What Developers Need to Know About Table Partition Maintenance
Learn more on the importance of table partition maintenance.
Join the DZone community and get the full member experience.
Join For FreeTable partitioning is a very convenient technique supported by several databases including MySQL, Oracle, PostgreSQL, and YugabyteDB. In the first article of this series, we discussed an application that automates the operations of a large pizza chain. We reviewed how PostgreSQL improves the application’s performance with the partition pruning feature by eliminating unnecessary partitions from the query execution plan.
In this article, we’ll examine how PostgreSQL’s partition maintenance capabilities can further influence and simplify the architecture of your apps. We’ll again take the pizza chain app as an example, whose database schema comes with the PizzaOrders table. To remind you, the table tracks the order’s progress (table data is explained in the first article):
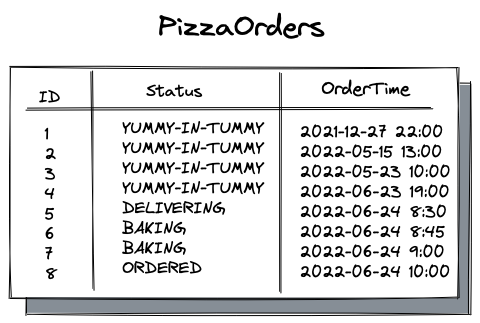
Now, pretend you need to separate the orders for the current, previous, and all other earlier months. So, you go ahead and partition the PizzaOrders by the OrderTime column:
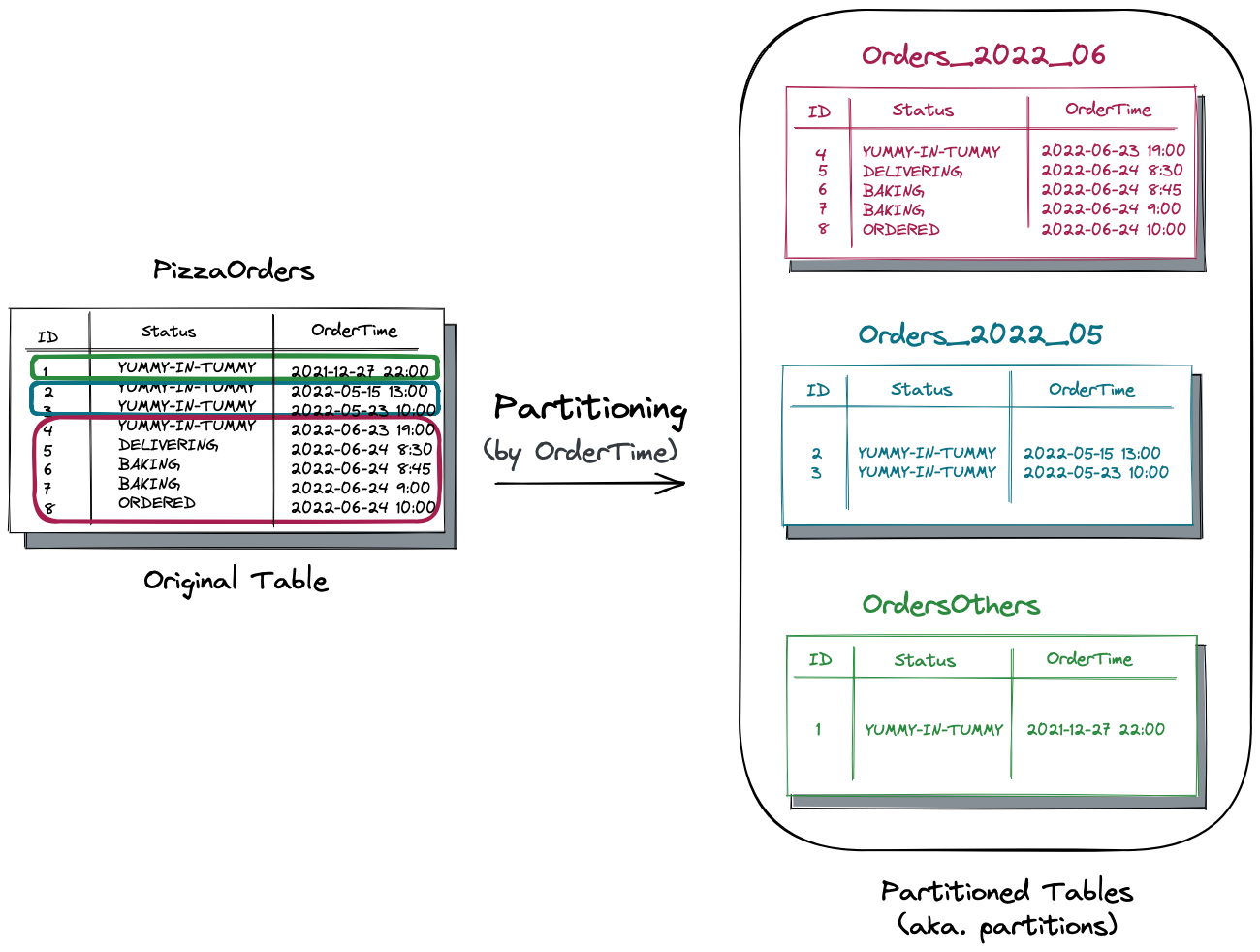 As a result, the original table gets split into three partitioned tables or partitions:
As a result, the original table gets split into three partitioned tables or partitions:
Orders_2022_06- the table keeps all the orders for the current month (June 2022). Suppose that the customer-facing microservices heavily use the data from this partition.Order_2022_05- the table stores orders for the previous month (May 2022). Assume internal microservices that facilitate short-term planning regularly query this data in combination with the current month’s data.OrdersOthers- the remaining historical data used by the BI tools for strategic planning.
