Adaptive Change Management: A DevOps Approach to Change Management
Approach change management from an adaptive perspective that allows you to iterate and remain agile without sacrificing stability.
Join the DZone community and get the full member experience.
Join For FreeChange management is another example of an ITIL-based process which can be significantly improved by the application of DevOps practices. Change management is often implemented in ways which fly in the face of key principles of DevOps. Traditional implementations put multiple layers of approval in place for every change, inserting significant bureaucracy and gates which almost guarantee longer release cycles and delays in getting value to the customer. This fundamentally contradicts the DevOps emphasis of short release cycles and the rapid delivery of value to customers.
However, there can be little argument that tracking changes in a technical environment can be highly valuable. Especially in large environments where many different changes are occurring at the same time, it is critical to have visibility into what is changing and how those changes might impact one another and, ultimately, the end customer. By bringing DevOps principles to bear on change management we can ensure we are tracking and managing changes while enabling speed and agility.
A DevOps approach to change management requires that we shift the focus of change management from the myopic focus on stability. We must broaden our perspective to understand change management as a process that enables speed and agility while ensuring stability. Instead of using it as gates to prevent change, we use it as a process to enable change to get to the customers quickly.
We often work with cultures that are doing tens and even hundreds of releases a day using continuous integration and continuous deployment. In order to do change management at this pace you must automate your change management process. ServiceNow and other ITSM tools expose API to allow you to easily integrate your CD pipeline with your change management system. Using these APIs, companies can automatically create change tickets. This ensures that there is a ticket for every change without causing additional burden or slowing down your deployment process. There are a lot of great examples like this where the process framework, culture of collaboration, and the tools can come together to really create great value.
Adaptive Change Management
Working with our customers, we have developed an approach to change management which we refer to as Adaptive Change Management. The goal of Adaptive Change Management is to implement lightweight, scalable, and agile process to improve stability while enabling business velocity. This process takes into account the risk of a change to ensure that the appropriate amount of attention is paid to high-risk changes without slowing down low-risk changes. This approach also provides a mechanism for teams to lower their risk driving down friction and encouraging continuous improvement.
In this approach to change management, every change is assigned a risk. This aligns with the overarching goal of ensuring that we are appropriately managing risk and adapting to it. Approval and oversight levels are then dynamically adjusted based on the risk of a given change. In addition, release times can be adjusted in accordance with risk levels. Under these parameters, low-risk changes, with fully automated testing using CI/CD and A/B deployments, are released without any approvals. On the other hand, high-risk changes, which may require coordination with multiple teams and which may be highly manual, receive review from all teams that may be impacted to ensure collaboration and appropriate integration testing at all levels.
Risk Calculation
Risk calculation for a change can be aligned with standard methods of using the impact and probability of a risk. In this approach, probability reflects the likelihood that a given risk will occur while impact reflects the impact on the business if a risk occurs regardless of the probability. That is, assuming the change fails, what is the level of impact on the business? It is important that teams be allowed to assess their own impact and risk. This aligns with the DevOps concepts of accountability and trust. By trusting teams to accurately assess the risk of a change we can build a high trust culture that drives high-performance companies.
I know that some may balk at this decrying that we cannot trust the releasors to accurately assess the risk of their changes favoring rapid delivery over stability. However, I can say that this is not the case for high-trust environments where development and operations teams alike are focused on the success of the customer. That said, it is possible to put in place mitigating controls if needed. One way to do this is to weigh the risk rating based on a team’s past performance as well as their ability to accurately rate the risk of a change. By bringing actual performance back into the risk rating we can build a numerical feedback format and allay concerns that some may game the system.
Guiding Principles
Once the risk of a change is calculated the review and approvals can be adjusted to align with the level of risk of a given change. Low-risk changes may require review from managers. Higher-risk changes may require coordination with other teams where there are cross-dependencies and, in such situations, may benefit from review by a Change Advisory Board. When aligning approvals with risk it is important to keep in mind some guiding principles:
The closer the change review is to the technical details of the code, the better. That is, an engineer on the same development team will have a much better idea of the impact of a code change than the VP of that group.
While high trust is critical, an audit does require that there be another set of eyes reviewing changes to avoid people making illicit or damaging changes in the case that someone does have malicious intent.
The Change Advisory Board (CAB) should act as a “flight control” coordinating between different teams and business needs. The CAB should not be a bureaucratic body designed to stop changes.
Small, incremental changes are safer.
The easier we can make it to submit a change the more likely people are to follow the process.
With these principals in mind, we can develop an approval system that ensures proper oversight while allowing changes to production to be as frictionless as possible.
Standard Changes and "Change Freezes"
In addition to these types of changes, there are also standard changes that do not require any approval. This is the ideal state for changes in a DevOps world where small changes can be released almost continuously to production. Standard changes are pre-approved changes that are extremely low risk, relatively common, and follow a set process. This is an idea for changes that can be deployed in a fully automated manner using Continuous Integration and Continuous Deployment which includes best practices such as continuous testing, automated rollback, feature flags, and the like. These sorts of changes can be approved to be standard changes. In order for a change to qualify as a standard change it must be low risk and have a history of successful performance. Once approved, these Standard Changes can get deployed without any approval. This is ideal for an organization that wants to move quickly. By encouraging as many changes as possible to go through the standard change process organizations can reduce organizational bureaucracy and increase time to market.
It is important to note that timing can play an important part in change management as it can impact the risk of a change. Periods of high activity, like Cyber Monday for commerce platforms, as well as major company events, can be high-risk times for a business. Often it is desirable to do whatever is possible during these times to minimize risk.
However, this is not to say that there should be “Change Freezes” during these times when no changes occur. In my experience “Change Freezes” simply do not work. There are multiple reasons these do not work, the first of which is that they are hardly, if ever, actually adhered to. The fact is that, even during high-risk times, business and technology must continue to move forward. Whether it is an emergency fix for a customer issue or business critical release, there are almost always exceptions to changes freezes. This happens so much so that I often hear of these referred to as “change slushes.”
In addition, data shows that change freezes often cause a huge influx of changes directly before the freeze where teams try to cram in all their critical features directly before a high risk leading to significant instability during the very period of time the business is trying to protect. In addition, we see a flood of releases directly after the change freeze period show that a backlog of changes has built up and the company is losing out on delivering value to the customer during that period. The following data from one company depicts exactly this scenario:
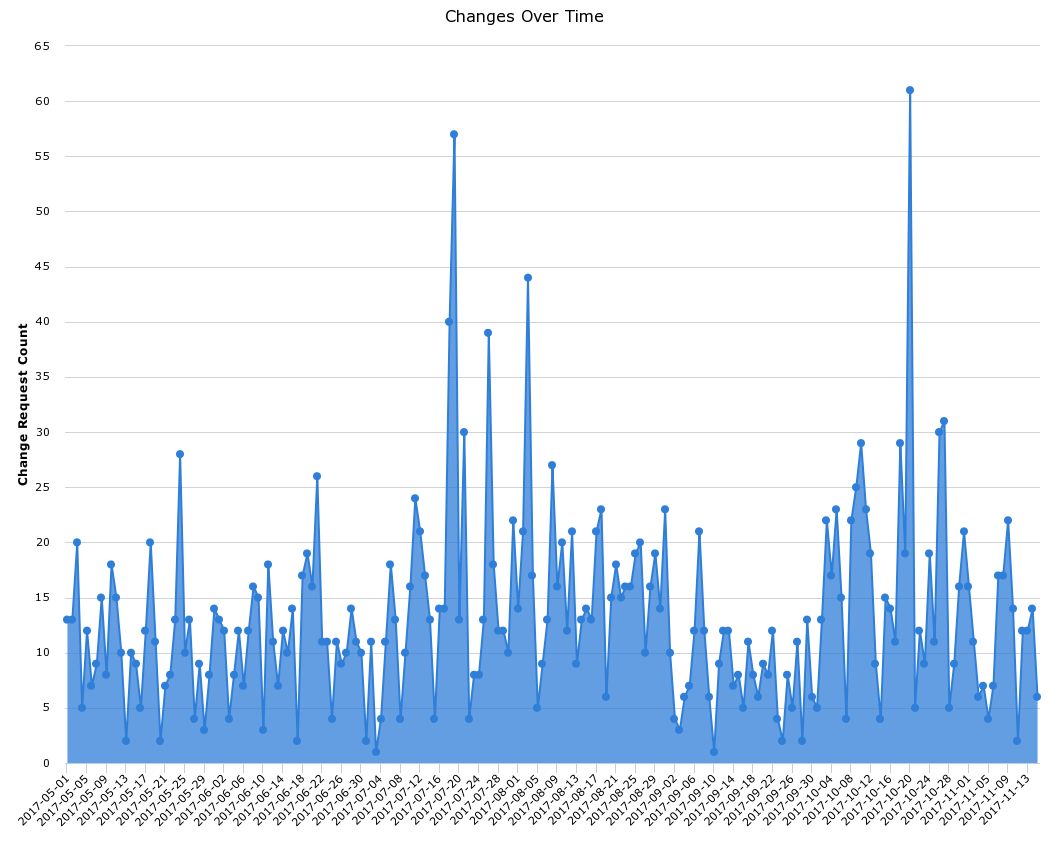
Can you guess where the “Change Freeze” was?
The final problem with Change Freeze periods is that it treats low-risk changes in the same way it treats high-risk changes with a blanket statement that “Thou shalt not change”.
