Data Management With PostgreSQL Partitioning and pg_partman
PostgreSQL table partitioning divides large tables into smaller segments to boost query performance, simplify maintenance, and enable scalable data management.
Join the DZone community and get the full member experience.
Join For FreeEfficient database management is vital for handling large datasets while maintaining optimal performance and ease of maintenance. Table partitioning in PostgreSQL is a robust method for logically dividing a large table into smaller, manageable pieces called partitions. This technique helps improve query performance, simplify maintenance tasks, and reduce storage costs.

This article delves deeply into creating and managing table partitioning in PostgreSQL, focusing on the pg_partman extension for time-based and serial-based partitioning. The types of partitions supported in PostgreSQL are discussed in detail, along with real-world use cases and practical examples to illustrate their implementation.
Introduction
Modern applications generate massive amounts of data, requiring efficient database management strategies to handle these volumes. Table partitioning is a technique where a large table is divided into smaller, logically related segments. PostgreSQL offers a robust partitioning framework to manage such datasets effectively.
Why Partitioning?
- Improved query performance. Queries can quickly skip irrelevant partitions using constraint exclusion or query pruning.
- Simplified maintenance. Partition-specific operations such as vacuuming or reindexing can be performed on smaller datasets.
- Efficient archiving. Older partitions can be dropped or archived without impacting the active dataset.
- Scalability. Partitioning enables horizontal scaling, particularly in distributed environments.
Native vs Extension-Based Partitioning
PostgreSQL's native declarative partitioning simplifies many aspects of partitioning, while extensions like pg_partman provide additional automation and management capabilities, particularly for dynamic use cases.
Native Partitioning vs pg_partman
| Feature | Native Partitioning | pg_partman |
|---|---|---|
| Automation | Limited | Comprehensive |
| Partition Types | Range, List, Hash | Time, Serial (advanced) |
| Maintenance | Manual scripts required | Automated |
| Ease of Use | Requires SQL expertise | Simplified |
Types of Table Partitioning in PostgreSQL
PostgreSQL supports three primary partitioning strategies: Range, List, and Hash. Each has unique characteristics suitable for different use cases.
Range Partitioning
Range partitioning divides a table into partitions based on a range of values in a specific column, often a date or numeric column.
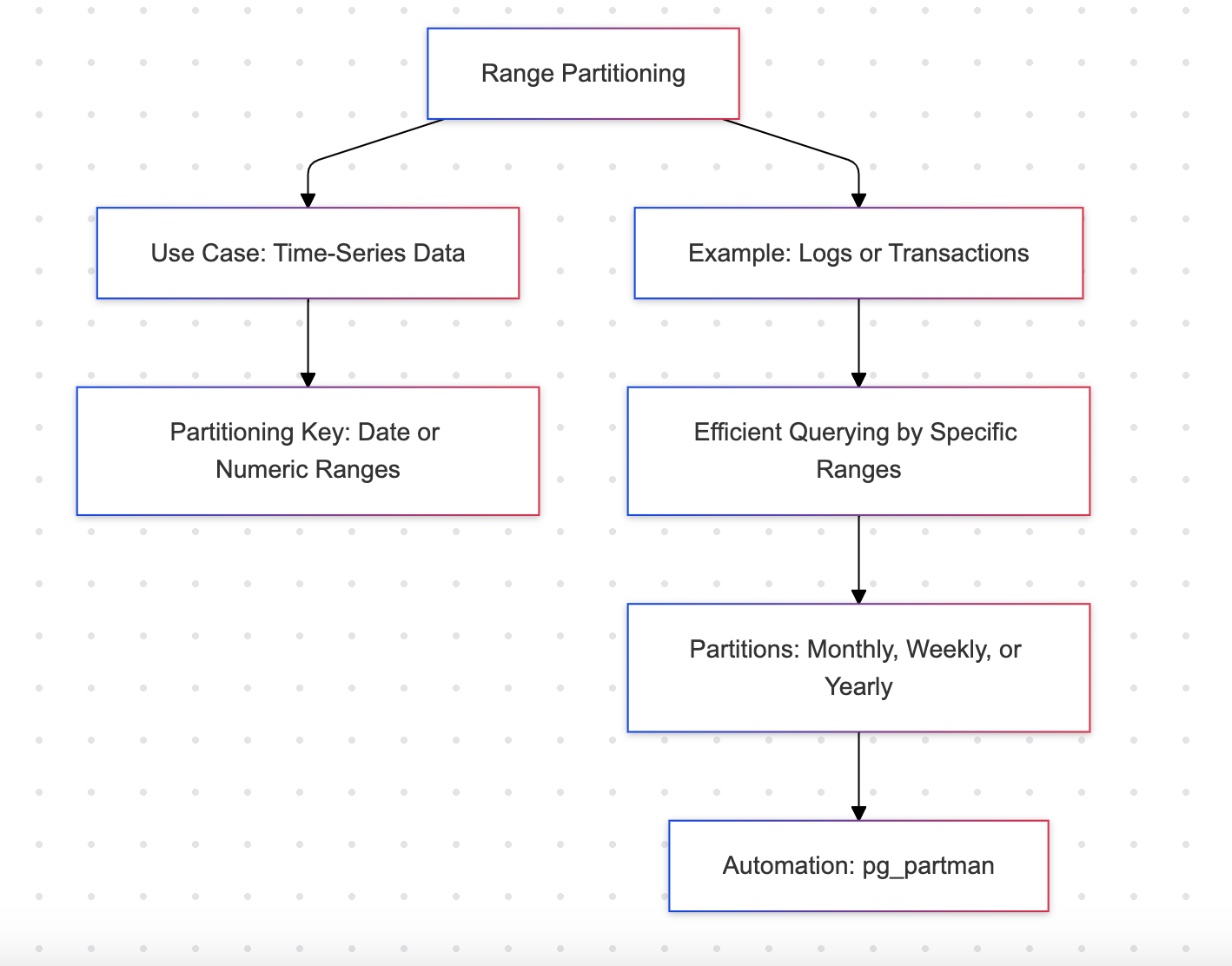
Example: Monthly sales data
CREATE TABLE sales (
sale_id SERIAL,
sale_date DATE NOT NULL,
amount NUMERIC
) PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2023_01 PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');Advantages
- Efficient for time-series data like logs or transactions
- Supports sequential queries, such as retrieving data for specific months
Disadvantages
- Requires predefined ranges, which may lead to frequent schema updates
List Partitioning
List partitioning divides data based on a discrete set of values, such as regions or categories.
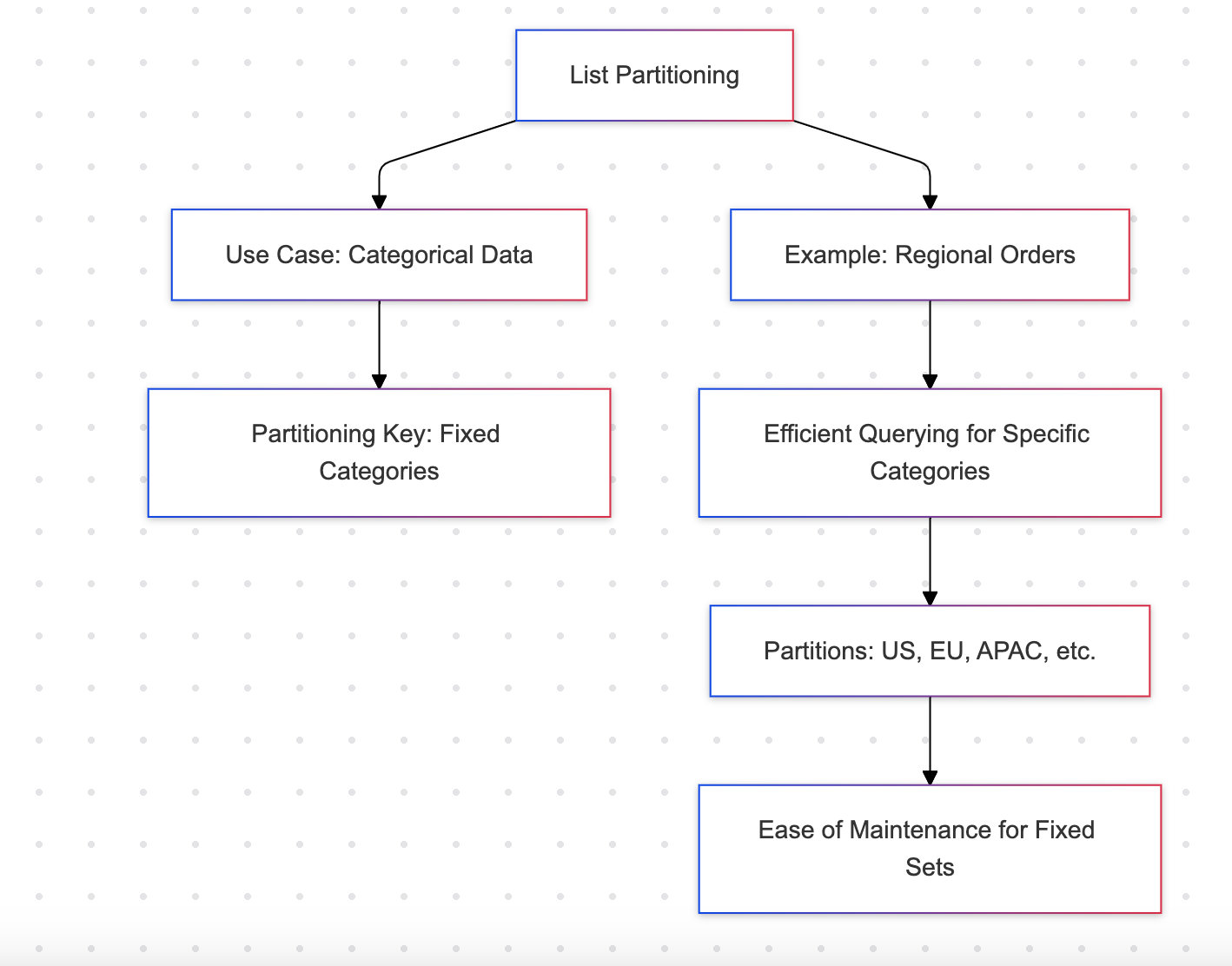
Example: Regional orders
CREATE TABLE orders (
order_id SERIAL,
region TEXT NOT NULL,
amount NUMERIC
) PARTITION BY LIST (region);
CREATE TABLE orders_us PARTITION OF orders FOR VALUES IN ('US');
CREATE TABLE orders_eu PARTITION OF orders FOR VALUES IN ('EU');Advantages
- Ideal for datasets with a finite number of categories (e.g., regions, departments)
- Straightforward to manage for a fixed set of partitions
Disadvantages
- Not suitable for dynamic or expanding categories
Hash Partitioning
Hash partitioning distributes rows across a set of partitions using a hash function. This ensures an even distribution of data.
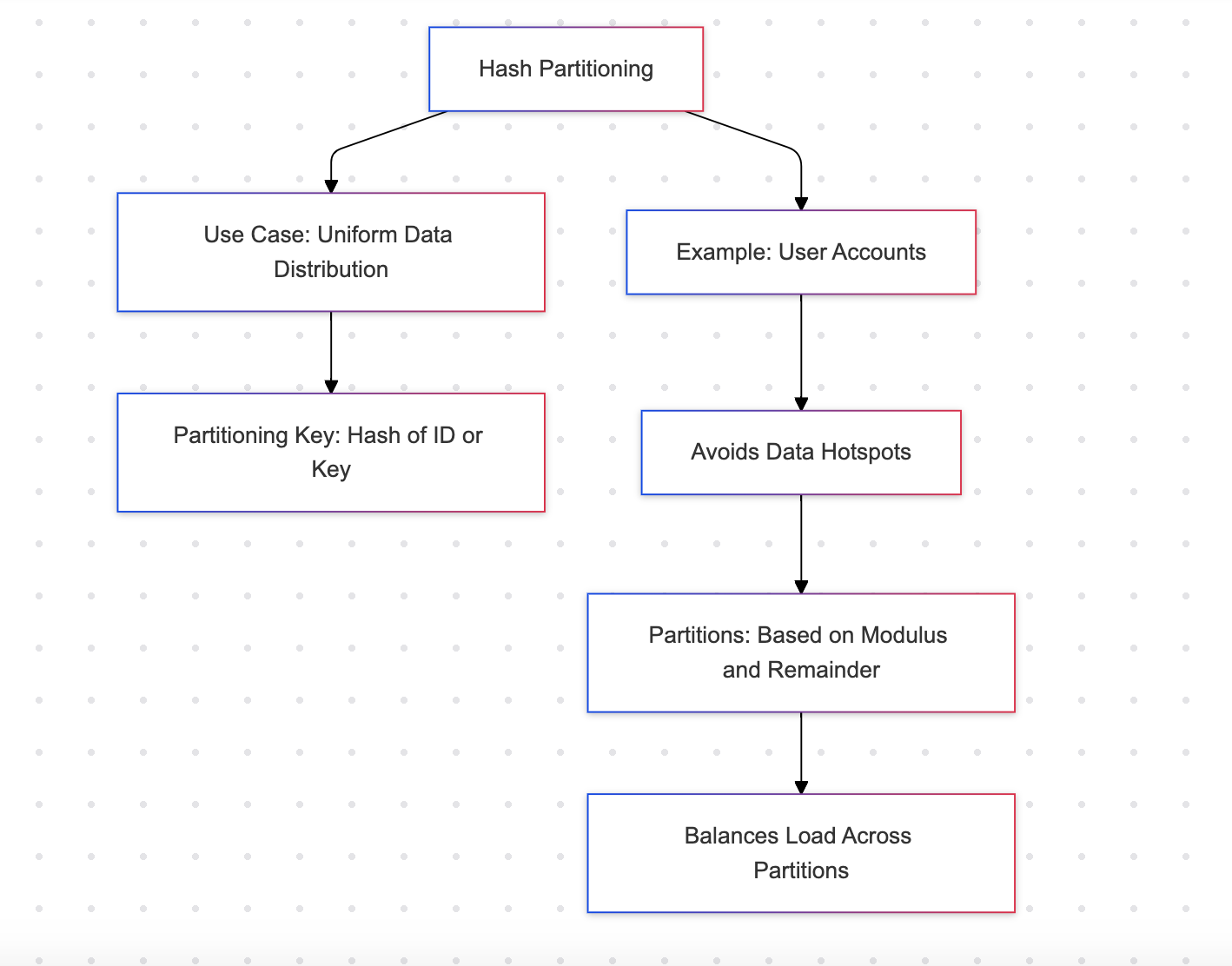
Example: User accounts
CREATE TABLE users (
user_id SERIAL,
username TEXT NOT NULL
) PARTITION BY HASH (user_id);
CREATE TABLE users_partition_0 PARTITION OF users
FOR VALUES WITH (MODULUS 4, REMAINDER 0);Advantages
- Ensures balanced distribution across partitions, preventing hotspots
- Suitable for evenly spread workloads
Disadvantages
- Not human-readable; partitions cannot be identified intuitively
pg_partman: A Comprehensive Guide
pg_partman is a PostgreSQL extension that simplifies partition management, particularly for time-based and serial-based datasets.
Installation and Setup
pg_partman requires installation as an extension in PostgreSQL. It provides a suite of functions to create and manage partitioned tables dynamically.
- Install using your package manager:
Shell
sudo apt-get install postgresql-pg-partman - Create the extension in your database:
SQL
CREATE EXTENSION pg_partman;
Configuring Partitioning
pg_partman supports time-based and serial-based partitioning, which are particularly useful for datasets with temporal data or sequential identifiers.
Time-Based Partitioning Example
CREATE TABLE logs (
id SERIAL,
log_time TIMESTAMP NOT NULL,
message TEXT
);
SELECT partman.create_parent(
p_parent_table := 'public.logs',
p_control := 'log_time',
p_type := 'time',
p_interval := 'daily'
);This configuration:
- Automatically creates daily partitions
- Simplifies querying and maintenance for log data
Serial-Based Partitioning Example
CREATE TABLE transactions (
transaction_id BIGSERIAL PRIMARY KEY,
details TEXT NOT NULL
);
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 100000
);This creates partitions every 100,000 rows, ensuring the parent table remains manageable.
