Apache Iceberg REST Catalog: The Key to Vendor-Agnostic Data Interoperability
In this article, I have demonstrated how Iceberg Data can be accessed through the Iceberg REST Catalog from Data Mesh with a simple Python application.
Join the DZone community and get the full member experience.
Join For FreeApache Iceberg Open Table Format was released in the community with many features, but became popular due to interoperability. This interoperability makes Iceberg vendor-agnostic and SQL engine-agnostic.
Iceberg REST Catalog (IRC) made interoperability smooth and simple. IRC can solve integration-related challenges in big data analytics ecosystems. This becomes so important, especially in the Data Mesh framework, where you have multiple data publishers and consumers connected through a central governance platform. Using IRC, companies can save costs on the data redundancies, compute, and operational overhead.
Apache Open Table Format
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to compute engines, including Spark, Trino, PrestoDB, Flink, and Hive, using a high-performance table format that works just like a SQL table.
Iceberg REST Catalog
The Iceberg REST Catalog is a standardized REST API (HTTP-based API) specification for managing Apache Iceberg table metadata. It provides a vendor-agnostic interface for Iceberg Table catalog operations. A great benefit of the REST catalog is that it allows you to use a single client to talk to any catalog backend. This increased flexibility makes it easier to make custom catalogs compatible with engines like Athena, Glue Job, or Starburst without requiring the inclusion of a Jar into the classpath. Most of the well-known data catalog products support IRC, such as Apache Polaris, AWS Glue Catalog, Tabular, and Nessie.
So, the REST Catalog standardizes how different systems communicate with each other using Iceberg table metadata. This makes it easier to build a modern data lakehouse architecture with interchangeable components. It also helps to maintain unified governance across the platforms.
Data Mesh Framework
The data mesh framework is a design pattern for distributed data analytical platforms (Data Lake). This framework can be viewed as a hub and spoke model where a centralized governance platform is a hub and data publishers (producers) and consumer platforms are spokes. This is a standardization for interoperability, enabled by a shared and harmonized self-serve data infrastructure. Communication between data publishers and consumers happens via centralized governance platforms. The central governance platform does not hold or consume any data; rather, it enforces access control and facilitates data sharing. This framework addresses the challenges of centralized, monolithic, and domain-agnostic data lakes.
Sample Data Mesh Architectures
Here to address the challenges and provide the solution, I am referring to AWS tools and services, but the same can be implemented using other cloud services like Azure and GCP, too. If you want to understand the datamesh architecture in detail, you can refer to this article.
Tools/services used:
- AWS S3 Bucket: Amazon Simple Storage Service (Amazon S3) is an object storage service offering industry-leading scalability, data availability, security, and performance. This stores the data in Data Lake.
- AWS Glue Catalog: Holds the metadata of the data stored on S3 storage.
- AWS Lake Formation: Centrally govern, secure, and share data for analytics.
- IAM Role: Grants temporary security credentials to users, applications, or services to access cloud resources securely. Publishers and consumer application/user assume the role to perform the granted operations.
- EMR: A big data processing service that accelerates analytics workloads with unmatched flexibility and scale. Data is consumed and processed through a Spark Job and executed here.
- Glue Job: Another service from AWS similar to EMR. Here, Glue jobs are being used to execute Python scripts.
- Apache Iceberg Table Format: Data are cataloged in Apache open table format.
Scenario 1: Without Iceberg and IRC in AWS
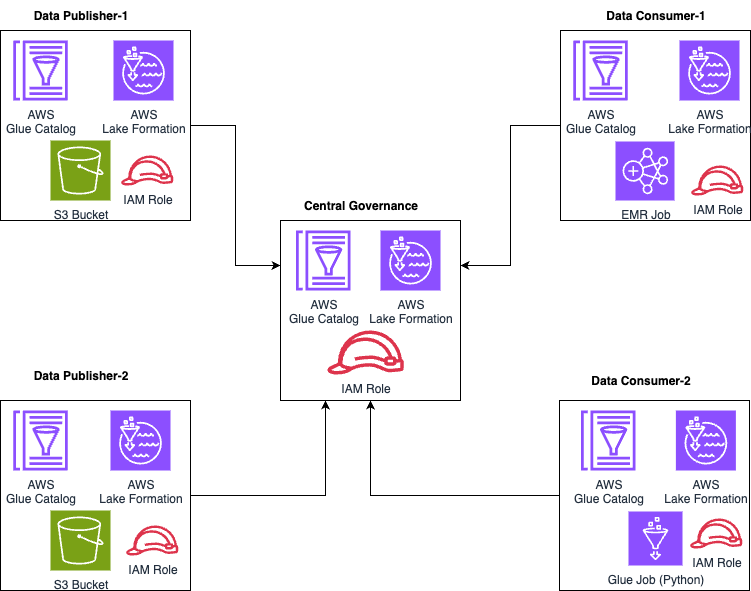
Data is stored in the S3 buckets. Hive format tables are created in the Glue catalog. Lake locations and Glue tables are registered with the Lake Formation. Central governance has enforced the access controls on the data stored in the publisher-1 and publisher-2 platforms.
Consumer-1 and consumer-2 are accessing the data using EMR Jobs and Glue Jobs via the Central governance platform.
Scenario 2: With Iceberg and IRC
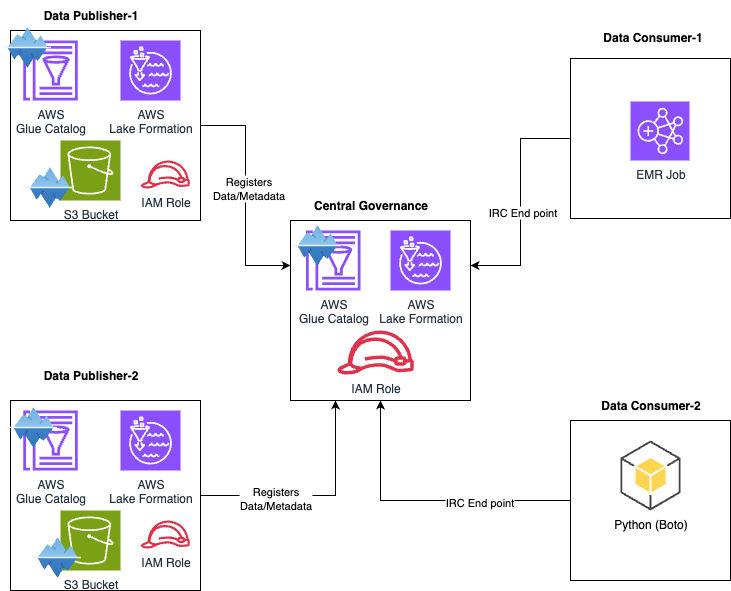
Here, the situation is as above, but the only difference is the table format. In the scenario-1 table format is Hive, whereas here Apache Open Table Format has been used.
What Are the Challenges Without IRC?
In scenario 1, data consumers are heavily dependent on AWS services like Glue Catalog, Lake Formation, EMR, and Glue Jobs. APIs (like Glue APIs) provided by AWS are being called in the code to access the data. If the catalog is changed, then the codes need to be refactored. This makes the vendor-locked solution. You can not consume the data using Snowflake or other platforms without first copying the data to Snowflake. This leads to another governance and access enforcement at the Snowflake end.
How Can IRC Solve It?
Before IRC can solve this, let’s understand how IRC works internally with Python code. Below are the steps performed to get data from the Iceberg table:
| Action | Description |
|---|---|
|
Authentication |
The Python script (using a library like PyIceberg or a custom client) loads the AWS credentials (Access Key/Secret Key). |
|
Metadata Request |
The script sends an HTTP request (e.g., GET /v1/catalogs/{catalog_name}/namespaces/{namespace}/tables/{table_name}) to the AWS Glue Iceberg REST endpoint. |
|
Glue/LF Authorization |
The Glue IRC endpoint receives the request and: 1) Authenticates the request using IAM. 2) Calls Lake Formation to check if the requesting IAM principal has the necessary permissions (e.g., SELECT) on the requested table. |
|
Metadata Response |
If authorized, the Glue IRC endpoint returns the Iceberg table metadata (e.g., the current metadata file path, schema, partitioning) and temporary S3 credentials (vended by Lake Formation). |
|
Data Access |
The Python script uses the temporary S3 credentials received in the metadata response to send requests to Amazon S3. These requests are to download the necessary Iceberg manifest files and eventually the actual data files. |
|
Data Retrieval |
S3 receives the request, validates the temporary Lake Formation-vended credentials, and returns the requested Iceberg data and manifest files to the Python script. |
|
Processing |
The Python script uses the downloaded metadata and data files to perform the requested operations (e.g., reading data, running a query). |
Now you see how IRC and Python work together under the hood. In scenario 2, where IRC has been implemented, you can see that there is no copy catalog required at the consumer end.
Also, there is no access control governance (No Lake Formation) required at the consumer end. Consumers only need the query engines like EMR or Python. Python can be deployed in different clouds like GCP/Azure, which support multi-cloud consumption.
This solution can be utilized with Snowflake, too, using the Catalog Integration feature, where Snowflake can directly query the Iceberg data from Data Mesh (Data Lake) without having a local copy of the data. Python does not use any Glue Catalog-specific APIs; rather, it uses standard “pyiceberg” libraries, which can work with any underlying Iceberg Catalog.
Prerequisites
- Create an AWS Data Lake using the Data Mesh Framework.
- Create a DB in the Glue Catalog.
- Create an Iceberg table in the Glue Catalog and register it to the Lake Formation.
- Create an IAM role and grant the permissions for data consumption.
- Get the AWS Access/Secret Keys for that role and set them in the environment variable.
- Install Python 3.12+.
- Install boto3.
- Install pyiceberg library.
from pyiceberg.catalog import load_catalog
'''from pyiceberg.schema import Schema
from pyiceberg.types import TimestampType
from pyiceberg.types import StructType
from pyiceberg.types import NestedField, IntegerType, StringType'''
import os
import boto3
import botocore
import pandas as pd
import logging
# Set up logging to show debug messages
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
# for PyIceberg logging
logger = logging.getLogger('pyiceberg')
logger.setLevel(logging.DEBUG)
rest_catalog = load_catalog(
"glue",
**{
"type": "rest",
"warehouse": "xxxxxxxxx” #Governance AWS Account ID (Glue Catalog ID)
"uri": "https://glue.us-east-1.amazonaws.com/iceberg", #Iceberg REST Catalog Endpoint
"rest.sigv4-enabled": "true",
"rest.signing-name": "glue",
"rest.signing-region": "us-east-1"
}
)
print(rest_catalog.list_tables("iceberg_db"))
table = rest_catalog.load_table("iceberg_db.iceberg_table")
print(f"Table schema: {table.schema()}")
print(f"Table spec: {table.spec()}")
# Query the table
logger.info("Scanning table data...")
scan = table.scan()
arrow_table = scan.to_arrow()
logger.info(f"Total rows retrieved: {len(arrow_table)}")
logger.info(f"Columns: {arrow_table.column_names}")
# Convert to Pandas for easier manipulation
df = arrow_table.to_pandas()
# Display basic information
logger.info(f"DataFrame shape: {df.shape}")
logger.info(f"DataFrame columns: {list(df.columns)}")
# Show first few rows
logger.info("First 5 rows:")
print(df.head())
Future Applicability
This Python application can be deployed to the container and orchestrated using a Kubernetes service. A container can be deployed to any cloud with minimum configuration changes. This Python application can be refactored and rewritten into PySpark to make it a distributed processing application.
Conclusion
Iceberg REST Catalog (IRC) enables vendor-agnostic data access for Iceberg Open Table Format using standardized REST API endpoints. IRC provides centralized governance with consistent security policies without duplication of enforcement, and supports robust credential vending to provide temporary credentials for authorized data access. Consumers can directly query data from central governance platforms without creating local copies, reducing storage costs, compute overhead, and the complexity of managing duplicate governance controls.
With IRC, data can be accessed from different clouds (AWS, Azure, GCP) and platforms (Snowflake, EMR, Python, Presto) using standard libraries like PyIceberg, PySpark, making it truly cloud-agnostic. IRC eliminates the need for catalog-specific code and JAR files, making it easier to integrate with various engines and reducing the need to switch between different Iceberg catalog backends.
Opinions expressed by DZone contributors are their own.
Comments