How To Use Geo-Partitioning to Comply With Data Regulations and Deliver Low Latency Globally
Read a geo-partitioning guide to deploying a YugabyteDB Managed database cluster and optimizing data distribution across regions.
Join the DZone community and get the full member experience.
Join For FreeIn today's interconnected world, application users can span multiple countries and continents. Maintaining low latency across distant geographies while dealing with data regulatory requirements can be a challenge. The geo-partitioning feature of distributed SQL databases can help solve that challenge by pinning user data to the required locations.
So, let’s explore how you can deploy a geo-partitioned database cluster that complies with data regulations and delivers low latency across multiple regions using YugabyteDB Managed.
Deploying a Geo-Partitioned Cluster Using YugabyteDB Managed
YugabyteDB is an open-source distributed SQL database built on PostgreSQL. You can deploy a geo-partitioned cluster within minutes using YugabyteDB Managed, the DBaaS version of YugabyteDB.
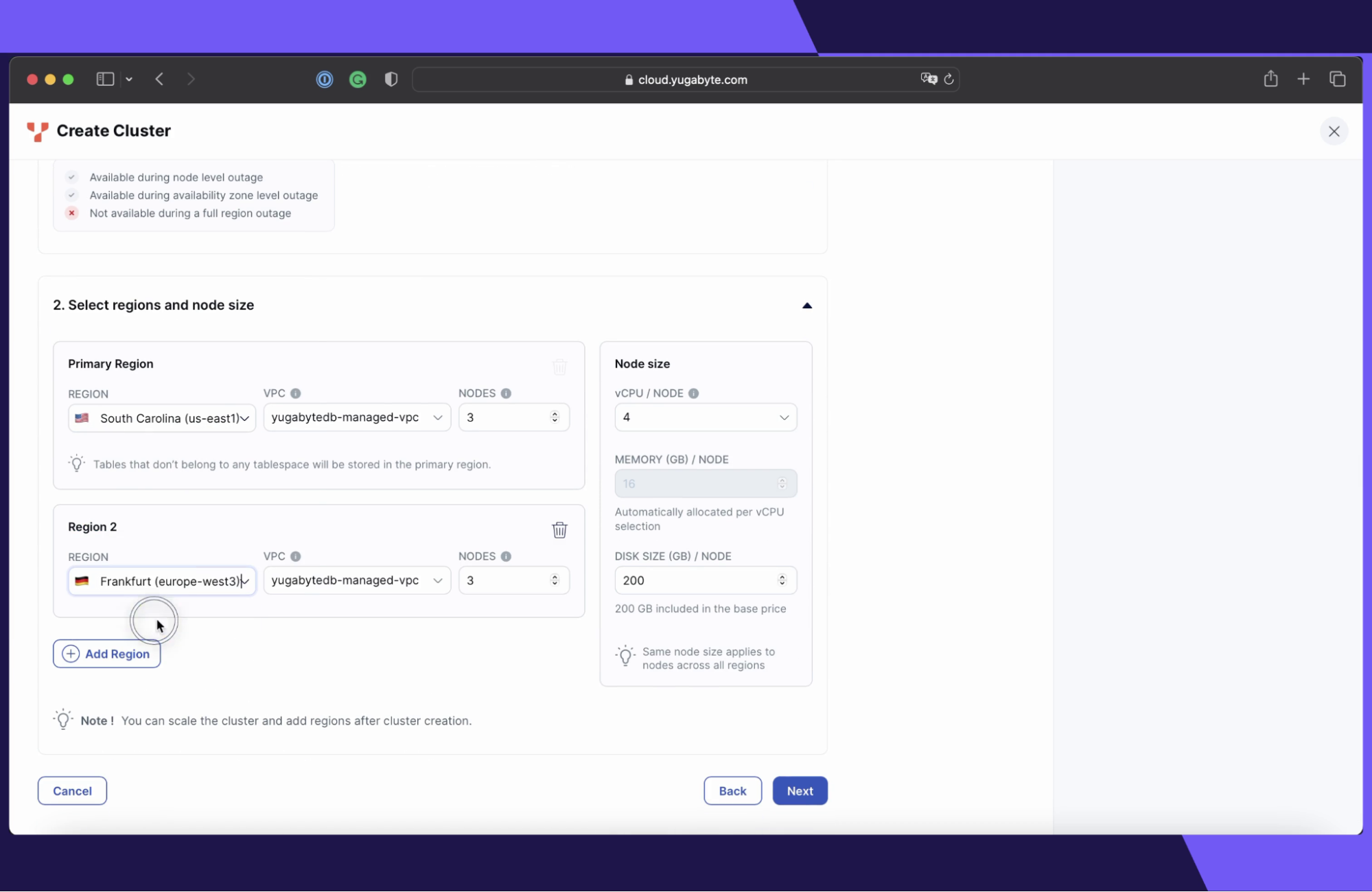
Getting started with a geo-partitioned YugabyteDB Managed cluster is easy. Simply follow the below:
- Select the Multi-region Deployment option. When creating a dedicated YugabyteDB Managed cluster, choose the “multi-region” option to ensure your data is distributed across multiple regions.
- Set the Data Distribution Mode to “partitioned." Select the "partition by region" data distribution option so that you can pin data to specific geographical locations.
- Choose target cloud regions. Place database nodes in the cloud regions of your choice. In this blog, we spread data across two regions - South Carolina (us-east1) and Frankfurt (europe-west3).
Once you've set up a geo-partitioned YugabyteDB Managed cluster, you can connect to it and create tables with partitioned data.
Create a Geo-Partitioned Table
To demonstrate how geo-partitioning improves latency and data regulation compliance, let's take a look at an example Account table.
First, create PostgreSQL tablespaces that let you pin data to the YugabyteDB nodes in the USA (usa_tablespace) or in Europe (europe_tablespace):
CREATE TABLESPACE usa_tablespace WITH (
replica_placement = '{"num_replicas": 3, "placement_blocks":
[
{"cloud":"gcp","region":"us-east1","zone":"us-east1-c","min_num_replicas":1},
{"cloud":"gcp","region":"us-east1","zone":"us-east1-d","min_num_replicas":1},
{"cloud":"gcp","region":"us-east1","zone":"us-east1-b","min_num_replicas":1}
]}'
);
CREATE TABLESPACE europe_tablespace WITH (
replica_placement = '{"num_replicas": 3, "placement_blocks":
[
{"cloud":"gcp","region":"europe-west3","zone":"europe-west3-a","min_num_replicas":1},
{"cloud":"gcp","region":"europe-west3","zone":"europe-west3-b","min_num_replicas":1},
{"cloud":"gcp","region":"europe-west3","zone":"europe-west3-c","min_num_replicas":1}
]}'
);num_replicas: 3- Each tablespace requires you to store a copy of data across 3 availability zones within a region. This lets you tolerate zone-level outages in the cloud.
Second, create the Account table and partition it by the country_code column:
CREATE TABLE Account (
id integer NOT NULL,
full_name text NOT NULL,
email text NOT NULL,
phone text NOT NULL,
country_code varchar(3)
)
PARTITION BY LIST (country_code);Third, define partitioned tables for USA and European records:
CREATE TABLE Account_USA PARTITION
OF Account (id, full_name, email, phone, country_code,
PRIMARY KEY (id, country_code))
FOR VALUES IN ('USA') TABLESPACE usa_tablespace;
CREATE TABLE Account_EU PARTITION
OF Account (id, full_name, email, phone, country_code,
PRIMARY KEY (id, country_code))
FOR VALUES IN ('EU') TABLESPACE europe_tablespace;FOR VALUES IN ('USA')- If thecountry_codeis equal to the ‘USA’, then the record is automatically placed or queried from theAccount_USApartition that is stored in theusa_tablespace(the region in South Carolina).FOR VALUES IN ('EU')- Otherwise, if the record belongs to the European Union (country_codeis equal to 'EU'), then it’s stored in theAccount_EUpartition from theeurope_tablespace(the region in Frankfurt).
Now, let’s examine the read-and-write latency when a user connects from the United States.
Latency When Connecting From the United States
Let’s open a client connection from Iowa (us-central1) to a database node located in South Carolina (us-east1) and insert a new Account record:
INSERT INTO Account (id, full_name, email, phone, country_code)
VALUES (1, 'John Smith', '[email protected]', '650-346-1234', 'USA');As long as the country_code is 'USA', the record will be stored on the database node from South Carolina. The write and read latency will be approximately 30 milliseconds because the client requests need to travel between Iowa and South Carolina.

Next, let’s see what happens when we add and query an account with the country_code set to 'EU':
INSERT INTO Account (id, full_name, email, phone, country_code)
VALUES (2, 'Emma Schmidt', '[email protected]', '49-346-23-1234', 'EU');
SELECT * FROM Account WHERE id=2 and country_code='EU';Since this account must be stored in a European data center and must be transferred between the United States and Europe, the latency increases.

- The latency for the INSERT (230 ms) is higher than for the SELECT (130 ms) because during the INSERT the record is replicated across three availability zones in Frankfurt.
The higher latency between the client connection in the USA and the database node in Europe signifies that the geo-partitioned cluster makes you compliant with data regulatory requirements. Even if the client from the USA connects to the US-based database node and writes/reads records of residents from the European Union, those records will always be stored/retrieved from database nodes in Europe.
Latency When Connecting From Europe
Let’s see how the latency improves if you open a client connection from Frankfurt (europe-west3) to the database node in the same region, and query the European record recently added from the USA:

This time the latency is as low as 3 milliseconds (vs. 130 ms when you queried the same record from the USA) because the record is stored in and retrieved from European data centers.
Adding and querying another European record also maintains low latency, as long as the data is not replicated to the United States.
INSERT INTO Account (id, full_name, email, phone, country_code)
VALUES (3, 'Otto Weber', '[email protected]', '49-546-33-0034', 'EU');
SELECT * FROM Account WHERE id=3 and country_code='EU';
When accessing data stored in the same region, latency is significantly reduced. The result is a much better user experience while remaining compliant with data regulatory requirements.
Wrap Up
Geo-partitioning is an effective way to comply with data regulations and achieve global low latency. By deploying a geo-partitioned cluster using YugabyteDB Managed, it's possible to intelligently distribute data across regions, while maintaining high-performance querying capabilities.
Opinions expressed by DZone contributors are their own.
Comments