Mongo Aggregates and How to Explain Aggregate Queries
In this article, take a look at Mongo aggregates and see a tutorial on how to start an aggregate.
Join the DZone community and get the full member experience.
Join For Free
Today, we are going to talk about Mongo Aggregates: one of the best things that happened to Mongo. Let’s start by pulling out a few differences between the normal and Mongo database.
Mongo belongs to one of those NoSQL databases that disrupted the internet a few years ago. Everyone in the industry was talking about them. Everyone wanted to move their stack to these flexible databases and was talking about how the data needs to move in that direction and so on.
As the hype began to settle, people started realizing the movement of the stack will help only if they implement it correctly, and for most of them, the shift wasn’t even necessary.
NoSQL is a broad term and consists of a variety of database models. Mongo is also one of them. Others includeCassandra, Apache Spark, and many more.
MongoDB is a document-based, distributed database. In production, people tend to run it with 3 replicas. 1 is the master and the other two being the slaves. This provides redundancy and high data availability.
You may also be interested In: MongoDB Tutorials and Articles: The Complete Collection
You can configure these to follow any guidelines, but by default, the reads and writes are handled by the primary replica, and the new data is moved on to the replica sets on each writes.
As the mongo doesn’t have a well-defined schema, it’s pretty hard to make queries from the data.
Mongoose is a library that can help you with this. It provides a lot of benefits, like creating hooks and indexes easily on the collections.
By the way, tables equivalent in Mongo are known as collections and rows equivalents are known as documents.
Mongo Aggregates
MongoDB aggregates make it easier to query data from any collection. It involves things like matching, getting data from other collections, selecting fields, and much more.
Let’s discuss a few of these aggregate queries.
Starting out a Mongo Aggregate
You can start the aggregate using the following code:
db.collection.aggregate([aggregate pipeline commands], options), where collection is the name of the collection on which aggregate is applied and db is the instance of the connected DB object.
The following are the commands that you can use in the aggregate pipeline.
Match in Mongo Aggregate
The match query can be called as the where query in SQL terms. You tell the aggregate to get the data that follows the given condition. It is recommended to keep the match query as soon as possible in the pipeline.
This will reduce the number of documents being returned from the query. It is also a good option to index the fields on which you run the match query to return the results faster.
For example: In a student database, you can make this query as follows:
{ $match: { "roll_number": 901 }}
or
{ $match: { "class": 5 }}
This query will return all the documents that satisfy the given query.
For all further parts of the pipeline, you can keep adding it to the main array of the pipeline.
Note: You can make use of the fields by appending a $ to the name of the fields whenever you want to use them.
Use Match as Early as Possible
You should use $match as early as possible to make use of indexes.
$match operations use suitable indexes to scan only the matching documents in a collection. When possible, place $match operators at the beginning of the pipeline.
Always try to explain the $match part of your queries and prefer to create compound indexes according to your queries.
Project in Mongo Aggregate
Project is the part where you tell the query which keys to pick from the given document.
xxxxxxxxxx
{
$project: {
student_name: 1,
student_age: '$age'
}
}
This will pick up only the fields with value 1 in the document. It is important to reduce the data being transferred to the next part of the pipeline.
It can also be used to change the name of the field. This is the SELECT equivalent of SQL commands.
_id field is added by default in the result.
Grouping in Mongo Aggregate
Group is used to group different things together. For example, if you want to calculate the sum of the age of students in different standards, the query will look something like this.
xxxxxxxxxx
db.students.aggregate([
{ $group: { _id: "$class", total: { $sum: "$age" } } }
])
Here is the link to the mongo query. You can use all different types of aggregate queries like average, min, and max.
Lookup Other Collections in Mongo Aggregate
Lookup is one of the most important aggregate queries which you can use. This allows us to join different collections together and get data from the other collections as well.
Here is the query of the lookup.
The lookup can be used with the pipeline as well. With this type of lookup, you can apply a check and tell the pipeline, when the given lookup will run.
xxxxxxxxxx
{
$lookup:
{
from: "students",
let: { studentId: "$_id", age: "$age" },
pipeline: [
{ $match:
{ $expr:
{ $eq: [ "$student_id", "$$studentId" ] }
}
},
{ $project: { student_id: 1, age: 1 } }
],
as: "data"
}
}
This is the implementation that you want to use when you want to run $match on the data being picked from the other collection.
The simplest implementation of $lookup is as follows.
xxxxxxxxxx
{
$lookup: {
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}
How to Explain Mongo Aggregate Queries
To explain the queries, you will have to use the options in the aggregate to find the way in which queries are run.
xxxxxxxxxx
db.getCollection("author").explain().aggregate([
{
$match: {
"email" : "[email protected]"
}
}
])
This will generate a simple output like this.
xxxxxxxxxx
{
"stages" : [
{
"$cursor" : {
"query" : {
"email" : "[email protected]"
},
"queryPlanner" : {
"plannerVersion" : 1.0,
"namespace" : "db_name.author",
"indexFilterSet" : false,
"parsedQuery" : {
"email" : {
"$eq" : "[email protected]"
}
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"email" : {
"$eq" : "[email protected]"
}
},
"direction" : "forward"
},
"rejectedPlans" : [
]
}
}
}
],
"ok" : 1.0
}
winningplan contains an object which tells us more about the winning plan which was used to run the query and queryPlanner contains an Array of plans which were tried. Mongo chooses the best plans and uses it for running the queries.
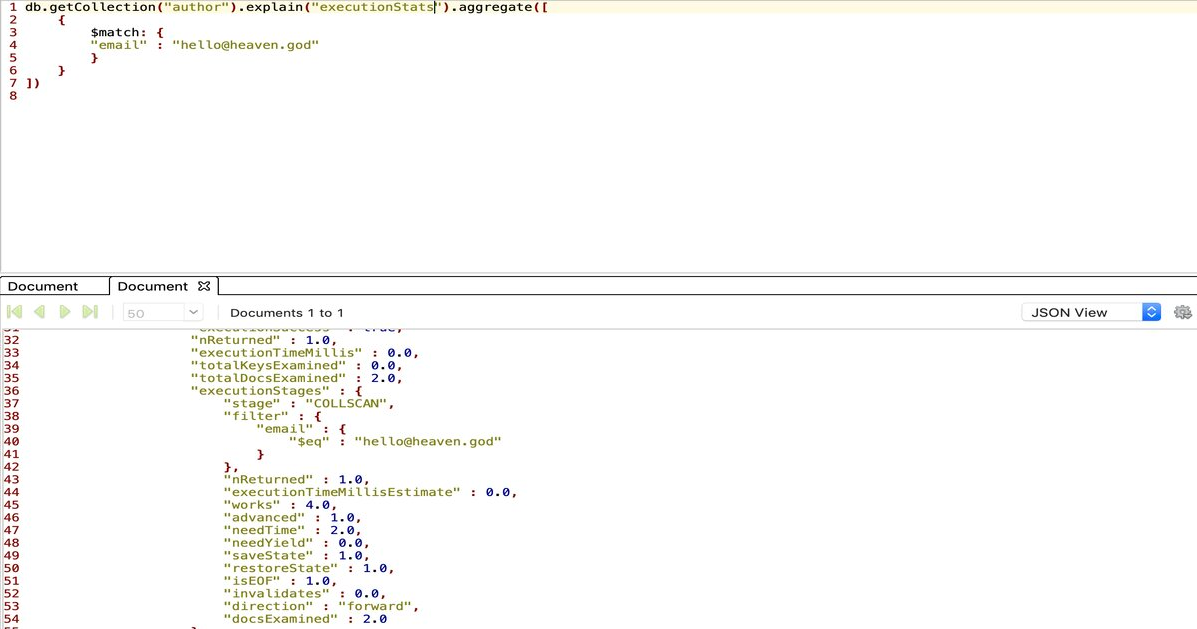
If you use the explain with executionStats it will give you things like docs Returned and docs Examined which can be helpful in finding the best suitable index for your collection.
xxxxxxxxxx
db.getCollection("author").explain("executionStats").aggregate([
{
$match: {
"email" : "[email protected]"
}
}
])
Conclusion
There are a few more options to choose from. Aggregate is one of the most important parts of the Mongo database.
If you are dealing with this database daily, then it would be useful to know a little about it as well.
Thanks for stopping by, and let me know if you want to know about something else as well. I love to write about tech topics.
Also, let me know if I have made any mistakes in this post.
Note: The internal performance optimizer of the mongo aggregate optimizes the queries accordingly to make them as fast as possible.
Further Reading
MongoDB Pipelines With Examples
Published at DZone with permission of Ranvir Singh. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments