AI-Based Multi-Cloud Cost and Resource Optimization
Multi-cloud costs rise due to poor visibility, idle resources, and reactive scaling. AI-driven FinOps automates optimization to cut waste and control spend.
Join the DZone community and get the full member experience.
Join For FreeWhy Multi Cloud Cost Control Has Become Harder Than Ever
Most enterprises did not intentionally design a multi cloud strategy from day one. It evolved. One team adopted one provider. Another team preferred a different ecosystem. Over time, resilience, vendor leverage, and geographic expansion pushed workloads across multiple platforms.
What began as flexibility slowly became complexity.
Finance teams see growing invoices. Engineering teams see healthy dashboards. But somewhere in between, the link between infrastructure behavior and financial impact disappears. Small inefficiencies compound. Idle compute hides inside development clusters. Storage volumes remain attached to nothing. Traffic patterns fluctuate, but infrastructure remains static.
Multi cloud does not fail because of one catastrophic mistake. It fails because of accumulated invisibility.
This is where AI becomes transformative. Not as a buzzword, but as a continuous reasoning layer that interprets infrastructure behavior, predicts demand, and enforces optimization automatically.
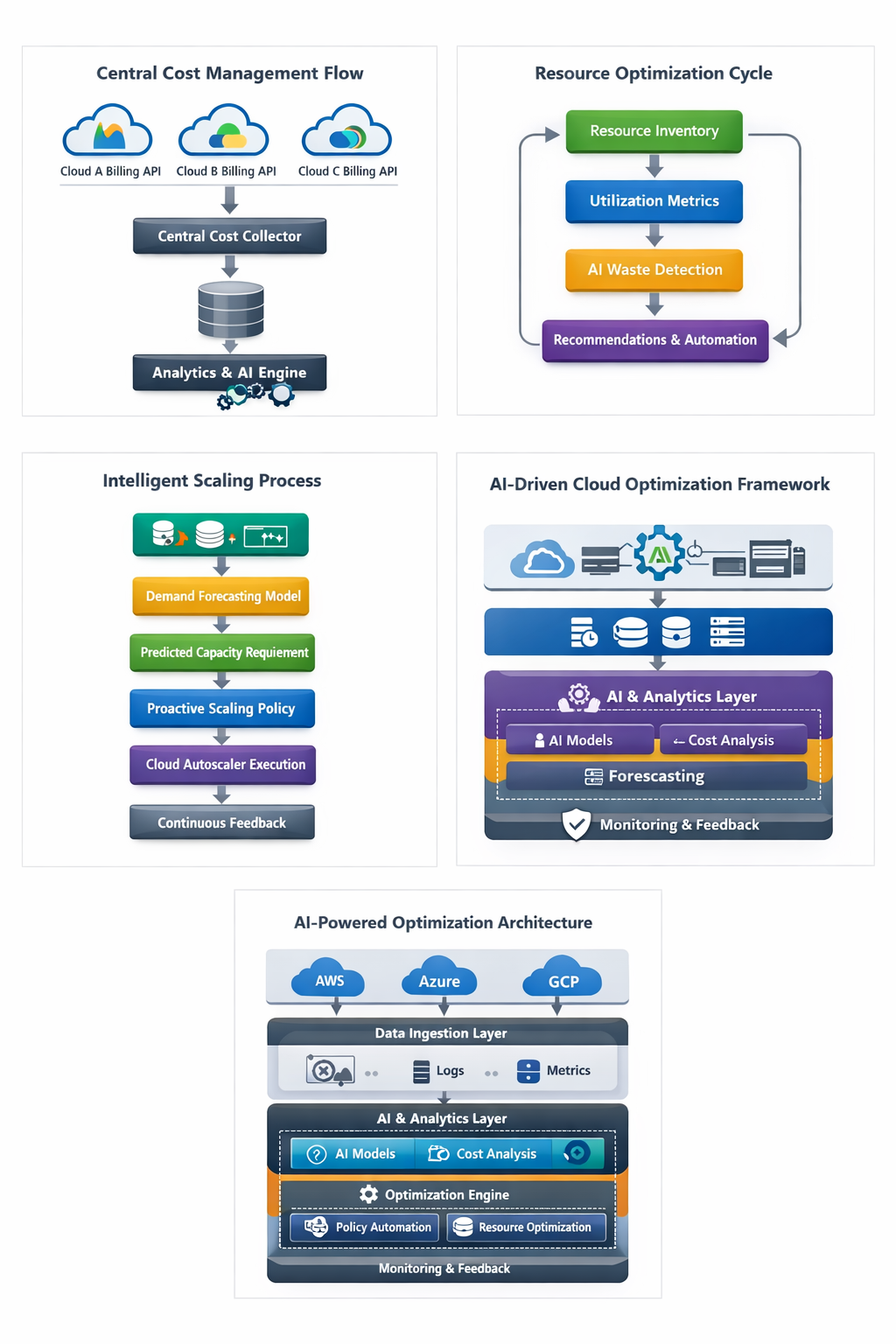
Where Cost Inefficiencies Actually Hide
Multi cloud cost challenges typically fall into three structural categories: fragmented visibility, resource sprawl, and reactive scaling.
1. Fragmented Visibility
Every provider exposes billing differently. Some charge by the second. Others by the hour. Network egress categories vary. Storage tiers differ. Without normalization, cost comparison becomes guesswork.
A practical solution is to aggregate billing data into a unified model.
import pandas as pd# Example unified billing normalization
billing = pd.read_csv("multi_cloud_billing.csv")
billing["cost_per_vcpu_hour"] = (
billing["total_cost"] /
billing["vcpu_hours"].replace(0, 1)
)
billing["cost_per_gb"] = (
billing["storage_cost"] /
billing["gb_used"].replace(0, 1)
)
print(billing.head())Once cost is standardized, anomalies and inefficiencies become visible across providers.
This is the foundation of intelligent optimization.
2. Resource Sprawl
Speed is both a strength and a weakness of cloud native systems. Developers deploy quickly. Infrastructure scales automatically. But cleanup rarely scales at the same rate.
Idle virtual machines remain active. Test clusters are forgotten. Unattached disks accumulate. These do not create alarms. They simply create slow budget erosion.
An AI driven waste detection loop continuously scans inventory and usage:
Inventory → Utilization → Pattern Analysis → Recommendation → Automation
Example logic for detecting idle compute:
def detect_idle(avg_cpu, avg_memory, threshold=10):
if avg_cpu < threshold and avg_memory < threshold:
return "Potentially Idle"
return "Active"
print(detect_idle(avg_cpu=5, avg_memory=7))This may seem simple, but at scale, applied across thousands of resources, it unlocks meaningful savings.
3. Reactive Scaling Instead of Predictive Scaling
Most auto scaling policies are reactive. They trigger when CPU crosses a threshold. By then, user experience may already be affected.
The smarter approach is predictive scaling.
Forecasting models analyze historical traffic and anticipate future demand.
import pandas as pd
traffic = pd.read_csv("traffic.csv")
# Simple rolling average baseline
traffic["forecast"] = traffic["requests"].rolling(window=60).mean()
print(traffic.tail())In production, more advanced models such as LSTM networks are used:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(64, input_shape=(24,1)))
model.add(Dense(1))
model.compile(optimizer="adam", loss="mse")The shift from reactive to predictive scaling alone can reduce overprovisioning significantly while improving performance stability.
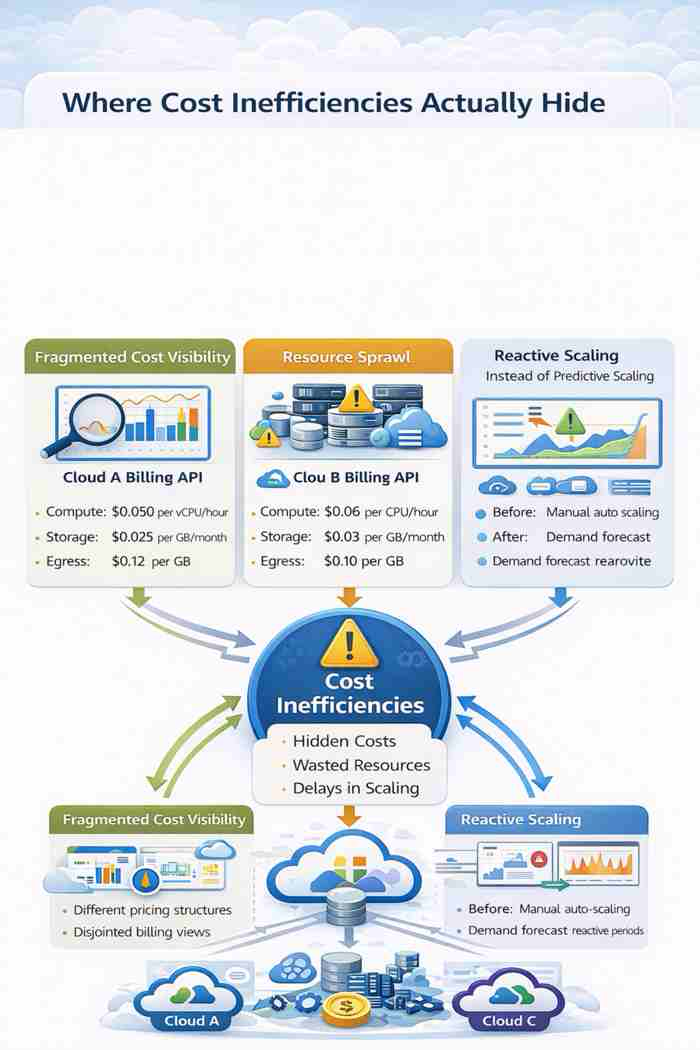
4. Designing the Continuous Optimization Loop
Optimization must operate as a closed system.
