Apache Spark: Spark Union Adds Up the Partition of Input RDDs
Learn about the behavior of Apache Spark's RDD partitions during a union operation and the different cases in which you might find unknown results during the operation.
Join the DZone community and get the full member experience.
Join For FreeBack when I was doing a union of two-pair RDDs, I found a strange behavior regarding the number of partitions. The output RDD got a different number of partitions than the input RDD.
For example, suppose rdd1 and rdd2 each have two partitions. After the union of these RDDs, I was expecting the same number of partitions for the output RDD. But the output RDD showed the number of partitions as being the sum of the partitions of the input RDDs.
After doing some research, I found that the partitioner has an impact on this strange behavior. More details on the partitioner can be found here.
I found two cases, which are described below, in which that strange behavior can happen.
Case 1
If the partitioner is different for both input RDDs, then the output RDD will have partitions as the sum of the partitions of the input RDD. To check the partitioner, do the following:

Here, different partitioners have two meanings:
- Both input RDDs have different partitioners. For example,
rdd1has a hash partition andrdd2has a range partitioner. - One RDD has partitioners and the other one doesn't.
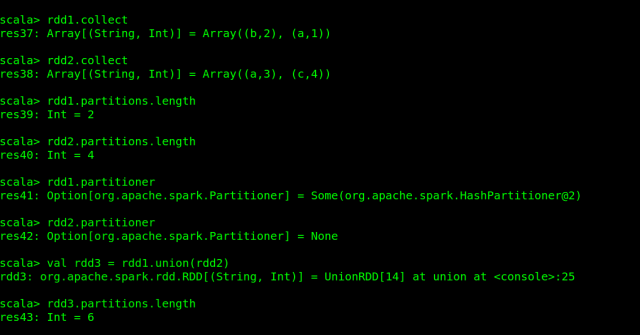
You can see in above example, that rdd1 has HashPartitioner with two partitions while rdd2 does not have any partitioner with four partitions. After the union of these two, the output rdd3 has 6 (2 + 4) partitions.
Case 2
If the partitioner is the same for both input RDDs but the number of partitions is different, then the output RDD will get the partitions as the sum of the partitions of input RDDs.

As you can see in the above example, both input RDDs have the same partitioner but with a different number of partitions — rdd1 has 2 while rdd2 has 3. So, after union, the output rdd3 has 5 (2 + 3) partitions.
You can see below that what happens when both partitioners and the number of partitions are the same for both input RDDs.
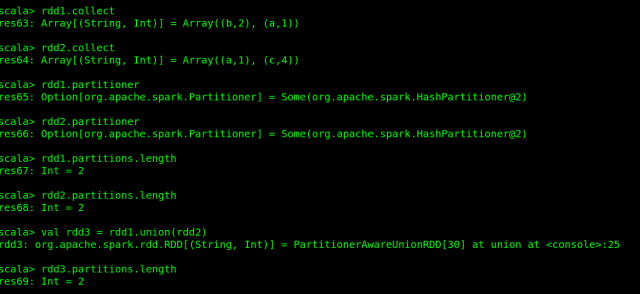
In above example, the output rdd3 has the same number of partitions as the input RDD.
Published at DZone with permission of Rishi Khandelwal. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments