An Approach to Process Skewed Dataset in High Volume Distributed Data Processing
This article explains an approach to processing skewed datasets by identifying the skewed portion of the dataset and solving it using an efficient and optimal approach.
Join the DZone community and get the full member experience.
Join For FreeIn the modern computing landscape, we have a lot of advancement and rapid development in the field of computing. The processing paradigm is changing so frequently with so many distributed processing software available in the market. These software provides powerful features to process voluminous data with a very scalable architecture, thus providing flexibility to dynamically scale up and scale down depending on the processing needs.
Many of these distributed software are used by organizations as part of tech modernization initiatives to replace their old legacy applications to gain benefits leveraging scalability and cloud-native features and processing data faster using modern processing techniques.
Modern distributed processing software provides powerful and scalable features for processing voluminous data sets and data streams. Distributed Data processing for analytics is a rapidly expanding ecosystem in every medium to large-scale and innovative organization. All these enterprises are putting a lot of emphasis and focus on this area to have a scalable and highly performant system in place to process voluminous datasets with many complex data processing needs.
While these software applications are designed for high-performance data processing, there can be processing scenarios where you may encounter performance issues. In this article, I will discuss one of the key performance challenges encountered with distributed processing applications and a few potential solutions to resolve the performance bottleneck. The issue is related to non-uniform data distribution across your job; it can lead to imbalanced task execution and performance bottlenecks. This issue can arise in any kind of processing, for example, with data aggregation and summarization tasks like group reduction tasks or processing tasks where we are joining big datasets to extract the meaningful information after connecting the voluminous datasets. In this situation, the voluminous dataset to be processed is highly skewed, which leads to non-uniform data distribution across processing nodes and thus results in inefficient and degraded processing timelines. Such uneven data distribution can cause lower throughput and higher end-to-end latency. Pipelines can fail and can lead to memory overruns and eventually into crash loops.
The applications built leveraging the modern distributed software are turning out to be successful and meeting organizations' needs to support the changing data dynamics where much more data is produced every day and processed to extract meaningful insights used for multiple purposes. These modern tech stacks have few challenges when the data it has to process is not consistent and uniform for distributed processing framework and is highly skewed, thus resulting in challenges for distributed processing design.
This article will specifically focus on data skewness-related challenges in the distributed processing paradigm. As mentioned in the abstract section, skewness can lead to critical problems and can even lead to process failure. There are various popular solutions to resolve data skewness and process data optimally utilizing the full capability of the underlying distributed infrastructure. The few most prominent solutions are listed below:
- Salting: In this technique, the key is extended by adding a randomized value to the key to help uniformly distribute the data across task slots to remove skewness. This technique might work well for some kinds of operations like group reduction but is a challenge to implement for other kinds like join operations where the same random value must be added to the key on both datasets to ensure the join is still working as expected. This can be done if we are using distributed SQL for processing but will be a challenge for other scenarios, for example, if we have written a framework with a generic join framework for distributed processing.
- Reshuffle: In this technique, the reshuffling operation is invoked for a skewed dataset to explicitly break fused operators and redistribute the data to underutilized nodes. But one word of caution with this technique is to use reshuffling only when necessary, as it is a double-edged sword that shouldn’t be used everywhere. Again, this might work with aggregation operations but not be very effective for skewed Join operations.
- Redesign the data distribution logic for a skewed dataset: In this approach, the distribution of the dataset across task slots for distributed processing is revisited to have a multi-step distribution strategy to devise a way to distribute processing logic as well. This strategy has a drawback: by moving the data multiple times, we add the risk of more data transfer within the network, which can degrade the pipeline’s performance. This approach is advantageous for use cases and situations requiring voluminous data processing for every node in the distributed cluster, and moving data has inconsequential overhead as compared to processing data. Again, this strategy might work for specific processing scenarios but not for all scenarios.
This article will focus on discussing a few of the top processing challenges encountered by these modern distributed processing applications with elaborate use cases and examples. Also, I will recommend a few processing strategies to resolve the processing challenge. These processing challenges discussed in this article will be pertinent to voluminous data processing leveraging distributed software where the voluminous dataset will be distributed and processed.
Below is one major problem encountered in distributed processing applications built on top of software like Apache Spark, Apache Storm, Apache Hadoop, Flink, Samza, Beam, etc.
In my experience during the tech modernization initiatives, I encountered challenges with processing skewed datasets. While using distributed software to design applications to process high-volume datasets with predominant processing use-cases like Joins of big datasets, complex transformations, and aggregation of data to produce summarized outputs. In these kinds of processing use cases, specifically with high-volume datasets, having skewed data was a major challenge for processing. As we leveraged the scaling of the application to distribute the processing across multiple worker nodes, the skewed dataset proved to be a major performance hurdle.
It's paramount to state that performance concerns can have multiple underlying causes, and detecting and resolving the performance issues require a coordinated approach, including performance profiling, monitoring, and analysis. It's suggested to leverage monitoring and profiling capabilities to gather performance metrics and detect problematic areas that need optimization.
One example we will discuss in this article is Join operations for skewed datasets where the data distribution across processing slots is based on Join keys. These join keys are not able to uniformly distribute the datasets across processing slots, thus leading to cardinality spikes. The problem arises when a few of the join keys have having bulk of the data associated with it. The processing slots that will have those keys assigned will have all the associated data going to those slots, and the remaining larger portion of the join keys having lesser data associated with it will only get assigned a smaller portion of the datasets. This results in data skewness and non-uniform distribution of data across processing slots. The main reason for the data skewness is cardinality explosion, which lead to many other adverse repercussions and, in the worst case, can lead to process failure.
To explain the problem statement better, I will take an example where 85% of records in the datasets are linked to only 10% of Join keys. In this scenario, with distributed processing leveraging multiple nodes, 85% portion of the data will go to 10% of the nodes as the join operation will be distributing the datasets across processing nodes based on the join keys. As join keys will be distributed uniformly across processing slots, the majority of the nodes processing 90% of the join keys will finish fast as they will have only 15% of the data from the bigger datasets and the remaining 10% of join keys, which, we said is having 85% of the datasets associated with it will have to process the 85% of the skewed portion of the voluminous dataset. This will result in the processing nodes assigned this 10% of the join keys running longer and will struggle to process high volume with limited resources when other nodes assigned the 90% of join keys are left idle after finishing their processing with the smaller portion of the voluminous dataset. This brings down the overall execution efficacy of the job. Also, skewed datasets may cause memory overruns on certain executors, leading to the failure of the jobs. The memory overrun might happen in the scenario where a few of the join keys have the majority of the data associated with them. One join key is having, say, 20 million records from one dataset having the same join key. In this scenario, all the 20 million records will go to the same processing node irrespective of how much the parallelism is for the processing. If the node memory is not enough to process 20 million volumes, it might run into memory overruns and might lead to process failure. This will be the worst outcome for any production run and might require immediate resolution.
We will take this example further by defining the problem statement using an actual data scenario. In the below problem statement, we have two voluminous datasets that need to be joined, and the outcome of the join will be used to pick the required attributes from both datasets for subsequent processing.
In the below use case, I will give one example scenario with some number statistics to illustrate the problem. This will help us to get a better understanding of the impact and bottleneck caused by the skewed dataset problem. I will also propose a solution that can be envisioned and developed as a generic and reusable resolution to the problem, thus eliminating the bottleneck for any such use case having to deal with a skewed dataset join problem.
I will start with a pictorial representation of the skewed dataset join processing scenario:

In the above pictorial representation of Join operations between two dataset scenarios, the first data set has around 170 million records, and the second data set is comparatively smaller, with around 35 million volumes. The two datasets are joined based on the standard join key, and a few join keys from the second dataset have an excessively large number of records with the same value of the join key compared to others from the first dataset. When the distributed software performs the join between these two datasets. The data is distributed across processing slots based on the join keys, and all records having the same join keys are allocated to the same processing slot from both datasets.