Automation Features
Automatic Maintenance
Use run_maintenance() to ensure future partitions are pre-created:
SELECT partman.run_maintenance();Retention Policies
Define retention periods to drop old partitions automatically:
UPDATE partman.part_config
SET retention = '12 months'
WHERE parent_table = 'public.logs';Advantages of pg_partman
- Simplifies dynamic partition creation
- Automates cleanup and maintenance
- Reduces the need for manual schema updates
Practical Use Cases for Table Partitioning
- Log management. High-frequency logs partitioned by day for easy archival and querying.
- Multi-regional data. E-commerce systems dividing orders by region for improved scalability.
- Time-series data. IoT applications with partitioned telemetry data.
Log Management
Partition logs by day or month to manage high-frequency data efficiently.
SELECT partman.create_parent(
p_parent_table := 'public.server_logs',
p_control := 'timestamp',
p_type := 'time',
p_interval := 'monthly'
);Multi-Regional Data
Partition sales or inventory data by region for better scalability.
CREATE TABLE sales (
sale_id SERIAL,
region TEXT NOT NULL
) PARTITION BY LIST (region);High-Volume Transactions
Partition transactions by serial ID to avoid bloated indexes.
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 10000
);Conclusion
Table partitioning is an indispensable technique for managing large datasets. PostgreSQL’s built-in features, combined with the pg_partman extension, make implementing dynamic and automated partitioning strategies easier. These tools allow database administrators to enhance performance, simplify maintenance, and scale effectively.
Partitioning is a cornerstone for modern database management, especially in high-volume applications. Understanding and applying these concepts ensures robust and scalable database systems.
Opinions expressed by DZone contributors are their own.
Comments