One way to address these issues is to simply approach it for what it is: a high-risk period. With that in mind, we can simply raise the risk of any changes during that period. Starting from our adaptive approach to change management we can raise the risk of all change so that low-risk changes are evaluated as medium risk changes, medium as high, and high as critical. Not that this necessitates the creation of an additional level of risk which is higher than high. What we find is that this does a good job of accurately reflecting the business reality without imposing a somewhat arbitrary, unrealistic, blanket statement which is rarely enforced. The reality is that this is a higher risk time for the business and any changes should be evaluated with this in mind.
Of course, testing is a critical success factor for any change management process to be successful. All testing from the unit level to integration testing are important. The key here is to automate wherever possible and to build this automation into your deployment pipeline. With automated testing in place resources can be deployed to do testing which is more exploratory in nature that might catch things that automated testing would not. This test automation can be used in every environment and should be integrated into the deployment pipeline.
There is a balance here from a time perspective in that these tests must test full system functionality but also cannot take much time if they are going to be used in a rapidly deploying pipeline. This balance will vary from team to team but it must not be so time-consuming that teams are tempted to skip testing or to do less frequent releases. Ultimately, it is the responsibility of the team developing the code to determine this balance. They must hold accountability for ensuring code is delivered to customers without issues. Once testing is automated and proven successful it is easy to advocate that these changes be included as standard changes enabling rapid and seamless delivery to the customers.
Conclusion
In all of the planning and risk classification, it is important to remember that there will always be unplanned/emergency changes and ensure that your process accounts for these. To maintain the adaptability of your change management process, even under emergency circumstances you can continue to use the classification and approval matrices described above. However, in emergency circumstances, modifications must be made so that changes can be made even quicker. In order to accommodate rapid change it is often important to allow verbal approval for these sorts of changes. It is often also appropriate to delay the filing of any change forms until after the emergency situation has been remediated. By making these adjustments one can ensure that a process that is already designed for rapid deployment can become even faster to handle emergencies without sacrificing the review and oversight necessary.
The world of technology continues to change at an ever-increasing rate and our processes much adapt to accommodate that change. With the principles and practices of DevOps, we are seeing software deployed at an ever-increasing frequency. With the move to the cloud we are seeing dynamic infrastructure which can be created in minutes. Unless our change management process is as adaptive we will hinder our ability to get to market quickly and drive innovation. There is value in knowing what is changing in our environment, but the way we track and manage those changes must adapt as the speed of the changes increases.
Opinions expressed by DZone contributors are their own.
Comments