This results in skewness for a few of the processing slots, which are assigned the keys having a disproportionate amount of data from the first dataset. In the above diagram, we have shown a few joins happening across multiple processing slots. Let’s keep it simple and say every slot is assigned two join keys.
Task slot one is assigned two join keys for which the first dataset has five million and four million records, respectively, against a single record from the second dataset. This results in this task slot processing nine million records for the join operation.
For the second task slot and the remaining task slot after the third slot, the join criteria do not create a skewed dataset. Data from the first dataset is not that high, and only a few hundred records have the same join key against one record in the second dataset.
Again, in the third processing slot, the two join keys assigned to this task slot have 11 million and nine million records, respectively, against a single from the second dataset. This results in this task slot processing 20 million records for the join operation.
In a nutshell, the problem with this join operation is the non-uniform allocation of data for processing join operation across all the available processing slots; every slot is assigned an equal number of join keys. Now, the slots with skewed dataset against the assigned join key will have to deal with high volume data Vis-à-Vis slots with non-skewed dataset for the join keys. In the above diagram, slots first and three must deal with this situation and will have to process high volume compared to other slots like the second slot and all the slots after the third till the last nth slot with only a few hundred records assigned to them. All slots have similar resources and infrastructure, so slots two and all slots after the third till the last slot will complete the processing quickly and will be sitting idle. In contrast, slots one and three will continue to process the data for a more extended period. In this scenario, we are not able to leverage the distributed infrastructure optimally. We will have to process for a longer period, resulting in degraded performance when we have idle, available slots but cannot leverage them to accelerate the processing and optimize the performance.
In this situation, though the number of join keys is equally distributed across processing nodes, few join keys have uniform distribution, and other sets of join keys have a skewed portion of the data matching the join keys, thus resulting in a higher volume of the data going to those processing slots. This scenario is common when we are performing join operations on a skewed dataset. This situation will result in longer processing cycles. It will lead to backpressure and higher memory allocation, and possibly memory overrun, too, for the processing nodes, which will be dealing with a high volume portion of the datasets.
This situation will also arise for aggregation and summarization operations where we must perform certain summarization on high-volume datasets. The summarization key again results in skewed datasets where some keys will produce a bigger portion of the dataset matching the skewed summarization keys, and other sets of keys have having lesser subset of data matching the keys. In this situation, we must come up with a solution that can resolve the data skewness. We will help leverage all processing nodes to process data uniformly, thus resulting in accelerated performance and higher throughput from distributed infrastructure.
To solve this problem, we are proposing a few custom solutions that can be contemplated and pondered based on use case to use case, and the ideal solution should be picked up to resolve these issues. In this proposed approach, the key to solving the puzzle is determining which dataset in your join operation is causing the skewness. Skewness usually is encountered when certain keys have an excessively large number of records compared to others, and this leads to most of the dataset being linked to a certain set of keys, and the remaining portion of the dataset is uniformly linked to the remaining set of keys. The first step is to determine those set of keys which has a large set of records.
One custom solution is depicted and explained below diagram, where the skewed portion of the voluminous dataset is processed using broadcast operation by equally distributing it across all the worker slots, and the non-skewed portion of the dataset is processed using normal join operation, and as the second portion is non-skewed so it will be uniformly distributed across all the worker slots and thus will be able to leverage all the slots resources optimally:

- Based on the Join key used to connect the two datasets, determine the top keys that have a disproportionately large number of records associated with it from the first dataset. Determine all the keys that have skewed linkage from the first dataset.
- Next, based on the identified set of keys from Step one above, we can break the first dataset into two parts: the first part is the one that has all the skewed keys, and the second part is the one that has all the non-skewed portion for the keys other than the keys identified in the first step above. It will look something like below:
- The first dataset records where the join key attribute is (all the skewed join keys have large volumes linked to the join key).
- The first dataset records where the join key attribute is not in (all the skewed join keys have large volumes linked to the join key).
- The same can be done for the second dataset to break the dataset into two parts – the first part having records having the join key identified in step 1 above and the second part having the join key not in the join key identified in step 1 above.
- After identifying the skewed portion of the first bigger dataset, we need to process it using broadcast with the matching records from the second dataset from step 2 above. The second data set containing the keys will be very small in volume as not all the data will be skewed, so we envisage that only 1 to 5% of the importance of the second dataset will fall into this category and can be used as broadcast and will be made available to all the task slots. In this way, the skewed portion of the first dataset can be uniformly distributed across task slots and will be used to join the second dataset using broadcast join. This will result in uniform processing of the skewed dataset, leveraging all the task slots equally and thus resulting in accelerated processing of the skewed dataset.
- The remaining portion of the bigger dataset, which is not skewed, can be processed using the regular join operation with the second dataset using the join key. This join will perform optimally, and data from both datasets will be distributed uniformly across all the task slots as the join is not skewed.
- Post the join operation performed for a skewed dataset using broadcast and non-skewed using regular join, both the resultant datasets will be joined together. They will result in producing the complete join dataset.
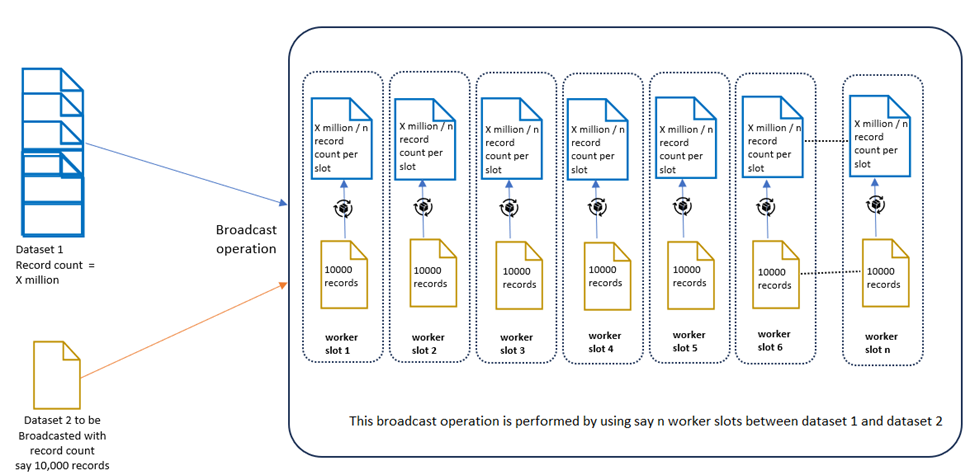
This approach uses a hybrid solution where both the Join operation and Broadcast operation are used to solve the complete dataset join operations. Below, all the above-mentioned high-level steps are explained in detail:
The crucial factor to solve the problem with the approach mentioned above is to determine the skewed dataset from the bigger dataset and the corresponding join key records from the second smaller dataset. This helps to get insight into the data distribution, determine how to handle the skewed dataset and segregate the skewed portion of the dataset from the non-skewed dataset portion.
Conclusion
Technology is advancing at a very rapid pace, and distributed processing frameworks are taking a dominant position and are used to process voluminous data to extract meaningful information. While these frameworks are highly optimized but, few of the challenges associated with high-volume processing can be solved efficiently by leveraging innovative techniques and approaches. This article explained one such approach, which could prove to be very beneficial to processing skewed datasets by identifying the skewed portion of the dataset and solving it using a different optimal approach. The main idea used to solve the problem is to identify the concern and separate the concern to be solved in a different manner, which aligns with the skewed dataset structure to be distributed evenly across all the nodes of the cluster and leverage all the nodes to process the dataset optimally. I hope the approach discussed in this article will help organizations overcome the challenge associated with processing high-volume skewed datasets.
Opinions expressed by DZone contributors are their own.
Comments