An Introduction to Microservices
Learn everything you need to know about microservices, like their architecture, the best coding languages, and how they make calls.
Join the DZone community and get the full member experience.
Join For FreeWhat Is a Microservice?
Microservices are small, autonomous programs that function as both data producers and data consumers, particularly between service boundaries within a virtualized cloud environment. 100-200 individual microservices might be used to render a single Amazon web page, for example. Microservices are a new type of vector into secured networked assets.
Microservices can be coded in a variety of languages that are often, but not always, dependent upon the cloud infrastructure in which the microservice resides. In addition, there is no reason why a microservice programmed in C# can’t be designed to talk to another microservice written in Python. The most common languages used to create microservices are Python, Java, Ruby, C#, PHP, JavaScript, Elixir, and Go.
At a fundamental level, microservices expose a limited API, which provides a simple set of related functionalities that, by design, are “loosely coupled” with other collaborating services. Coupling refers to the degree of direct knowledge that one component has of another. Messages consist of instructions bound in metadata and encoded in a data-interchange format such as JSON. Other components such as testing or monitoring stubs are also typically present in a particular microservice.
To better understand microservices, you need to understand some of the basic jargon.
The fundamental components of a microservice consists of
- Message Dispatcher or more simply, a Producer, which publishes messages to a service bus;
- An Event Listener or Consumer, which receives messages from service bus; and
- Business logic (the data that passes between Producers and Consumers).
In addition, most microservice implementations rely upon some type of message broker – typically a library that provides a message queue and an exchange. You can think of a message queue as a buffer or an array of n length. An exchange consists of the logic that receives messages from producers and pushes them into the correct queue(s). There are different classes of exchanges but we won’t detail them here.
Let’s look at some pictures to better understand these relationships.
A producer is simply a service that sends data. We’ll signify it as a circle with a P inside.
A consumer is a service that receives and performs some operation on data such as rendering a PDF file. We’ll represent this as a circle with a C inside.
An exchange pushes data from the producer into a queue. We’ll use a yellow circle with an X inside to represent this.
We’ll represent a queue as a row of blue boxes.
One of the two most common microservice patterns are work queues, which distribute tasks among different workers. We can represent this pattern as follows:
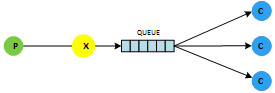
The producer, in this case, might be a web-based button that submits customer information that is acted upon in some fashion by the back-end consumers.
The second most common pattern is known as publish/subscribe or PubSub. This pattern allows consumers to subscribe to data or events created by a producer. The pattern is shown below.
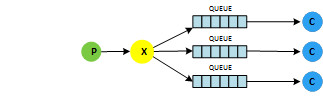
Unlike message queues, where data is pushed to specific consumers, the PubSub pattern allows the producer to queue data without knowing which, if any, consumers will receive the data. Consumers, depending upon their mission, can subscribe to many producers.
Other microservice patterns exist, but these two are far and away the most common messaging patterns in use in the AWS cloud. In most cases, these patterns rely upon one or more RPC calls. We’ll get to RPC in a moment.
Microservices allow flexibility in terms of infrastructure and deployment; application traffic is routed to collections of services that may be distributed across CPU’s, disks, machines and networks as opposed to a single monolithic platform designed to manage all traffic. In a fashion similar to the object-oriented (OO) notion of encapsulation, the primary advantages of loosely coupled microservices is that deployment times are reduced, since theoretically any cooperating microservice contract can be replaced with an alternative that provides the same service(s) without redeploying or re-architecting any other collaborating microservice. Additionally, as mentioned earlier, microservices in a loosely coupled system are less constrained to the same platform, language, operating system, or build environment.
Remote Procedure Calls
A remote procedure call (RPC) refers to the programmer’s technique of making a local call and having it execute on a remote collaborator somewhere. Specifically, this involves calling a function (or a method in OO lingo) that resides on another device or across a service boundary.
A typical RPC call in the context of a microservice pattern can be visualized as follows:
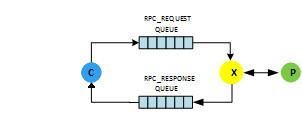
Typically, an RPC call utilizes a delegate as part of the callback process. One way to think of a delegate is to imagine the following conversation between two strangers:
Alice: "Hi, Joe. I know just met you, but here’s my number (delegate). If you decide to meet me for a vegan milkshake (event), please let me know (callback)."
There are a number of different flavors of RPC technology in use today. The core idea of RPC is to hide the complexity of the remote call. Personally, I think that many RPC implementations hide too much. The goal in most forms of RPC is to make remote method calls look like local method calls, and this can hide the fact that these are two very different things.
For example, I can make large numbers of local, in-process calls without overly worrying about performance or the nature of the service bus. With RPC, though, the cost of marshaling and unmarshaling payloads can be significant, not to mention the latency involved when payloads are sent over an IP network.
IP, as we all know, was not designed for speed or security.
An array of RPC options exist that allow one microservice to talk with another. These include SOAP, Thrift, XML-RPC, Google protocol buffers, REST, JSON, and most popularly, JAVA-RMI.
Many of these protocols are binary in nature, like Java RMI, Thrift, Google protocol buffers, or BSON. The fact that these are not human readable, much like the older Abstract Syntax Notation (ASN) makes them less popular targets for hackers. On the other hand, SOAP uses XML for its message formats. REST, JSON and others are human readable. Many of these implementations are tied to a specific networking protocol (like SOAP or REST, which make nominal use of HTTP), whereas others might allow one to use a different layer of the network stack, like TCP or UDP, which themselves can provide both additional features and additional potential vulnerabilities.
Remote procedure calls in both the UNIX, Linux and Microsoft operating systems have long been a favorite target for hackers because RPC services are required to register with the portmapper (rpcbind in Sun’s SVR4) service, located conveniently on TCP/UDP port 111, and because many of the RPC services are or were vulnerable to a range of exploits (just google “DCOM exploits). One of the first commands a pen-tester or evil-doer would make to a remote system was “rpcinfo -p”.
In the next installment of this article, we'll talk about "hacking" the RPC calls in microservices.
Opinions expressed by DZone contributors are their own.
Comments