CAP Theorem for Distributed System
This article explores the CAP theorem. Understanding CAP is crucial for designing distributed systems and we will delve into the meaning of each property.
Join the DZone community and get the full member experience.
Join For FreeThis article dives into the world of distributed systems and explores a fundamental principle called the CAP theorem. Distributed systems play a crucial role in many modern applications, and the CAP theorem helps us understand the trade-offs inherent in these systems.
What Are Distributed Systems?
Distributed systems distribute computations and data across multiple interconnected nodes within a network. This can involve offloading processing power or geographically dispersing data for faster delivery. Unlike centralized systems that store data in a single location, distributed systems spread data across multiple interconnected points.
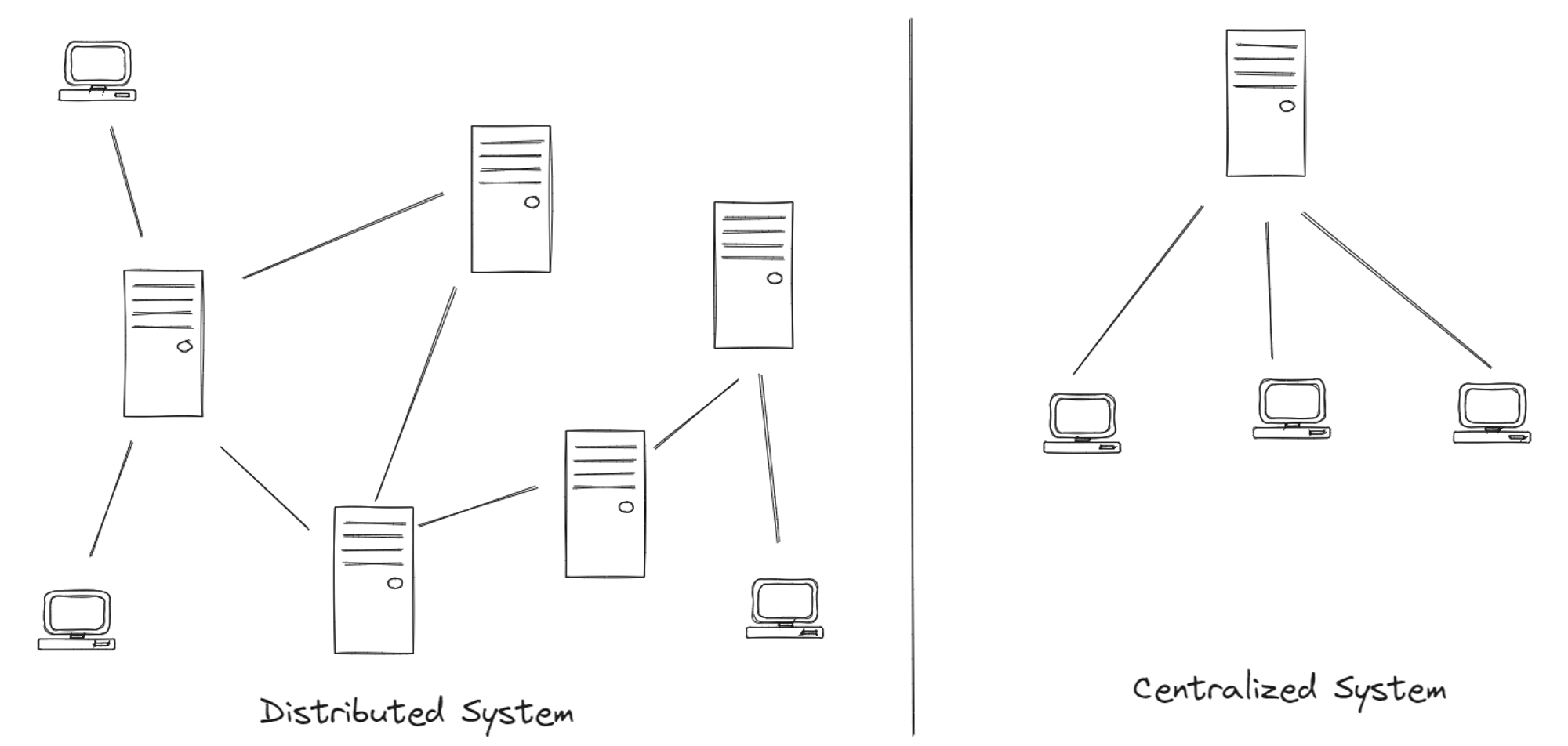
This distribution brings its own set of challenges, with the first hurdle being network failures. Network links can break, creating network partitions where the entire network gets divided into isolated groups. Each partition loses communication with the others. A system's ability to withstand such partitions is called partition tolerance. It's important to note that achieving 100% partition tolerance is practically impossible; all distributed systems are susceptible to network partitions at some point.
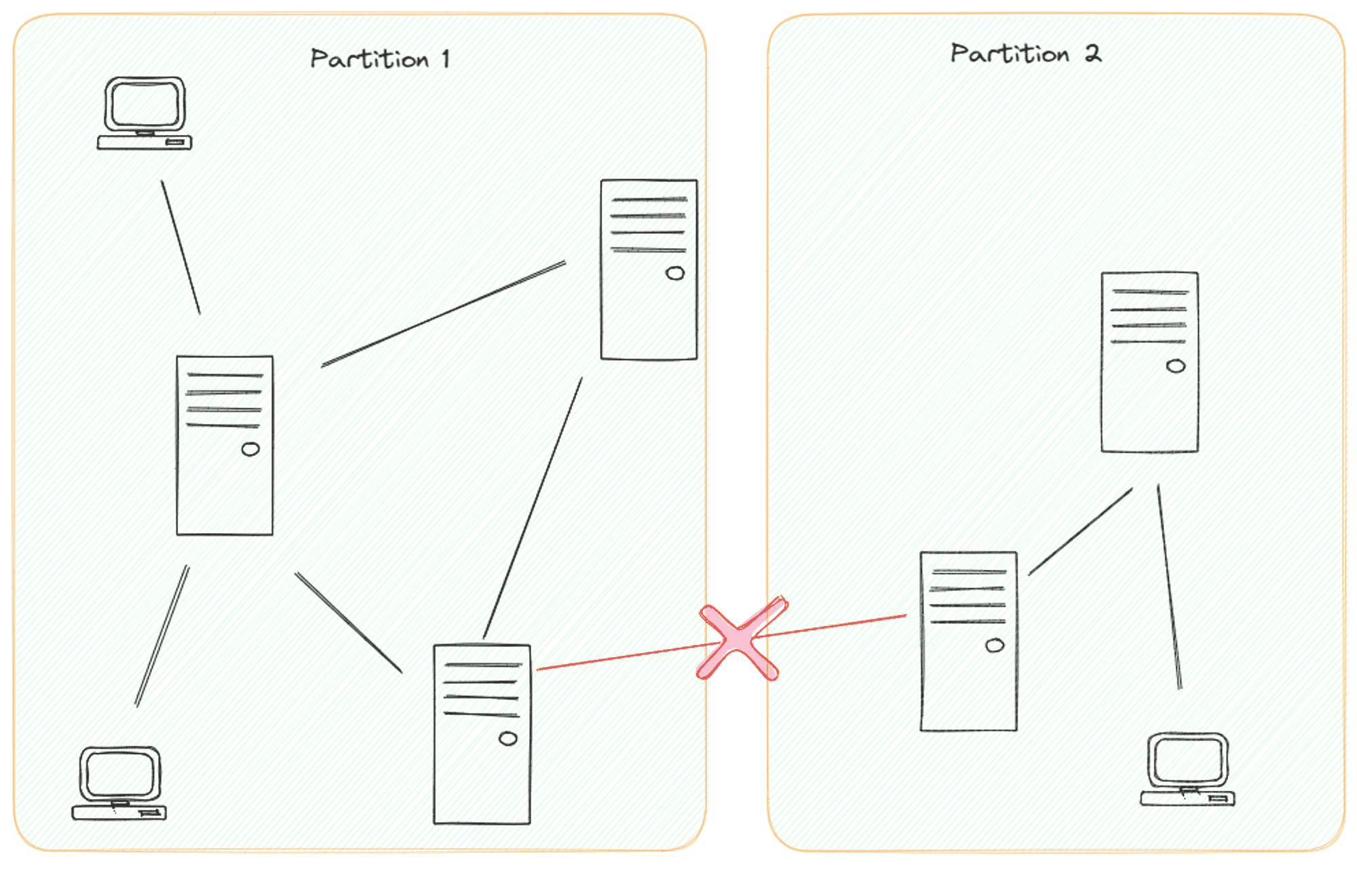
These partitions, though temporary, disrupt communication between parts of the system. Let's consider a social media platform like Instagram or Facebook. If a partition occurs, a newly posted photo might not be visible to users in another partition until the network recovers.
