Apache Druid, TiDB, ClickHouse, or Apache Doris? Comparing the OLAP Tools We Have Used
In this article, readers will see a comparison of OLAP tools I have used as a big data team leader, including Apache Druid, TiDB, ClickHouse, and Apache Doris.
Join the DZone community and get the full member experience.
Join For FreeTo brief you about me, I lead the Big Data team at NIO, an electric vehicle manufacturer. I have tried a fair share of the OLAP tools available on the market and here is what I think you need to know.
Apache Druid
Back in 2017, looking for an OLAP tool on the market was like seeking a tree on an African prairie—there were only a few of them. As we looked up and scanned the horizon, our eyes linger on Apache Druid and Apache Kylin. We landed on Druid because we were already been familiar with it, while Kylin, despite its impressively high query efficiency in pre-computation, had a few shortcomings:
- The best storage engine for Kylin would be HBase, but introducing HBase would bring in a whole new bunch of operation and maintenance burdens.
- Kylin pre-computes the dimensions and metrics, but the dimensional explosion coming along puts great pressure on storage.
As for Druid, it used columnar storage, supported real-time and offline data ingestion, and delivered fast queries. On the flip side, it:
- Uses no standard protocols, such as JDBC, and thus was beginner-unfriendly.
- Had weak support for Join.
- Could be slow in exact deduplication and thus lowered down performance.
- Required huge maintenance efforts due to all the components with various installation methods and dependencies.
- Required changes in Hadoop integration and dependency of JAR packages when it came to data ingestion.
TiDB
We tried TiDB in 2019. Long story short, here are its pros and cons:
Pros
- It was an OLTP + OLAP database that supported easy updates.
- It had the features we needed, including aggregate and breakdown queries, metric computation, and dashboarding.
- It supported standard SQL, so it was easy to grasp.
- It didn’t require too much maintenance.
Cons
- The fact that TiFlash relied on OLTP could put more pressure on storage. As a non-independent OLAP, its analytical processing capability was less than ideal.
- Its performance varied among scenarios.
ClickHouse vs. Apache Doris
We did our research into ClickHouse and Apache Doris. We were impressed by ClickHouse’s awesome standalone performance, but stopped looking further into it when we found that:
- It did not give us what we wanted when it came to multi-table Join, which was kind of an important usage for us.
- It had relatively low concurrency.
- It could bring high operation and maintenance costs.
Apache Doris, on the other hand, ticked a lot of the boxes on our requirement list:
- It supported high-concurrency queries, which was our biggest concern.
- It was capable of real-time and offline data processing.
- It supported aggregate and breakdown queries.
- Its unique model (a type of data model in Doris that ensured unique keys) supported updates.
- It could largely speed up queries via materialized view.
- It was compatible with MySQL protocol, so there was little trouble in development and adoption.
- Its query performance fills the bill.
- It only required simple O and M.
To sum up, Apache Doris appeared to be an ideal substitute for Apache Druid + TiDB.
Our Hands-On OLAP Experience
Here is a diagram to show you how data flows through our OLAP system:
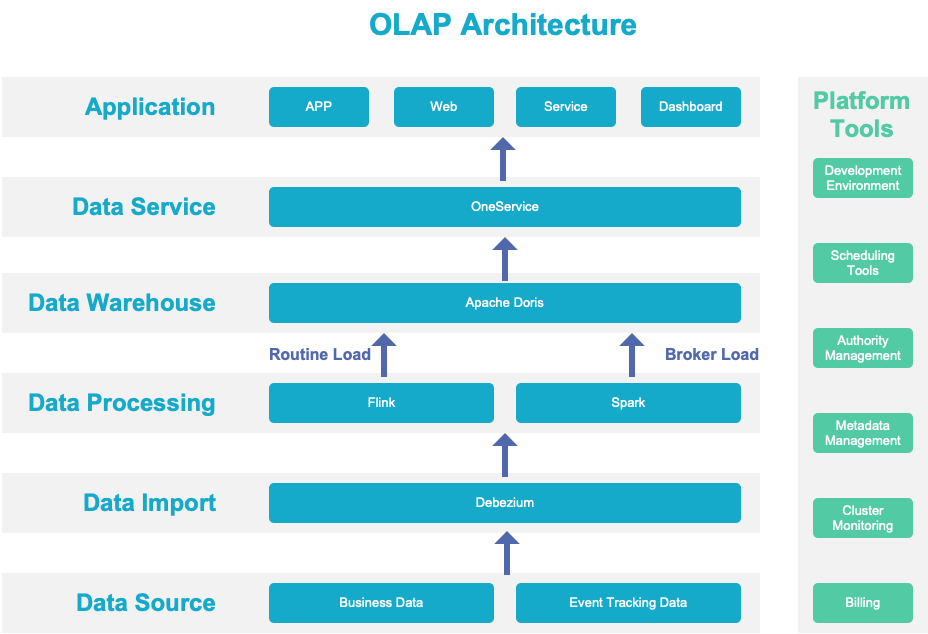
Data Sources
We pool data from our business system, event tracking, devices, and vehicles into our big data platform.
Data Import
We enable CDC for our business data. Any changes in such data will be converted into a data stream and stored in Kafka, ready for stream computing. As for data that can only be imported in batches, it will go directly into our distributed storage.
Data Processing
Instead of integrating streaming and batch processing, we adopted Lambda architecture. Our business status quo determines that our real-time and offline data come from different links. In particular:
- Some data comes in the form of streams.
- Some data can be stored in streams, while some historical data will not be stored in Kafka.
- Some scenarios require high data precision. To realize that, we have an offline pipeline that re-computes and refreshes all relevant data.
Data Warehouse
Instead of using the Flink/Spark-Doris Connector, we use the routine load method to transfer data from Flink to Doris, and broker load from Spark to Doris. Data produced in batches by Flink and Spark will be backed up to Hive for usage in other scenarios. This is our way to increase data efficiency.
Data Services
In terms of data services, we enable auto-generation of APIs through data source registration and flexible configuration so we can manage traffic and authority via APIs. In combination with the K8s serverless solution, the whole thing works great.
Data Application
In the data application layer, we have two types of scenarios:
- User-facing scenarios such as dashboards and metrics.
- Vehicle-oriented scenarios, where vehicle data is collected into Apache Doris for further processing. Even after aggregation, we still have a data size measured in billion but the overall computing performance is up to scratch.
Our CDP Practice
Like most companies, we build our own Customer Data Platform (CDP):
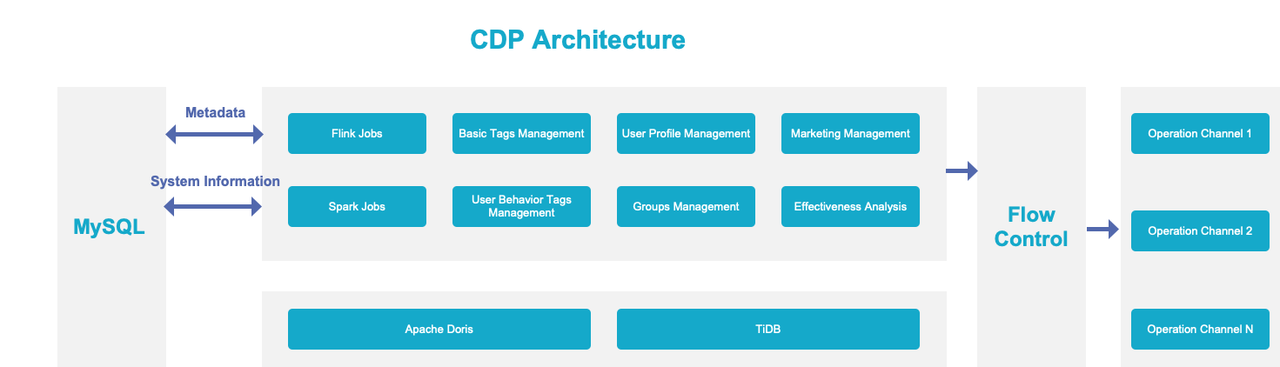
- Tags: the building block, obviously. We have basic tags and customer behavior tags. We can also define other tags as we want.
- Groups: divide customers into groups based on the tags.
- Insights: characteristics of each customer group.
- Reach: ways to reach customers, including text messages, phone calls, APP notifications, and IM.
- Effect analysis: feedback about how the CDP runs.
Real-Time + Offline
We have real-time tags and offline tags and need them to be placed together. Plus, columns on the same data might be updated at different frequencies. Some basic tags (regarding the identity of customers) should be updated in real time, while other tags (age, gender) can be updated daily. We want to put all the atomic tags of customers in one table because that brings the least maintenance costs and can largely reduce the number of required tables when we add self-defined tags.
So how do we achieve this?
We use the routineload method of Apache Doris to update real-time data, and the broker load method to batch import offline data. We also use these two methods to update different columns in the same table, respectively.
Fast Grouping
Basically, grouping is to combine a certain group of tags and find the overlapping data. This can be complicated. Doris helped speed up this process by SIMD optimization.
Quick Aggregation
We need to update all the tags, re-compute the distribution of customer groups, and analyze effects on a daily basis. Such processing needs to be quick and neat. So we divide data into tablets based on time so there will be less data transfer and faster computation. When calculating the distribution of customer groups, we pre-aggregate data at each node and collect them for further aggregation. In addition, the vectorized execution engine of Doris is a real performance accelerator.
Multi-Table Join
Since our basic data is stored in multiple data tables, when CDP users customize the tags they need, they need to conduct multi-table Join. An important factor that attracted us to Apache Doris was its promising multi-table Join capability.
Federated Queries
Currently, we use Apache Doris in combination with TiDB. Records about customer reach will be put in TiDB, and data regarding credit points and vouchers will be processed in TiDB, too, since it is a better OLTP tool. As for more complicated analysis, such as monitoring the effectiveness of customer operation, we need to integrate information about task execution and target groups. This is when we conduct federated queries across Doris and TiDB.
Conclusion
Opinions expressed by DZone contributors are their own.
Comments