Apache Ignite — More Than Just a Data Grid
Learn how to fully leverage the collective CPU and RAM power of multiple computers to accomplish your tasks.
Join the DZone community and get the full member experience.
Join For FreeMany of us are familiar with data grids, which are known to be a great way to improve the performance of various applications. Oracle Coherence, Gigaspaces, Hazelcast, Apache Geode — these are all excellent examples.
The central concept behind almost any data grid is a distributed in-memory hash table. The “in-memory” part provides ultra-low latency for data access, while the “distributed” part offers virtually unlimited scalability, and therefore virtually unlimited throughput.
Typically, data grids also come with processing capabilities, as well as mechanisms to collocate computation with the data. As a result, you get a powerful combination of distributed data storage and distributed processing engine, which allows you to fully leverage the collective CPU and RAM power of multiple computers to accomplish your tasks.
Is Apache Ignite a Data Grid?
The short answer is: “YES!”
A bit longer answer is: “Yes, but it is also so much more.”
“Apache Ignite is a horizontally scalable, fault-tolerant distributed in-memory computing platform for building real-time applications that can process terabytes of data with in-memory speed.” — ignite.apache.org
Apache Ignite was initially created and developed as a data grid. Today, however, it incorporates some interesting and unique features that significantly widen the applicability of the technology. It is far beyond our common understanding of a data grid.
Here are some of the use cases that you can use Ignite for.
High-Performant Greenfield Applications
Data grids usually run on top of existing legacy data sources (e.g., relational databases), and serve as acceleration mechanisms for existing applications.
But in today’s age of digital transformation, there are tons of newly built applications that require scalability and performance from day one. Sure, you can go the “old way”, using one of the proven RDBMSs as the system of record with one of the data grids on top for better performance. This approach has multiple implications, though:
- Such architecture is still limited. Mainly, data grids are efficient at read-intensive workloads, but whenever you need to write something, you have to go to the underlying database. Therefore, the database still bounds the scalability and performance of updates.
- In-memory storage is volatile, which means that every time you restart your data grid cluster, you make the data unavailable. You then need to reload the data from the underlying database, which might take quite a bit of time, increasing possible downtimes up to unacceptable values.
- This approach is generally overcomplicated and even a little “hacky”. If you have to deploy two independent data storages to serve a single purpose, then something is wrong. There must be a better way!
And there is a better way. Apache Ignite implements a concept that we call “Durable Memory”. It relies on page-memory architecture where any page can be stored not only in memory but on disk as well — you just need to enable the Native Persistence option. Ignite’s persistence is scalable, supports transactions, SQL, and all other APIs. Its tight integration with the in-memory layer makes data access entirely transparent for applications (i.e., an application can read or update the data at any point in time even if it’s not yet loaded into RAM).
The addition of the out-of-the-box persistence layer transforms Ignite into a memory-centric database. Essentially, this creates a durable system of record with scalability and performance characteristics of an in-memory data grid — a perfect tool for performance-sensitive greenfield applications.
HTAP and Real-Time Analytics
We are all used to a proposition that transactional processing (OLTP) and analytical processing (OLAP) are supposed to be done by separate systems. I’m sure you’ve seen a diagram similar to this:
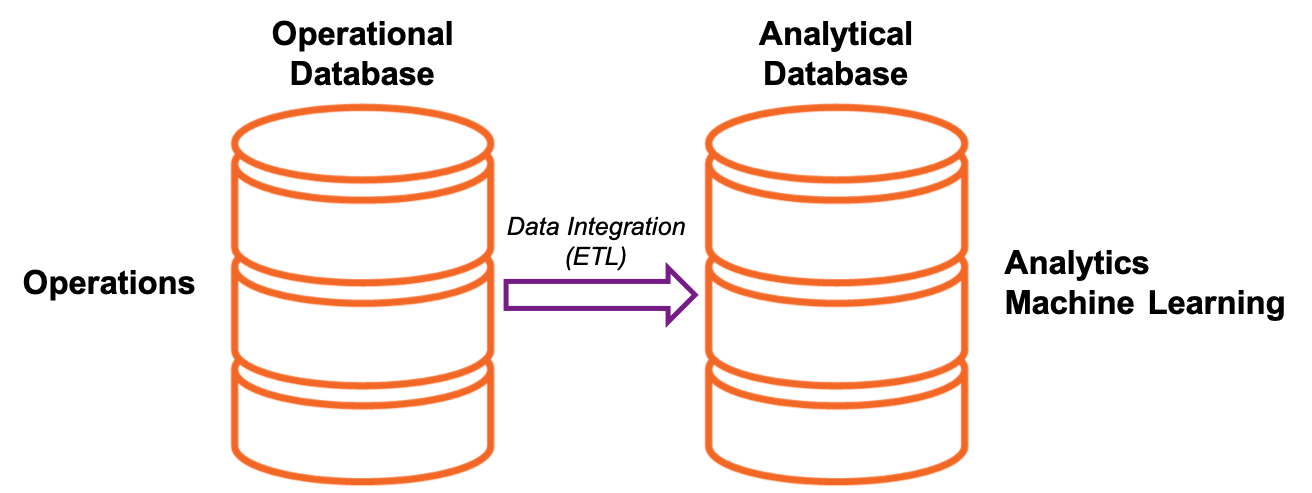
The idea is to execute operations in an operational database and then execute an ETL process that propagates changes to an analytical database. You can use the latter for analytics, machine learning, deep learning, etc.
Many companies have used this architecture for a long time. Nowadays, many of those companies start questioning the approach and looking for alternatives. The issue is that ETL happens periodically — every several hours in the best case, but usually overnight, or even over a weekend. Such a process creates a time lag between a change in the operational database and a corresponding reaction of the analytical system. This lag is not compatible with the growing demand for real-time analytical processing.
Imagine that your credit card is used by someone else without your consent. Your bank has all those complicated fraud detection algorithms in place that can notify you that something is wrong. Real-time processing ensures that you get the notification within minutes or even seconds, rather than after several hours.
The only way to achieve such an immediate reaction is to unify the two databases into a single store, capable of running hybrid transactional/analytical processing (HTAP).
HTAP = OLTP + OLAP
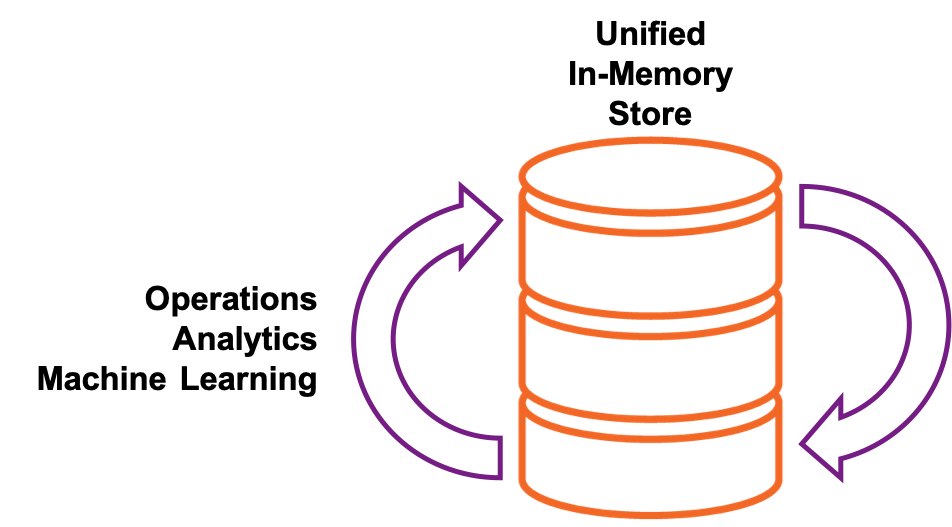
There are a couple of things that make Apache Ignite suitable for HTAP.
- Ignite follows “single storage, multiple workloads” approach, which means that you can store all your data once in a single cluster, and then work with this data via all available APIs, whether it’s key-value, transactions, compute, SQL or machine learning.
- Ignite’s Native Persistence allows storing a superset of data on disk without affecting the availability of the data. Let’s say your total dataset is several petabytes, but you only have 100GB of data that is updated and accessed frequently. It’s not reasonable to put everything in memory, and with Ignite, you don’t have to. The majority of the data can be stored on disk only, and it will still be fully available to the applications when needed.
Demand for real-time analytics calls for a significant shift in how we architecture backend systems. There is still a lot to figure out, but Apache Ignite already provides an incredible combination of features to support HTAP workloads.
Digital Integration Hubs
One of the biggest challenges that IT architects currently face is that the data often spreads across multiple systems. Within a single company, you will easily find relational databases, NoSQL databases, mainframes, data lakes, SaaS solutions…
Different APIs, different data models, different everything.
More and more regularly, such companies feel a need for aggregation between multiple application’s data to get deeper insights into what is happening in the business. IT infrastructures are often not ready for this.
The solution is to create a Digital Integration Hub.
“Digital Integration Hub is an advanced application architecture that aggregates multiple back-end system of record data sources into a low-latency and scale-out, high-performance data store… The high-performance data store is synchronized with the back-end sources via some combination of event-based, request-based, and batch integration patterns.” — Gartner
Essentially, you put the data from multiple sources into a single scalable in-memory platform and provide a unified API to various applications that you have.
Apache Ignite appears to be an excellent foundation for such a solution. I’ve already mentioned the Native Persistence that allows Ignite to act as a system of record, as well as its ability to work with HTAP workloads — both become important when you build a data integration hub.
Besides, you need a good set of integration components with databases, streaming platforms, and SaaS products. Here are some of such integrations that Ignite provides out of the box:
- The CacheStore interface for pluggable synchronization with relational, NoSQL databases, or big data stores like Hadoop.
- Multiple streaming connectors.
- Integration with Apache Spark.
Back in the day, distributed caches used to be the prominent way to improve performance. While new use cases and requirements kept coming up, many of those systems evolved into what we now refer to as “in-memory data grids”.
Similarly, in-memory computing platforms like Apache Ignite is the next stepping stone in the evolution of distributed systems. Data grids are still vital and are going to remain so for many years to come, but we need more comprehensive frameworks to deliver on the latest modern requirements.
The demand for real-time processing will only keep growing, and I’m excited to watch how this trend unfolds.
Opinions expressed by DZone contributors are their own.
Comments