This leads us to another crucial property that the distributed system has. The “Consistency”. You already noticed that if two partitions occurred, then data seen by two partitions are different (or in other words inconsistent). Consistency is a measurement of whether the system data is correct over the network at a given time.
Consistency plays a crucial role in financial applications. Unlike social media posts, how fast your data is consistent across the system is a measurement of how consistent your system is. If not this might cause serious problems such as a double spending problem. If you don’t know the double expending problem, then it is about a financial system that holds each person’s balance. Assume Alice has 100$ in her account and all the servers consistent with Alice’s account balance of 100$. Alice bought 90$ worth of watches online from server A. Server A completed the transaction and sent a notification to other servers to deduct Alice’s account 90$. But before the message propagates, a sudden partition occurs and server B does not get Alice’s transaction. If Alice calls server B and performs another transaction, the server still considers Alice to have 100$ and lets her spend it again. If Alice buys a bag for 50$ from server B, the transaction still passes.
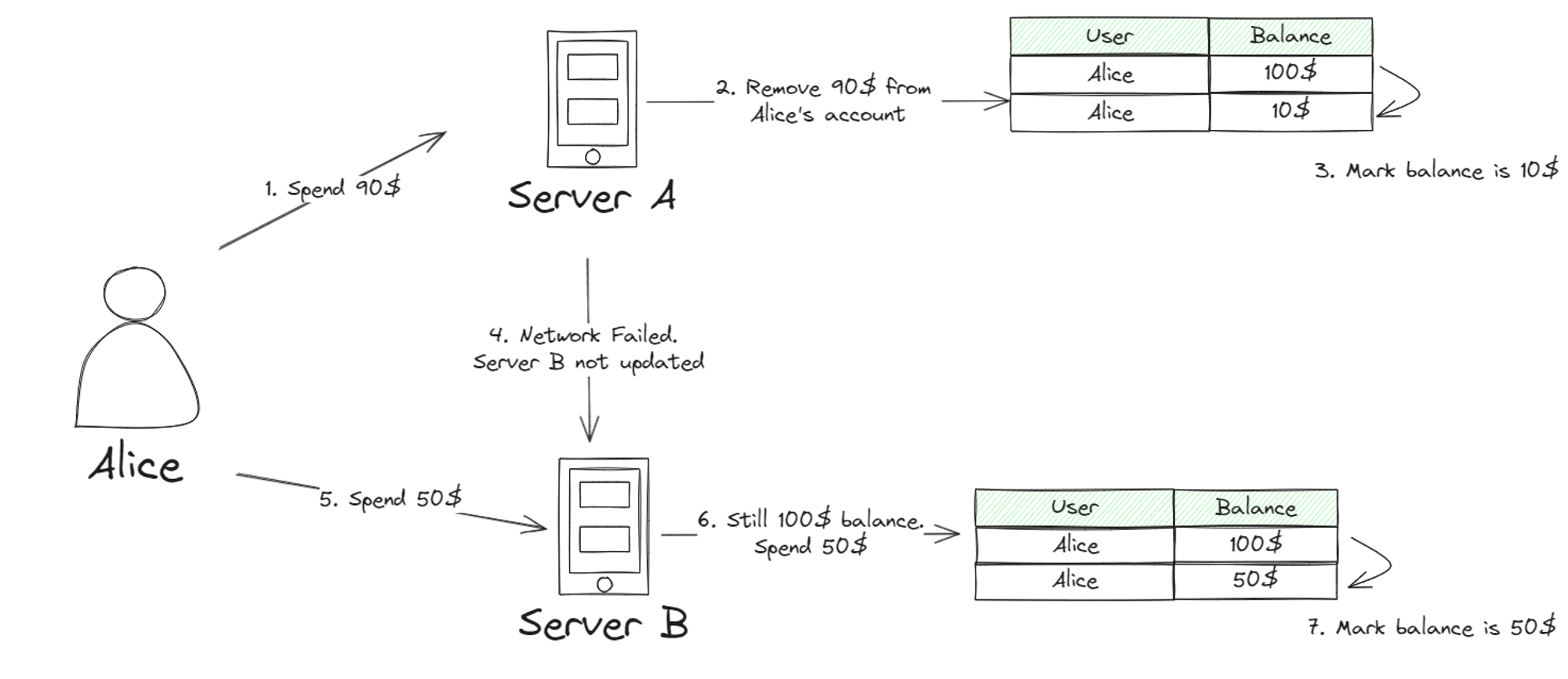
As you can see, in this kind of financial system, consistency is a big matter and it should have higher consistency. In contrast to social media platforms, it does not matter how fast you receive your friend’s update. Now we know financial transaction systems need higher consistency. But how are we supposed to achieve it?
There can be many consistency levels but let’s analyze the following levels which are used mostly for distributed systems:
- Linearizability
- Sequential Consistency
- Causal Consistency
- Eventual Consistency
Linearizability
Linearizability is the highest consistency level. This consistency algorithm works by adding a read lock for all the nodes in the system if any of the node data needs to be updated. By adding a read lock for all the nodes, we can make sure that any of the nodes in the system do not read partially updated data. The lock gets removed once all the data is in a consistent state. If there is network partitioning, the system takes more time to come to a consistent state. What will happen if a client connects to a node and requests to read data while the node is locked? Well, the client has to wait until the node releases the lock.
This leads us to the third important property, Availability. The availability is a property when the client requests something from a node, it responds. If the node is not ready to serve the request, the client gets no or failed response. With the Linearizability example, we are locking the node so that the client does not get a response. This means until data become consistent, nodes are not available. We can conclude that if consistency is higher, we cannot achieve higher availability.
Sequential Consistency
In contrast to Linearizability, the Sequential Consistency is a relaxed consistency model. Instead of locking all the nodes for all the data updates, sequential consistency locks nodes in chronological order. Think about a chat application. When two people chat, both people’s messages should be in proper chronological order. If not, it would become a mess to understand it. Let us understand it with an example.
Alice needs to send a message to the chat group and she sends the message to the system. Assuming the system has no partitions, her message propagates to all the nodes. Now Bob also needs to send a message to the group but a network partition occurred and some nodes do not get updated with Bob’s message. Now if Alice sends another message in this partitioned system some nodes are still not updated with the previous Bobs message. If the node does not update Bob’s message and only adds Alice’s message, the chat becomes a mess. In this scenario, a sequentially consistent system puts a write lock on the node where only it can write the node if all previously published data is already added. Until the node gets updated with previous data, it has to wait until previously sent messages reach the node.
In this consistency mode, we are only considering the sequential consistency of each node data. Here you can see nodes are available than in the linearizability model where the write lock gets applied until the order of the events is resolved. The client can still get a response from the given node in the partitioned system but up to the last data in the correct sequential order.
Causal Consistency
The Causal Consistency is a much more relaxed consistency model that doesn’t care about order as well. Causal Consistency only considers about relation between data. For example, think about a social media platform where you can post images and put comments. Alice posts a photo to the platform and at the same time, Bob also posts a photo to the platform. These two posts do not have any relation. The order of the post does not affect the third person Charlie looking at both of the photos. But, for each photo, there is a comment section. When Charlie sees comments on the photos those comments should be in chronological order to him to understand it. Comments in this system are Causally consistent. This means that order does matter for some cases, but not for all the scenarios. If there are unrelated entities(Such as posts) having more relaxed consistency while comments have a dependency on their related posts.
Eventual Consistency
Now we can understand the Eventual Consistency easily. Think about the same social media platform without a comment feature. Now Alice and Bob post photos and Charlie can see their post on his feed. It does not matter which order he received the data.
This leads us to think about another important fact about availability. In the linearizability consistency level, we could not achieve higher availability due to locking. But in Eventual Consistency, we don’t need to have any locks. Therefore server nodes are available at all times.
What CAP Theorem Is All About?
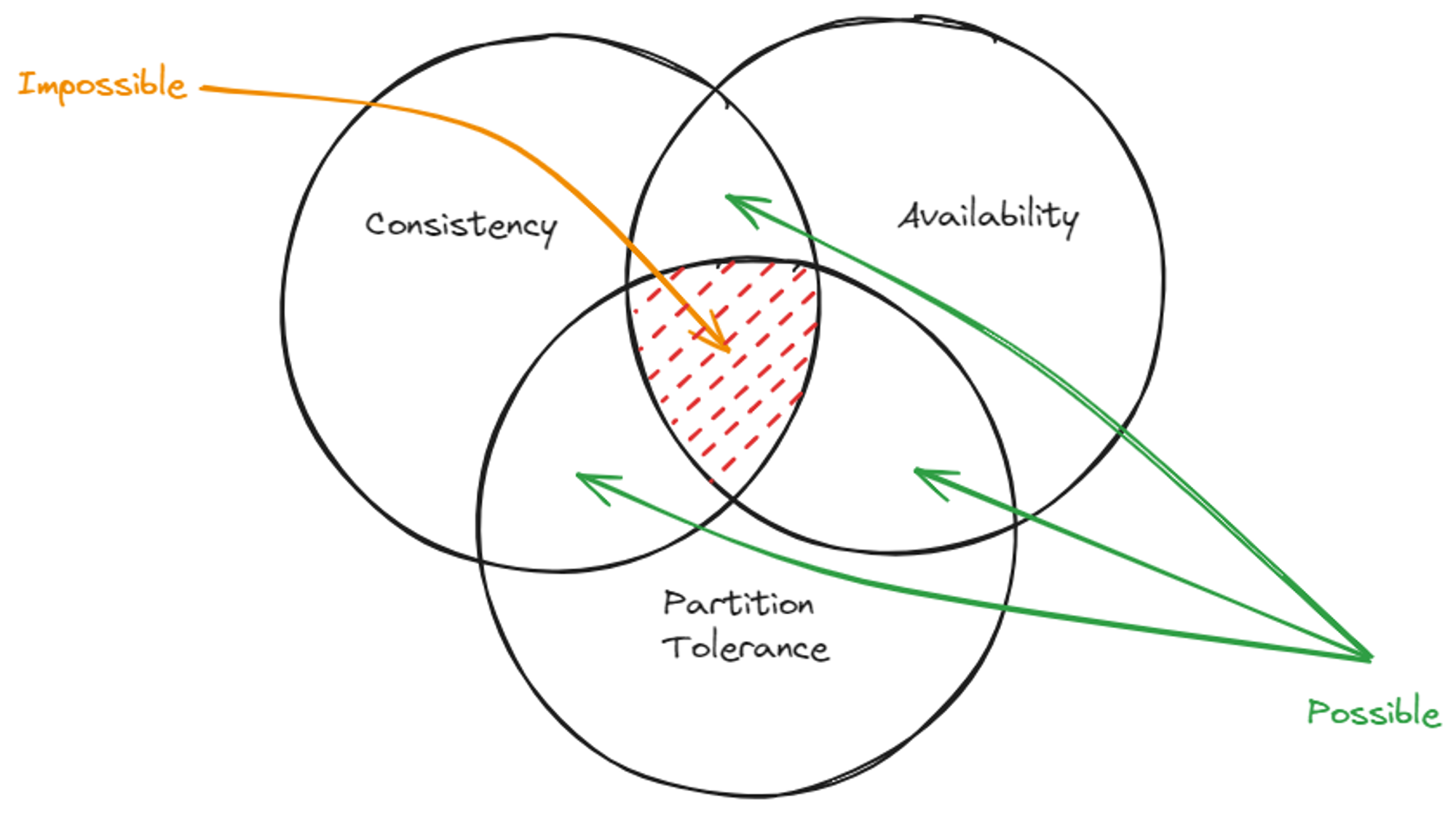
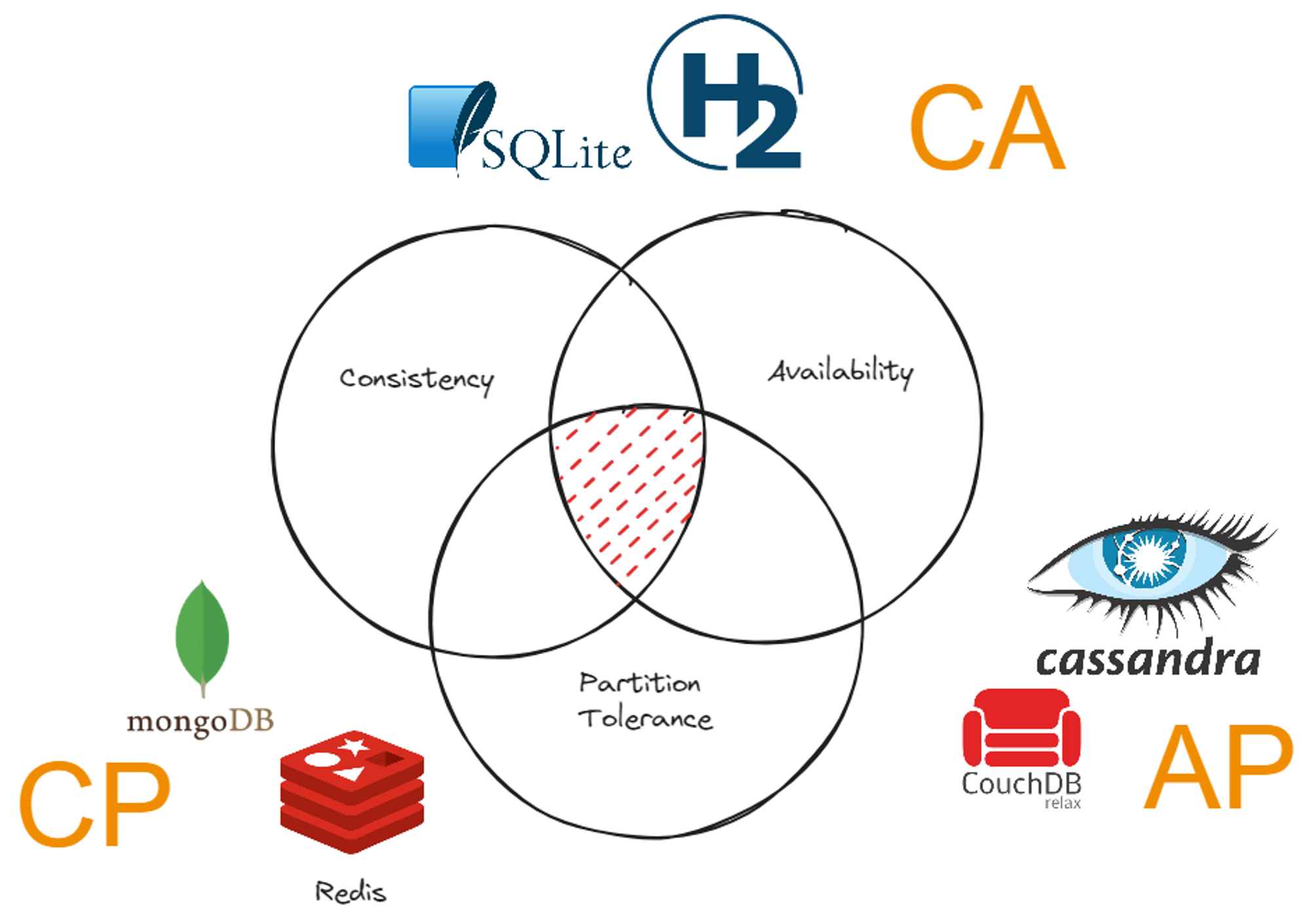
Now we discovered all the pieces of the CAP theorem and it is time to complete the puzzle. We have discussed three properties that the distributed system has. The Partition Tolerance tells us the system can tolerate partitioning, The Consistency which maintains data consistent over the distributed system, and the Availability which makes sure the system always responds to client requests. CAP theorem states that we can only select two of these properties out of three. Let’s have a look at all three cases.
Select Partition Tolerance and Consistency Over the Availability
This is the scenario in which we allow the system to have a partition. But we need to keep the system consistent. The financial transaction scenario we have discussed belongs to this category. To maintain consistency, we have to lock the nodes until data becomes consistent over the system. Only then is it allowed to read from the system. Therefore the availability is limited.
Select Partition Tolerance and Availability Over the Consistency
This is the scenario in which we don’t need strict consistency in the system. Remind about the social media system discussed in the eventual consistency. We don’t need consistent data but rather have data in whatever order. Having a relaxed consistency level, we don’t need to lock nodes and nodes are always available.
Availability and Consistency Over the Partition Tolerance
This kind of system is more likely a centralized system rather than a distributed system. We cannot build a system without having network partitioning. If we ensure Availability and Consistency at the same time, then there cannot be any partitions. Which means it is a centralized system. Therefore, we don’t discuss both available and Consistent systems in distributed systems.
Example Use Cases for CAP Theorem
Now you know what the CAP theorem is. Let’s see some example tools used in all three above cases.
Partition Tolerance and Consistent System
Redis and MongoDB are popular database solutions for CP(Consistent and Partition-tolerant systems). These databases are built to work as distributed databases and let there be partitions. Even if there are partitions, it lets you have consistent data over all the Databases connected.
Partition Tolerance and Available System
This system does not much care about consistency on the system. Rather it cares about being responsive and faster operation. This includes databases such as Cassandra and CouchDB. These databases are built to operate in distributed environments and faster operation.
Consistent and Available System
This type of system is not meant to be distributed but rather a centralized system. Databases such as SQLite and H2 are built to run on a single node. These databases are always consistent and available since they don’t need to lock nodes and it is the only node. But you cannot have it on a distributed system as it cannot tolerate partitioning.
 Why is MYSQL not listed for any of those? Well MySQL is generally considered a CA system designed to provide good consistency and availability while sacrificing partition tolerance. The reason for this is that MYSQL runs in a master-slave mode where the master is the node that the client to access. Therefore it is not a true distributed system that we are talking. But with different configurations, still you can work it as a CP system.
Why is MYSQL not listed for any of those? Well MySQL is generally considered a CA system designed to provide good consistency and availability while sacrificing partition tolerance. The reason for this is that MYSQL runs in a master-slave mode where the master is the node that the client to access. Therefore it is not a true distributed system that we are talking. But with different configurations, still you can work it as a CP system.
As you can see, the CAP theorem imposes limitations on distributed systems. As system designers and developers, we must choose which properties to prioritize: consistency, availability, or partition tolerance. The chosen consistency model will determine whether we prioritize high availability or sacrifice some availability to ensure consistency. Many tools exist to help you design your application based on these trade-offs. Choose wisely! The next time you encounter a distributed system, consider these three crucial properties.
Opinions expressed by DZone contributors are their own.
Comments