AI-Powered Product Recommendations With Oracle CDC, Flink, and MongoDB
I’ll show you how I used Oracle, Kafka, Flink, OpenAI, and MongoDB to build a real-time personalization engine from scratch.
Join the DZone community and get the full member experience.
Join For FreePlanning a weekend hike? River Runners has you covered, with lightweight pants, trail shoes, and now, eerily good product recommendations.
Okay, River Runners isn’t real. It’s a fake outdoor running company I created to show how real-time AI can turn any store into something that feels smart and personalized. The kind of experience where the site seems to know what you need before you do.
But behind the scenes, this demo solves a real problem: how do you get fresh data out of an old-school Oracle database and into the hands of a modern AI system? And how do you do it fast enough to recommend the right gear the moment someone clicks?
In this post, I’ll walk you through how I used Oracle, Kafka, Flink, OpenAI, and MongoDB to build a real-time personalization engine from scratch.
Note: Want to skip to the GitHub? Find it here.
The Real Problem: Stale Personalization
When I built River Runners, I didn’t want it to just look like a modern online running store, I wanted it to feel smart. Like it actually knew what you were into and could help you find it, fast.
That’s harder than it sounds.
Many personalization systems are stuck in the past. They rely on batch ETL pipelines that move data hours—or days—after a customer does something. Clicks get processed overnight. Product updates take forever to show up. Recommendations are often based on what someone liked last week, not what they just looked at.
And that just doesn’t work anymore.
People expect real-time suggestions. If I’m browsing sneakers, show me running socks now, not tomorrow. If I just clicked on trail shoes, don’t show me a kayak. The bar has moved, and static recommendation engines can’t keep up.
The real issue is architectural. Most systems are built around databases that were never designed for real-time anything. And Oracle is the perfect example. It’s everywhere—running mission-critical systems across industries—but it wasn’t built with personalization in mind.
Still, that doesn’t mean it’s useless.
With the right approach, you can turn even a legacy Oracle database into the heart of a fast, responsive AI system. But you have to change how you use it. That means skipping the nightly batch jobs and streaming changes as they happen. It means treating data like a live signal, not a historical artifact.
That’s exactly what I set out to do with River Runners: start with a legacy database, and build something that feels like magic.
So, how do you make it work?
What We’re Building: Real-Time Semantic Search for Product Personalization
At the core of this project is a simple goal: make product recommendations that actually feel relevant, based on someone's browsing behavior and its relationship to other products.

River Runners Product Page with Similar Products
To do that, I’m using semantic search, powered by a real-time pipeline that looks a lot like Retrieval-Augmented Generation (RAG).
RAG usually means feeding relevant context into a language model to generate a response. But in this case, I’m not using the LLM to answer questions. I’m using it to enrich product data and generate embeddings, which I store in a vector database.
So while I’m not doing full RAG in the frontend, the pipeline that powers it is doing RAG-style work: CDC → enrichment → embedding → real-time delivery.
No REST calls. No batch jobs. Just live product data transformed into something that AI (and your app) can actually use in the moment.
Let’s look at how the system works.
Inside the System
Turning product data from Oracle into real-time recommendations takes a few key steps. The main idea is to treat data as something alive, streaming through the system, not something we batch and clean up later.