Data enters.
Models interpret it.
Decisions are made.
Changes are enforced.
Results are validated.
The system learns again.
The architecture typically includes:
- Billing ingestion layer
- Metrics and telemetry aggregation
- Data normalization store
- Machine learning layer
- Optimization decision engine
- Automation pipeline
- Monitoring and feedback loop
The critical element is feedback. Every change must be evaluated. Did savings occur? Did latency increase? Did reliability degrade?
Without feedback, intelligence becomes guesswork.
5. Machine Learning That Actually Delivers Value
Machine learning in FinOps must solve practical, measurable problems.
Demand Forecasting
Forecast short term infrastructure needs so scaling decisions are proactive.
Cost Anomaly Detection
Detect unexpected cost spikes within hours.
from sklearn.ensemble import IsolationForest
model = IsolationForest(contamination=0.05)
cost_data["anomaly"] = model.fit_predict(cost_data[["daily_cost"]])This prevents runaway spend.
Reinforcement Learning for Placement
Placement decisions involve tradeoffs between cost, latency, and compliance.
A simplified reward function may look like:
reward = savings - (sla_penalty + migration_cost)Over time, the model learns which placements maximize long term benefit.
6. Intelligent Rightsizing: Reducing Cost Without Breaking Performance
Rightsizing is often described as the simplest way to reduce cloud cost. In practice, it is rarely simple. Most organizations either ignore it entirely or apply it too aggressively. Both approaches create problems.
At its core, rightsizing means aligning infrastructure capacity with actual workload demand. But real workloads are not static. They fluctuate by hour, by day, and by season. Some systems show stable utilization. Others spike unpredictably. A naïve downsizing decision based only on average CPU can introduce instability.
Intelligent rightsizing goes beyond surface metrics. It evaluates patterns, risk, and business impact before making any recommendation.
Why Traditional Rightsizing Fails
Many teams rely on basic thresholds such as:
If average CPU usage is below 30 percent, reduce instance size.
This logic ignores important realities:
- Peak usage may be short but critical
- Workloads may have burst patterns
- Memory usage may differ from CPU trends
- Latency sensitivity varies by service
- Some services are revenue critical
A system that appears underutilized most of the day may still require burst capacity for short high traffic windows. Blind downsizing creates performance degradation and erodes trust in optimization systems.
Intelligent rightsizing avoids that mistake.
Rightsizing is one of the most immediate levers for cost reduction.
But it must be risk aware.
def recommend_resize(avg_cpu, peak_cpu):
if avg_cpu < 30 and peak_cpu < 70:
return "Downsize"
return "Keep Current"A proper system evaluates variance, seasonality, and workload criticality before making decisions.
Safe optimization always balances cost and stability.
7. Cross Cloud Workload Placement
Most organizations adopt multi cloud for flexibility. Very few use it strategically.
In many environments, workloads stay where they were originally deployed. An application built in one region remains there for years. A data job runs on the same provider simply because it always has. Placement becomes historical rather than intentional.
But in multi cloud environments, location directly affects cost, performance, and reliability.
Different providers and regions vary in compute pricing, storage costs, network egress fees, latency, and compliance rules. Even small differences become significant at scale. A batch workload might run much cheaper in one region. A customer facing API might need to stay close to users to maintain low latency.
Intelligent placement means continuously asking:
Where should this workload run today?
An AI driven placement engine evaluates workload type, demand patterns, pricing differences, network costs, compliance constraints, and service dependencies. It scores each possible location and selects the one that balances savings with performance and risk.
Here is a simplified scoring example:
def score_region(cost, latency, reliability):
return (0.5 * cost) + (0.3 * latency) - (0.2 * reliability)The goal is not just to reduce cost, but to optimize intelligently. Moving a workload must not increase latency or create hidden egress charges. Good placement decisions always consider long term impact.
For example, a nightly analytics job can shift to a lower cost region without affecting users. A real time API remains in a high performance region. The result is targeted savings without compromising stability.
When done correctly, cross cloud placement turns multi cloud from a passive architecture choice into an active economic strategy. Infrastructure stops being static and becomes adaptive.
And adaptive systems are always more efficient than fixed ones.
Placement becomes strategic when cost differences across regions and providers are significant.
AI evaluates:
- Compute cost differences
- Storage cost tiers
- Network egress charges
- Latency to users
- Compliance restrictions
A simple scoring function:
The lowest score wins.
Batch workloads can shift to lower cost regions. Latency sensitive APIs remain near users.
Dynamic placement transforms cloud from static infrastructure into an adaptive economic system.
8. Automation: Turning Decisions Into Reality
Insights are useless without execution.
Optimization systems integrate with infrastructure as code pipelines.
Terraform example:
variable "instance_type" {}
resource "cloud_instance" "app" {
instance_type = var.instance_type
}Instead of directly modifying infrastructure, AI updates configuration variables. CI pipelines validate changes. Deployment strategies such as canary rollouts minimize risk.
Automation must always include rollback capability.
9. Governance: Control Without Slowing Innovation
When people hear the word governance, they often think of restrictions, approvals, and delays. In cloud environments, governance has traditionally meant slowing things down to reduce risk.
But in autonomous multi cloud systems, governance plays a different role. It does not block innovation. It enables safe optimization at scale.
As AI begins making recommendations about resizing workloads, shifting regions, or adjusting scaling policies, organizations need confidence that those decisions align with business priorities. Governance ensures that cost savings never compromise reliability, compliance, or customer experience.
A well designed governance layer answers four simple questions:
- Is this change within budget guardrails?
- Does it respect compliance and data residency rules?
- Will it impact critical workloads?
- Can it be audited and rolled back if needed?
Instead of acting as a bottleneck, governance becomes a policy engine that runs automatically before execution. For example, production systems may require approval before downsizing, while development environments can be optimized automatically.
Budget guardrails can prevent aggressive changes that might introduce risk. Compliance rules can block workloads from moving outside approved regions. Audit logs capture every decision, who approved it, and what the expected savings were.
The key is balance.
Too little governance creates instability.
Too much governance kills automation.
The right approach embeds governance directly into the optimization pipeline. AI recommends. Policies validate. Automation executes. Monitoring verifies.
This structure allows organizations to move quickly without losing control.
In modern FinOps, governance is not about slowing innovation. It is about building trust so innovation can happen safely.
10. Measuring Success
Optimization sounds impressive in theory. But in practice, it only matters if it delivers real results.
When an AI system recommends resizing servers, shifting workloads, or adjusting scaling policies, the real question is simple: did it actually make things better?
Success in multi cloud optimization comes down to balance. You want lower cost, but not at the expense of reliability or performance. Saving money while increasing latency or causing instability is not success. It is just a different kind of problem.
To measure whether optimization is working, focus on a few meaningful signals:
- Is the cost per transaction decreasing?
- Are idle resources shrinking over time?
- Are scaling predictions accurate?
- Has service reliability remained stable?
- Did the actual savings match what was predicted?
These metrics tell a story. If costs go down and performance remains steady, the system is working. If performance drops or customer experience suffers, something needs to be adjusted.
Measurement also improves intelligence. When predictions are slightly off, the system learns from the gap between expected and actual results. Over time, decisions become more precise.
In the end, measuring success is not about dashboards filled with numbers. It is about proving that optimization improves efficiency without sacrificing stability.
That is when AI driven FinOps becomes truly valuable.
11. The Road Ahead
Cloud environments are not getting simpler. They are becoming more distributed, more dynamic, and more financially complex. Managing cost across multiple providers using manual reviews and static policies will soon feel outdated.
The next phase of multi cloud optimization is continuous intelligence. Systems will not just report inefficiencies. They will predict them, correct them, and learn from the results. Cost will become a real time signal, just like performance or reliability.
We will also see optimization expand beyond price alone. Future systems will consider sustainability, energy efficiency, and long term commitment strategies automatically. Cloud infrastructure will gradually behave less like fixed capacity and more like a responsive economic system.
The organizations that embrace adaptive, AI driven control early will operate leaner and move faster. The future of cloud operations is not more dashboards. It is smarter systems working quietly in the background.
Final Thoughts
AI-based multi cloud cost and resource optimization is not about replacing engineers. It is about giving them intelligent systems that continuously align infrastructure cost with business demand.
The organizations that embrace autonomous FinOps will operate leaner, react faster, and innovate more confidently.
The future of cloud operations is not manual tuning.
It is intelligent adaptation.
Opinions expressed by DZone contributors are their own.
Comments