Apache Beam Working With Files
The article explains how to read, write data to and from the file in Apache Beam with a pipeline where the ‘Employees.csv’ file be read/filtered/write to a new file.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
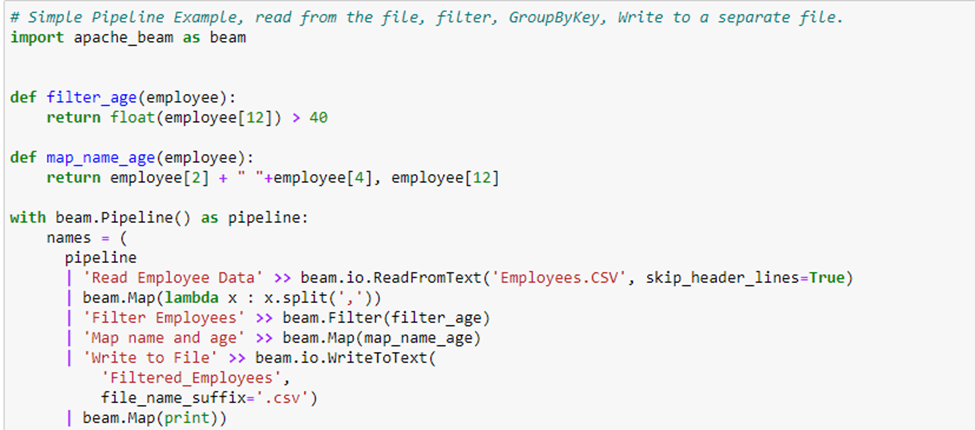
The article explains how to read, write data to and from the file in Apache Beam with a proper pipeline example. The reading data from the file is done through the ‘ReadFromText’ transform and writing to a new file is done using the ‘WriteToText’ transform. The first article explains how to read data from the file and how to write to a file, in the latter part of the article a Pipeline will be created where ‘Employees.csv’ file be read, filtered based on age, extract employee’s first name, last name, and age and write to a new file. Overall, the pipeline looks like this:

Reading From a File
In the article, we are using the file from the site we have downloaded a 100 records file and named it ‘Employees.csv’ through ‘ReadFromText’ will read file from the disk. The below code showcases the same:

Output

Writing to File
The ‘WriteToText’ transform is used to write the data to the file, the program below reads the data from the file and writes to the ‘out.csv’ file.
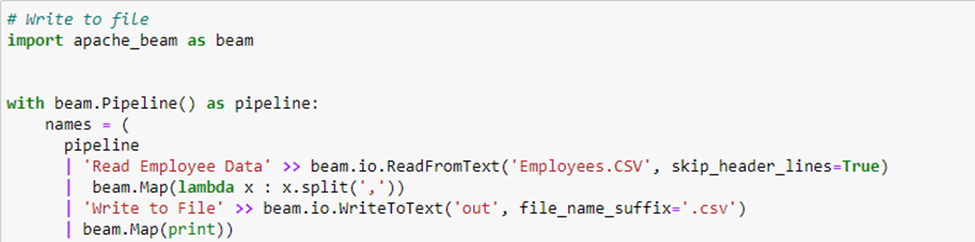
Output

Pipeline
The pipeline code contains two functions one for filtering out the rows where the employee age is greater than 40 and the second one is used to map only firstname, lastname, and age of the employee.
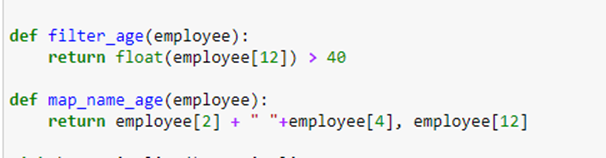
In both functions, we are accessing records based on the index. The full pipeline code is mentioned below:
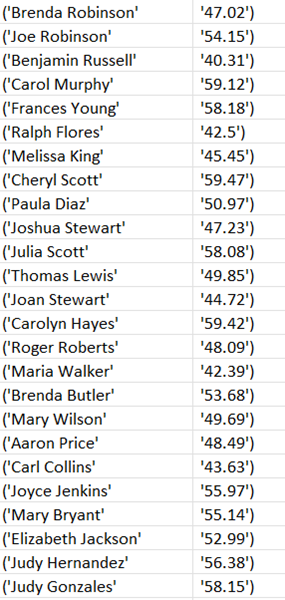
Contents of Generated File
Summary
In the article we have explored how to read, write data to and from the file, the article also explained the full pipeline code where the filtering, mapping on the data is performed and written to the new file.
Opinions expressed by DZone contributors are their own.
Comments