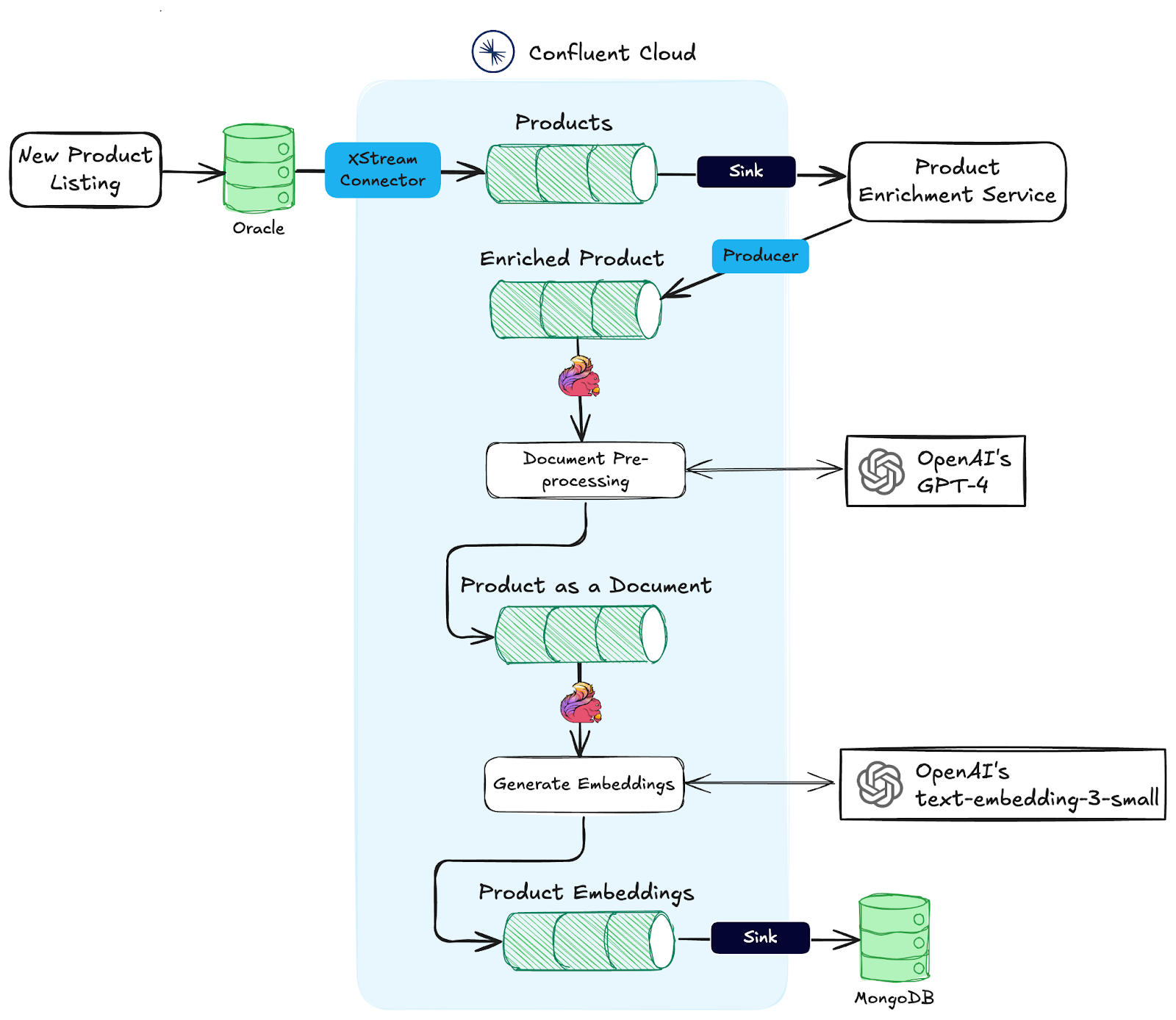
Real-time Data Enrichment and Embedding Pipeline
Here’s how the River Runners pipeline works, end to end:
Add New Product Data
The process begins when new product data is added to the Oracle database. A script is available in the data-ingestion/ project directory to add fake product data for the demo.
Streaming Changes from Oracle
Once new data is added, the Oracle XStream CDC Source Connector captures changes in real time and pushes them to Kafka. This connector leverages Oracle’s XStream Out to deliver high-throughput, low-latency streaming from a traditionally batch-based system.
Kafka as the Backbone
Every change, product updates, user clicks, enrichment results, flows through Kafka topics. Kafka acts as the central event bus that connects the different parts of the system.
Product Enrichment
An HTTP Sink Connector listens to the PROD.SAMPLE.RUNNING_PRODUCTS topic and forwards incoming product records to an enrichment service. This service scrapes the product website and adds additional product details.
Real-Time Enrichment and Embedding
Apache Flink processes the data. It handles both enrichment and embedding in-stream using OpenAI models.
Flink Job 1: Define the Product Description Model
This job sets up a model that uses GPT-4 to turn structured product data into clear, natural descriptions:
CREATE MODEL product_description_model
INPUT(message STRING)
OUTPUT(response STRING)
WITH (
'provider' = 'openai',
'task' = 'text_generation',
'openai.connection' = 'openai-connection',
'openai.model_version' = 'gpt-4',
'openai.system_prompt' = 'You are a helpful AI assistant that specializes in writing product descriptions...'
);
Flink Job 2: Generate Summaries for Each Product
This SQL statement applies the model to incoming product data and writes summaries to the product_as_documents topic:
INSERT INTO product_as_documents
SELECT
CAST(CAST(ID AS STRING) AS BYTES) AS `key`,
ID,
product_summary.response
FROM enriched_running_products
CROSS JOIN LATERAL TABLE (
ml_predict(
'product_description_model',
CONCAT_WS(
' ',
'Name: ', `NAME`,
'Rating: ', CAST(`RATINGS` AS STRING),
'Price: ', `ACTUAL_PRICE`,
'About: ', REGEXP_REPLACE(CAST(about_this_item AS STRING), '\\[|\\]', ''),
'Product Description: ', product_description,
'Product Details: ', REGEXP_REPLACE(CAST(product_details AS STRING), '\\{|\}', '')
)
)
) AS product_summary;
Flink Job 3: Generate Vector Embeddings
CREATE MODEL vector_encoding
INPUT (input STRING)
OUTPUT (vector ARRAY<FLOAT>)
WITH (
'TASK' = 'embedding',
'PROVIDER' = 'openai',
'OPENAI.CONNECTION' = 'openai-embedding-connection'
);
INSERT INTO product_embeddings
SELECT
CAST(CAST(id AS STRING) AS BYTES) AS `key`,
embedding,
id,
product_summary
FROM product_as_documents,
LATERAL TABLE (
ml_predict(
'vector_encoding',
product_summary
)
) AS T(embedding);
Enabling Semantic Search
Emeddings stored in MongoDB, which is configured with a vector index. This enables fast lookup of semantically similar items, so when a user clicks a product, we can easily find related ones based on meaning.
Tracking Clicks and Recommending Products
When users interact with the site, click events are streamed to Kafka. These are used to trigger semantic search queries based on the embedding of the clicked product. The vectors representing the last set of customer interactions are averaged and the averaged vector is used to search the vector store with, finding the most relevant products based on semantic search and historical interactions.
Frontend Display
A Next.js app acts as the storefront. It shows the product catalog, tracks interactions, and displays personalized recommendations in real time, based on product details in Oracle, embeddings and search results from MongoDB.
And that’s it. No batch jobs. No daily rebuilds. Just a live pipeline that streams product data from Oracle, enriches it, embeds it, and turns it into real-time recommendations on the frontend.
Why This Matters and What’s Next
Most recommendation systems still run on delay. They depend on overnight jobs, stale data, and rules that don’t adapt. That’s fine if you're recommending books in a library. But in the real world, where people click, scroll, and expect quick responses, it falls apart.
This project shows that you can do better. You can start with a legacy Oracle database and still build something that reacts in real time. That makes smarter suggestions. That feels like it’s actually paying attention.
And it doesn’t have to stop here.
You could:
- Let users shape recommendations by clicking “not interested” or “show me more like this”
- Add simple user profiles to steer results over time
- Track browsing sessions, not just single clicks
- Build agents that flag low-stock items or surface products you’ve overlooked
- Reuse the same pattern for support bots, pricing alerts, or internal tools
The point isn’t to be fancy. It’s to be useful. And once you have the basics in place, streaming changes, processing them in real time, and searching by meaning, you can build whatever you need on top.
River Runners is a fake store. But the ideas behind are real and you could build it today.
Published at DZone with permission of Sean Falconer. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments