An Overview of Data Pipeline Architecture
Dive into how a data pipeline helps process enormous amounts of data, key components, various architecture options, and best practices for maximum benefits.
Join the DZone community and get the full member experience.
Join For FreeIn today's data-driven world, organizations rely heavily on the efficient processing and analysis of vast amounts of data to gain insights and make informed decisions. At the heart of this capability lies the data pipeline — a crucial component of modern data infrastructure. A data pipeline serves as a conduit for the seamless movement of data from various sources to designated destinations, facilitating its transformation, processing, and storage along the way.
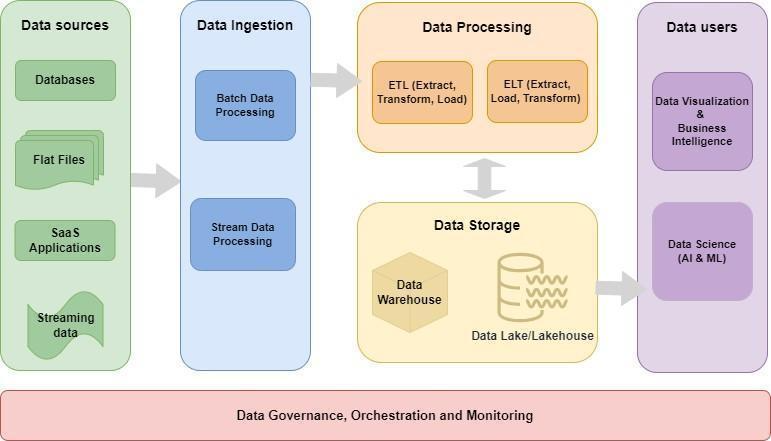
The data pipeline architecture diagram above depicts a data pipeline architecture, showcasing the flow of data from diverse sources such as databases, flat files, and application and streaming data. The data travels through various stages of processing, including ingestion, transformation, processing, storage, and consumption, before reaching its final destination. This visual representation highlights how the data pipeline facilitates the efficient movement of data, ensuring its integrity, reliability, and accessibility throughout the process.
Check Out Free Course to Learn More: "Introduction to Data Engineering"*
*Affiliate link. See Terms of Use.
What Is Data Pipeline Architecture?
Data pipeline architecture encompasses the structural design and framework employed to orchestrate the flow of data through various components, stages, and technologies. This framework ensures the integrity, reliability, and scalability of data processing workflows, enabling organizations to derive valuable insights efficiently.
Importance of Data Pipeline Architecture
Data pipeline architecture is vital for integrating data from various sources, ensuring its quality and optimizing processing efficiency. It enables scalability to handle large volumes of data and supports real-time processing for timely insights. Flexible architectures adapt to changing needs, while governance features ensure compliance and security. Ultimately, data pipeline architecture enables organizations to derive value from their data assets efficiently and reliably.
Evolution of Data Pipeline Architecture
Historically, data processing involved manual extraction, transformation, and loading (ETL) tasks performed by human operators. These processes were time-consuming, error-prone, and limited in scalability. However, with the emergence of computing technologies, early ETL tools began automating and streamlining data processing workflows.
As the volume, velocity, and variety of data increased, there was a growing need for real-time data processing capabilities. This led to the development of stream processing frameworks and technologies, enabling continuous ingestion and analysis of data streams. Additionally, the rise of cloud computing introduced new paradigms for data processing, storage, and analytics. Cloud-based data pipeline architectures offered scalability, flexibility, and cost-efficiency, leveraging managed services and serverless computing models.
With the proliferation of artificial intelligence (AI) and machine learning (ML) technologies, data pipeline architectures evolved to incorporate advanced analytics, predictive modeling, and automated decision-making capabilities.
As data privacy regulations and compliance requirements became more stringent, data pipeline architectures evolved to prioritize data governance, security, and compliance, ensuring the protection and privacy of sensitive information.
Today, data pipeline architecture continues to evolve in response to advancements in technology, changes in business requirements, and shifts in market dynamics. Organizations increasingly adopt modern, cloud-native architectures that prioritize agility, scalability, and automation, enabling them to harness the full potential of data for driving insights, innovation, and competitive advantage.
Components of a Data Pipeline Architecture
A robust data pipeline architecture comprises several interconnected components, each fulfilling a pivotal role in the data processing workflow:
| Component | Definition | Examples |
|---|---|---|
|
Data sources |
Data sources serve as the starting point of the pipeline where raw data originates from various channels. |
|
|
Data processing engines |
Processing engines transform and process raw data into a usable format, performing tasks such as data cleansing, enrichment, aggregation, and analysis. |
|
|
Storage systems |
Storage systems provide the infrastructure for storing both raw and processed data, offering scalability, durability, and accessibility for storing vast amounts of data. |
|
|
Data destinations |
Data destinations are the final endpoints where processed data is stored or consumed by downstream applications, analytics tools, or machine learning models. |
|
|
Orchestration tools |
Data pipeline orchestration tools manage the flow and execution of data pipelines, ensuring that data is processed, transformed, and moved efficiently through the pipeline. These tools provide scheduling, monitoring, and error-handling capabilities. |
|
|
Monitoring & logging |
Monitoring and logging components track the health, performance, and execution of data pipelines, offering visibility into pipeline activities, identifying bottlenecks, and troubleshooting issues. |
|
Six Stages of a Data Pipeline
Data processing within a pipeline travels through several stages, each contributing to the transformation and refinement of data. The stages of a data pipeline represent the sequential steps through which data flows — from its ingestion in raw form to its storage or consumption in a processed format. Here are the key stages of a data pipeline:
| STAGE | Definition | Use Cases |
|---|---|---|
|
Data ingestion |
Involves capturing and importing raw data from various sources into the pipeline. |
|
|
Data transformation |
Involves cleansing, enriching, and restructuring raw data to prepare it for further processing and analysis. |
|
|
Data processing |
Encompasses the computational tasks performed on transformed data to derive insights, perform analytics, or generate actionable outputs. |
|
|
Data storage |
Involves persisting processed data in designated storage systems for future retrieval, analysis, or archival purposes. |
|
|
Data movement |
Refers to the transfer of data between different storage systems, applications, or environments within the data pipeline. |
|
|
Data consumption |
Involves accessing, analyzing, and deriving insights from processed data for decision-making or operational purposes. |
|
By traversing through these stages, raw data undergoes a systematic transformation journey, culminating in valuable insights and actionable outputs that drive business outcomes and innovation.
Data Pipeline Architecture Designs
Several architectural designs cater to diverse data processing requirements and use cases, including:
ETL (Extract, Transform, Load)
ETL architectures have evolved to become more scalable and flexible, with the adoption of cloud-based ETL tools and services. Additionally, there's been a shift towards real-time or near-real-time ETL processing to enable faster insights and decision-making.
Benefits:
- Well-established and mature technology.
- Suitable for complex transformations and batch processing.
- Handles large volumes of data efficiently.
Challenges:
- Longer processing times for large data sets.
- Requires significant upfront planning and design.
- Not ideal for real-time analytics or streaming data.
ELT (Extract, Load, Transform)
ELT architectures have gained popularity with the advent of cloud-based data warehouses like Snowflake and Google BigQuery, which offer native support for performing complex transformations within the warehouse itself. Additionally, ELT pipelines have become more scalable and cost-effective due to advancements in cloud computing.
Benefits:
- Simplifies the data pipeline by leveraging the processing power of the target data warehouse.
- Allows for greater flexibility and agility in data processing.
- Well-suited for cloud-based environments and scalable workloads.
Challenges:
- May lead to increased storage costs due to storing raw data in the target data warehouse.
- Requires careful management of data quality and governance within the target system.
- Not ideal for complex transformations or scenarios with high data latency requirements.
Streaming Architectures
Streaming architectures have evolved to handle large data volumes and support more sophisticated processing operations. They have integrated with stream processing frameworks and cloud services for scalability and fault tolerance.
Benefits:
- Enables real-time insights and decision-making.
- Handles high-volume data streams with low latency.
- Supports continuous processing and analysis of live data.
Challenges:
- Requires specialized expertise in stream processing technologies.
- May incur higher operational costs for maintaining real-time infrastructure.
- Complex event processing and windowing can introduce additional latency and complexity.
Zero ETL
Zero ETL architectures have evolved to support efficient data lake storage and processing frameworks. They have integrated with tools for schema-on-read and late-binding schema to enable flexible data exploration and analysis.
Benefits:
- Simplifies data ingestion and storage by avoiding upfront transformations.
- Enables agility and flexibility in data processing.
- Reduces storage costs by storing raw data in its native format.
Challenges:
- May lead to increased query latency for complex transformations.
- Requires careful management of schema evolution and data governance.
- Not suitable for scenarios requiring extensive data preparation or complex transformations.
Data Sharing
Data sharing architectures have evolved to support secure data exchange across distributed environments. They have integrated with encryption, authentication, and access control mechanisms for enhanced security and compliance.
Benefits:
- Enables collaboration and data monetization opportunities.
- Facilitates real-time data exchange and integration.
- Supports fine-grained access control and data governance.
Challenges:
- Requires robust security measures to protect sensitive data.
- Complex integration and governance challenges across organizations.
- Potential regulatory and compliance hurdles in sharing sensitive data.
Each architecture has its own unique characteristics, benefits, and challenges, enabling organizations to choose the most suitable design based on their specific requirements and preferences.
How to Choose a Data Pipeline Architecture
Choosing the right data pipeline architecture is crucial for ensuring the efficiency, scalability, and reliability of data processing workflows. Organizations can follow these steps to select the most suitable architecture for their needs:
1. Assess Data Processing Needs
- Determine the volume of data you need to process. Are you dealing with large-scale batch processing or real-time streaming data?
- Consider the types of data you'll be processing. Is it structured, semi-structured, or unstructured data?
- Evaluate the speed at which data is generated and needs to be processed. Do you require real-time processing, or can you afford batch processing?
- Evaluate the accuracy and reliability of your data. Are there any data integrity concerns that should be resolved prior to processing?
2. Understand Use Cases
- Identify the types of analyses you need to perform on your data. Do you need simple aggregations, complex transformations, or predictive analytics?
- Determine the acceptable latency for processing your data. Is real-time processing critical for your use case, or can you tolerate some delay?
- Consider the integration with other systems or applications. Do you need to integrate with specific cloud services, databases, or analytics platforms
- Based on your requirements, use cases, and considerations regarding scalability, cost, complexity, and latency, it is essential to determine the appropriate architecture design.
- Evaluate the above discussed architectural designs and select the one that aligns best with your needs and objectives.
- It is crucial to choose an architecture that is flexible, scalable, cost-effective, and capable of meeting both current and future data processing requirements.
3. Consider Scalability and Cost
- Evaluate the scalability of the chosen architecture to handle growing data volumes and processing requirements.
- Ensure the architecture can scale horizontally or vertically as needed.
- Assess the cost implications of the chosen architecture, including infrastructure costs, licensing fees, and operational expenses. Choose an architecture that meets your performance requirements while staying within budget constraints.
4. Factor in Operational Considerations
- Consider the operational complexity of implementing and managing the chosen architecture. Ensure you have the necessary skills and resources to deploy, monitor, and maintain the pipeline.
- Evaluate the reliability and fault tolerance mechanisms built into the architecture. Ensure the pipeline can recover gracefully from failures and handle unexpected errors without data loss.
5. Future-Proof Your Decision
- Choose an architecture that offers flexibility to adapt to future changes in your data processing needs and technology landscape.
- Ensure the chosen architecture is compatible with your existing infrastructure, tools, and workflows. Avoid lock-in to proprietary technologies or vendor-specific solutions.
By carefully considering data volume, variety, velocity, quality, use cases, scalability, cost, and operational considerations, organizations can choose a data pipeline architecture that best aligns with their objectives and sets them up for success in their data processing endeavors.
Best Practices for Data Pipeline Architectures
To ensure the effectiveness and reliability of data pipeline architectures, organizations should adhere to the following best practices:
- Modularize workflows: Break down complex pipelines into smaller, reusable components or modules for enhanced flexibility, scalability, and maintainability.
- Implement error handling: Design robust error handling mechanisms to gracefully handle failures, retries, and data inconsistencies, ensuring data integrity and reliability.
- Optimize storage and processing: Strive to strike a balance between cost-effectiveness and performance by optimizing data storage and processing resources through partitioning, compression, and indexing techniques.
- Ensure security and compliance: Uphold stringent security measures and regulatory compliance standards to safeguard sensitive data and ensure privacy, integrity, and confidentiality throughout the pipeline.
- Continuous monitoring and optimization: Embrace a culture of continuous improvement by regularly monitoring pipeline performance metrics, identifying bottlenecks, and fine-tuning configurations to optimize resource utilization, minimize latency, and enhance overall efficiency.
By embracing these best practices, organizations can design and implement robust, scalable, and future-proof data pipeline architectures that drive insights, innovation, and strategic decision-making.
Real World Use Cases and Applications
In various industries, data pipeline architecture serves as a foundational element for deriving insights, enhancing decision-making, and delivering value to organizations. Let's explore some exemplary use cases across healthcare and financial services domains:
Healthcare
Healthcare domain encompasses various organizations, professionals, and systems dedicated to maintaining and improving the health and well-being of individuals and communities.
Electronic Health Records (EHR) Integration
Imagine a scenario where a hospital network implements a data pipeline architecture to consolidate EHRs from various sources, such as inpatient and outpatient systems, clinics, and specialty departments. This integrated data repository empowers clinicians and healthcare providers with access to comprehensive patient profiles, streamlining care coordination and facilitating informed treatment decisions. For example, during emergency department visits, the data pipeline retrieves relevant medical history, aiding clinicians in diagnosing and treating patients more accurately and promptly.
Remote Patient Monitoring (RPM)
A telemedicine platform relies on data pipeline architecture to collect and analyze RPM data obtained from wearable sensors, IoT devices, and mobile health apps. Real-time streaming of physiological metrics like heart rate, blood pressure, glucose levels, and activity patterns to a cloud-based analytics platform enables healthcare providers to remotely monitor patient health status. Timely intervention can be initiated to prevent complications, such as alerts for abnormal heart rhythms or sudden changes in blood glucose levels, prompting adjustments in medication or teleconsultations.
Financial Services
Financial services domain encompasses institutions, products, and services involved in managing and allocating financial resources, facilitating transactions, and mitigating financial risks.
Fraud Detection and Prevention
A leading bank deploys data pipeline architecture to detect and prevent fraudulent transactions in real-time. By ingesting transactional data from banking systems, credit card transactions, and external sources, the data pipeline applies machine learning models and anomaly detection algorithms to identify suspicious activities. For instance, deviations from a customer's typical spending behavior, such as transactions from unfamiliar locations or unusually large amounts, trigger alerts for further investigation, enabling proactive fraud prevention measures.
Customer Segmentation and Personalization
In the retail banking sector, data pipeline architecture is utilized to analyze customer data for segmentation and personalization of banking services and marketing campaigns. By aggregating transaction history, demographic information, and online interactions, the data pipeline segments customers into distinct groups based on their financial needs, preferences, and behaviors. For example, high-net-worth individuals can be identified for personalized wealth management services, or relevant product recommendations can be made based on past purchasing behavior, enhancing customer satisfaction and loyalty.
In conclusion, the data pipeline architecture examples provided underscore the transformative impact of data pipeline architecture across healthcare and financial services industries. By harnessing the power of data, organizations can drive innovation, optimize operations, and gain a competitive edge in their respective sectors.
Future Trends in Data Pipeline Architecture
As technology continues to evolve, several emerging trends are reshaping the future landscape of data pipeline architecture, including:
- Serverless and microservices: The ascendancy of serverless computing and microservices architectures for crafting more agile, scalable, and cost-effective data pipelines.
- AI and ML integration: The convergence of artificial intelligence (AI) and machine learning (ML) capabilities into data pipelines for automating data processing, analysis, and decision-making, thereby unlocking new realms of predictive insights and prescriptive actions.
- Blockchain: The integration of blockchain technology to fortify data security, integrity, and transparency, particularly in scenarios involving sensitive or confidential data sharing and transactions.
- Edge computing: This involves processing data closer to the source of data generation, such as IoT devices, sensors, or mobile devices, rather than in centralized data centers.
These trends signify the evolving nature of data pipeline architecture, driven by technological innovation, evolving business needs, and shifting market dynamics. By embracing these trends, organizations can stay ahead of the curve and leverage data pipeline architecture to unlock new insights, optimize operations, and drive competitive advantage in an increasingly data-driven world.
Conclusion
In conclusion, data pipeline architecture serves as the backbone of modern data infrastructure, empowering organizations to harness the transformative potential of data for driving insights, innovation, and strategic decision-making. By embracing the principles of modularity, error handling, optimization, security, and continuous improvement, businesses can design and implement robust, scalable, and future-proof data pipeline architectures that navigate the complexities of today's data-driven landscape with aplomb, propelling them toward sustained success and competitive advantage in this digital age.
Opinions expressed by DZone contributors are their own.
Comments