based on the number of VMs used per hour, so it may be a more cost-effective solution for smaller workloads that don't require a large number of compute resources. Ultimately, you need to make the right choice depending on your specific data analytics needs and goals.
Data Storage, Retention and Archival
Data storage, retention, and archival is another significant component of your cloud invoice; if not handled or decided correctly in the beginning, it can soon go out of control. The cost also varies based on the access patterns. There needs to be a way to evaluate the requirements on this front during the architecture/design phase, as well as have a process to continuously relook at the guardrails and thresholds based on the business requirements. Selecting datastores that supports automated lifecycle management helps in moving the data across tiers based on its age and usage patterns. The goal is to achieve the most cost-effective storage and recovery of data without sacrificing application performance and availability. Retention, archival, and time-to-live (TTL) settings can play a crucial role in optimizing storage costs. Time-to-live (TTL) settings defines how long the data should be cached in memory or disk. Databases that support this setting optimize the cost by moving or purging data based on the policy. Similarly retention policies specifies how long data should be kept in storage. By defining appropriate retention policies, you can ensure that no data is retained beyond the specified period, resulting in savings. Use of compression and deduplication also helps reduce the large amount of storage space required for your data, which can lead to significant cost savings over time. Versioning of data increases the storage cost. Enable versioning of data only if needed for the business.
Guidance
Guard rails for specific data types and data stores needs to be established based on the business, compliance, and regulatory requirements. Leverage cloud service specific tuning and lifecycle management to manage the cost. Automation tools are available to to manage retention, archival, and TTL settings, making it easier to optimize your data storage system, reducing the risk of human error, and saving cost. It is possible to establish the automation and policies much ahead in the software development lifecycle.
Conclusion
As part of this series, the objective was to share the value and impact of shifting left FinOps for the business and the customers. The series also deep-dived into various techniques that you can use to optimize cost based on the application design and all layers of your cloud-native architecture. There is a significant opportunity to apply the same methodology to non-functional components as well as to reduce the cost of security, observability, and availability. In the final part of this series, we will share a worked out example of how to apply these techniques with the related savings and impact.
Opinions expressed by DZone contributors are their own.
Comments