How to Build Real-Time BI Systems: Architecture, Code, and Best Practices
This guide walks you through building a real-time Business Intelligence (BI) pipeline using tools like Apache Kafka, Spark Structured Streaming, and Apache Druid.
Join the DZone community and get the full member experience.
Join For FreeIn today’s fast-paced digital economy, real-time data is no longer a luxury—it’s a necessity. Traditional Business Intelligence (BI) systems, which rely on batch processing, introduce significant latency that can hinder timely decisions. Whether it's detecting fraud in banking or optimizing ICU bed allocation in hospitals, delay equals lost opportunity or even risk.
Real-time BI turns this around by enabling systems to ingest, process, and visualize data within seconds or even milliseconds of generation. In this article, we’ll walk through the architecture, tools, and practical implementation steps required to build a real-time BI system, from ingestion and processing to analytics storage and dashboarding.
Why Real-Time BI Matters
Real-time BI enables organizations to:
- React to changes in business conditions instantly
- Monitor KPIs and system health in real time
- Deliver hyper-personalized customer experiences
- Detect fraud or anomalies before they escalate
- Make informed decisions on-the-fly in dynamic environments
Industries such as healthcare, finance, e-commerce, manufacturing, and logistics rely on low-latency insights to ensure continuity, accuracy, and competitiveness. For example, in finance, real-time analysis of transactions can prevent fraudulent activity. In logistics, live updates on supply chains help reduce delivery delays.
Use Case Example
Let’s consider a real-world example: an e-commerce platform.
This business wants to monitor every user interaction: searches, clicks, cart additions, and purchases in real time. Events can feed machine learning models that recommend products instantly, detect suspicious behavior, or trigger automated promotional emails. Achieving this requires a BI system that supports streaming ingestion, real-time processing, and instant visualization.
Traditional daily batch ETLs simply won’t suffice for systems that need to act in seconds, not hours.
High-Level Architecture Overview
Here’s the foundational flow of a real-time BI system:
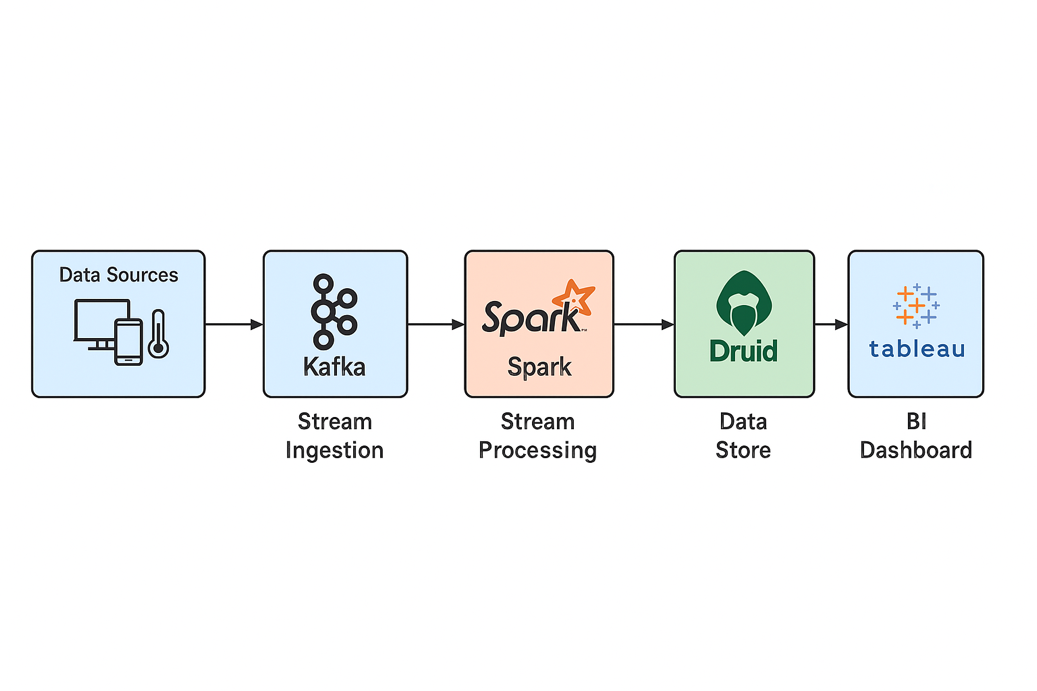
Each component has a critical role to play:
Data Sources
These include web/mobile apps, IoT devices, and operational databases that generate continuous event streams.
Stream Ingestion
This is the entry point for real-time pipelines. Technologies like Apache Kafka, AWS Kinesis, or Azure Event Hubs are widely used for their reliability and scalability.
Stream Processing
Real-time engines like Apache Flink, Spark Structured Streaming, and Apache Storm process incoming data on the fly, enabling immediate transformation, aggregation, and filtering.
Analytics Store
Low-latency databases like Apache Druid, ClickHouse, Amazon Redshift, or Snowflake serve processed data for querying and dashboarding.
BI Tools
Visualization tools like Tableau, Apache Superset, Grafana, or Power BI sit on top of the analytics store and present dashboards with live data.
Step-by-Step Implementation
Step 1: Stream Ingestion With Kafka
Kafka is a go-to choice for real-time ingestion. Here’s a basic example of a Kafka producer in Python that sends user activity events:
from kafka import KafkaProducer
import json
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
sample_data = {'user_id': 1, 'action': 'purchase', 'timestamp': '2025-04-04T10:00:00Z'}
producer.send('user_events', value=sample_data)
producer.flush()Kafka ensures durability and supports replaying events—essential for robust pipelines.
Step 2: Real-Time Processing With Spark
Use Spark Structured Streaming to process data from Kafka in near real-time.
val spark = SparkSession.builder.appName("RealTimeBI").getOrCreate()
import spark.implicits._
val kafkaDF = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "user_events")
.load()
val dataDF = kafkaDF.selectExpr("CAST(value AS STRING)").as[String]
val parsedDF = dataDF.map(json => parseEvent(json))You can enrich, filter, or aggregate this data based on business logic.
Step 3: Load into Apache Druid for Low-Latency Analytics
Apache Druid is purpose built for high speed querying on real-time data streams. Here’s a basic Kafka ingestion spec for Druid:
{
"type": "kafka",
"spec": {
"dataSchema": {
"dataSource": "user_events",
"timestampSpec": {"column": "timestamp", "format": "iso"},
"dimensionsSpec": {
"dimensions": ["user_id", "action"]
}
},
"ioConfig": {
"topic": "user_events",
"consumerProperties": {"bootstrap.servers": "localhost:9092"},
"taskCount": 1
},
"tuningConfig": {"type": "kafka"}
}
}You can query Druid using its native API or via SQL over HTTP, making it highly accessible to developers and analysts.
Step 4: Real-Time Visualization
With data in Druid (or ClickHouse, etc.), you can now build dashboards in your preferred BI tool. Superset and Grafana are lightweight, developer friendly options, while Tableau and Power BI are more business-centric.
Dashboards built atop real-time databases can show metrics like:
- Current active users
- Conversion rates by minute
- Live campaign performance
- Real-time inventory status
Best Practices for Building Real-Time BI
- Use event time & watermarking: Handle late or out-of-order events accurately
- Design for schema evolution: Future-proof your system as data formats change
- Monitor the pipeline: Use Prometheus and Grafana to track performance and failures
- Optimize queries: Reduce high-cardinality joins and scan times in analytics stores
- Enable caching: BI tools should cache frequently queried data to reduce load
- Secure the pipeline: Stream data often includes PII—encrypt and audit access accordingly
Final Thoughts
Implementing real-time BI isn’t just about adopting trendy tools—it’s about transforming how decisions are made. When your insights are delayed, so are your actions. By enabling data to flow continuously and be visualized instantly, you're laying the groundwork for smarter, faster, and more automated decision-making.
With platforms like Kafka, Spark, and Druid, you have everything you need to build a system that delivers live insights. The journey from data to decision doesn’t have to be overnight—make it instant.
Have you built a similar pipeline or faced roadblocks? Share your experience in the comments—let’s grow the real-time BI ecosystem together.
Further Reading and Resources
Opinions expressed by DZone contributors are their own.
Comments