Nice, you can partition data by time, and the database will ensure each microservice queries only the data it needs. But, wait, the current and past months are not static notions. Once the calendar page flips to July 1st, July 2020 will become the current month. But how do you reflect this change at the database level? Let’s talk about partition maintenance techniques.
Partition Maintenance
The structure of your partitions might be dynamic. Quite frequently, you might want to remove partitions holding old data and add new partitions with the new data. That’s the case with our pizza chain. And this maintenance task can be easily fulfilled at the database level with no code changes on the application side.
In PostgreSQL, partitions are regular tables that you can query or alter directly. So, whenever necessary you can use standard DDL commands to CREATE, ATTACH, DETACH, and DROP partitions.
Creating Original Partitions
First, let’s create the original partitions that we’ve discussed above:
CREATE TYPE status_t AS ENUM('ordered', 'baking', 'delivering', 'yummy-in-my-tummy');
CREATE TABLE PizzaOrders
(
id int,
status status_t,
ordertime timestamp
) PARTITION BY RANGE (ordertime);
CREATE TABLE orders_2022_06 PARTITION OF PizzaOrders
FOR VALUES FROM('2022-06-01') TO ('2022-07-01');
CREATE TABLE orders_2022_05 PARTITION OF PizzaOrders
FOR VALUES FROM('2022-05-01') TO ('2022-06-01');
CREATE TABLE orders_others PARTITION OF PizzaOrders DEFAULT;The PARTITION BY RANGE (order_time) clause requests to split the PizzaOrders table using the Range Partitioning method. The resulting partitions will keep the orders based on the value of the ordertime column. For instance, if the ordertime is between '2022-06-01' (inclusive) and '2022-07-01' (exclusive), then a pizza order goes into the current month’s partition (which is orders_2022_06). The orders_others partition is the DEFAULT one as it will keep all the orders that ordertime value doesn’t fit into the range of any other partition.
Second, all the created partitions are regular tables that you can work with using DDL and DML commands. For instance, let’s load sample data and query the current month’s partitioned table directly:
INSERT INTO PizzaOrders VALUES
(1, 'yummy-in-my-tummy', '2021-12-27 22:00:00'),
(2, 'yummy-in-my-tummy', '2022-05-15 13:00:00'),
(3, 'yummy-in-my-tummy', '2022-05-23 10:00:00'),
(4, 'yummy-in-my-tummy', '2022-06-23 19:00:00'),
(5, 'delivering', '2022-06-24 8:30:00'),
(6, 'baking', '2022-06-24 8:45:00'),
(7, 'baking', '2022-06-24 9:00:00'),
(8, 'ordered', '2022-06-24 10:00:00');
SELECT * FROM orders_2022_06 WHERE ordertime BETWEEN '2022_06_20' AND '2022_06_30';
id | status | ordertime
----+-------------------+---------------------
4 | yummy-in-my-tummy | 2022-06-23 19:00:00
5 | delivering | 2022-06-24 08:30:00
6 | baking | 2022-06-24 08:45:00
7 | baking | 2022-06-24 09:00:00
8 | ordered | 2022-06-24 10:00:00It’s certainly handy that we can query partitioned tables directly. However, you don’t want your customer-facing microservices to remember the actual current month and what partition to query. Instead, the microservices will be querying the top-level PizzaOrders table and PostgreSQL will apply the partitioning pruning optimization the following way:
EXPLAIN ANALYZE SELECT * FROM PizzaOrders
WHERE ordertime BETWEEN '2022_06_20' AND '2022_06_30';
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on orders_2022_06 pizzaorders (cost=0.00..37.75 rows=9 width=16) (actual time=0.010..0.012 rows=5 loops=1)
Filter: ((ordertime >= '2022-06-20 00:00:00'::timestamp without time zone) AND (ordertime <= '2022-06-30 00:00:00'::timestamp without time zone))
Planning Time: 0.122 ms
Execution Time: 0.040 msThis is the same query but PostgreSQL (and not your application layer) decides which partition keeps the data. The execution plan shows that the query ran against the orders_2022_06 partition, bypassing the others.
However, this ability to work with partitioned tables directly is extremely useful when you need to change the structure of your partitions. Now, assume that tomorrow is July 1st, 2022. You need to add a new partition that will keep the orders for that new current month (July), as well as introduce a few other changes.
Detaching Old Partitions
Let’s first deal with partition orders_2022_05 that presently holds data for the “previous month” (May 2022). You do this because once July becomes the “current month”, June will become the “previous month”, according to the application logic.
First, let’s remove the May partition from the partitions structure using the DETACH command:
ALTER TABLE PizzaOrders DETACH PARTITION orders_2022_05; Once you do this, attempt to read all the records from the PizzaOrders table to confirm there are no records left for May:
SELECT * FROM PizzaOrders;
id | status | ordertime
----+-------------------+---------------------
4 | yummy-in-my-tummy | 2022-06-23 19:00:00
5 | delivering | 2022-06-24 08:30:00
6 | baking | 2022-06-24 08:45:00
7 | baking | 2022-06-24 09:00:00
8 | ordered | 2022-06-24 10:00:00
1 | yummy-in-my-tummy | 2021-12-27 22:00:00Don’t get scared, the data for May didn’t evaporate! The data is still in the same partitioned table that you can query directly:
SELECT * FROM orders_2022_05;
id | status | ordertime
----+-------------------+---------------------
2 | yummy-in-my-tummy | 2022-05-15 13:00:00
3 | yummy-in-my-tummy | 2022-05-23 10:00:00Next, do you remember that we have the orders_others partition that keeps all the orders that the ordertime column doesn’t fit into the ranges of other partitions? Now go ahead and put the records for May there. You can do this by inserting the data into the top-level PizzaOrders table and letting PostgreSQL arrange records across partitions:
INSERT INTO PizzaOrders (id,status,ordertime)
SELECT detached.id, detached.status, detached.ordertime
FROM orders_2022_05 as detached;Lastly, you can safely drop the orders_2022_05 partition because you already have a copy of the orders for May in the orders_others partition:
DROP TABLE orders_2022_05;
SELECT tableoid::regclass,* from PizzaOrders
ORDER BY id;
tableoid | id | status | ordertime
----------------+----+-------------------+---------------------
orders_others | 1 | yummy-in-my-tummy | 2021-12-27 22:00:00
orders_others | 2 | yummy-in-my-tummy | 2022-05-15 13:00:00
orders_others | 3 | yummy-in-my-tummy | 2022-05-23 10:00:00
orders_2022_06 | 4 | yummy-in-my-tummy | 2022-06-23 19:00:00
orders_2022_06 | 5 | delivering | 2022-06-24 08:30:00
orders_2022_06 | 6 | baking | 2022-06-24 08:45:00
orders_2022_06 | 7 | baking | 2022-06-24 09:00:00
orders_2022_06 | 8 | ordered | 2022-06-24 10:00:00Attaching New Partitions
Finally, let’s create a partition for July that’s about to become the “current month”, in accordance with the application logic.
The most straightforward way to do this is by attaching a new partition to the PizzaOrders table:
CREATE TABLE orders_2022_07 PARTITION OF PizzaOrders
FOR VALUES FROM('2022-07-01') TO ('2022-08-01');The name of the new partition is orders_2022_07 and it’s added to the partitions structure:
\d+ PizzaOrders;
Partitioned table "public.pizzaorders"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
-----------+-----------------------------+-----------+----------+---------+---------+-------------+--------------+-------------
id | integer | | | | plain | | |
status | status_t | | | | plain | | |
ordertime | timestamp without time zone | | | | plain | | |
Partition key: RANGE (ordertime)
Partitions: orders_2022_06 FOR VALUES FROM ('2022-06-01 00:00:00') TO ('2022-07-01 00:00:00'),
orders_2022_07 FOR VALUES FROM ('2022-07-01 00:00:00') TO ('2022-08-01 00:00:00'),
orders_others DEFAULTEasy, isn’t it? Let’s test the changes by inserting dummy data for July 2022 and checking what partition those records belong to:
INSERT INTO PizzaOrders VALUES
(9, 'ordered', '2022-07-02 10:00:00'),
(10, 'baking', '2022-07-02 9:50:00'),
(11, 'yummy-in-my-tummy', '2022-07-01 18:10:00');
SELECT tableoid::regclass,* from PizzaOrders
ORDER BY id;
tableoid | id | status | ordertime
----------------+----+-------------------+---------------------
orders_others | 1 | yummy-in-my-tummy | 2021-12-27 22:00:00
orders_others | 2 | yummy-in-my-tummy | 2022-05-15 13:00:00
orders_others | 3 | yummy-in-my-tummy | 2022-05-23 10:00:00
orders_2022_06 | 4 | yummy-in-my-tummy | 2022-06-23 19:00:00
orders_2022_06 | 5 | delivering | 2022-06-24 08:30:00
orders_2022_06 | 6 | baking | 2022-06-24 08:45:00
orders_2022_06 | 7 | baking | 2022-06-24 09:00:00
orders_2022_06 | 8 | ordered | 2022-06-24 10:00:00
orders_2022_07 | 9 | ordered | 2022-07-02 10:00:00
orders_2022_07 | 10 | baking | 2022-07-02 09:50:00
orders_2022_07 | 11 | yummy-in-my-tummy | 2022-07-01 18:10:00Done! You could easily change the structure of the partitions by detaching the partition for May and attaching a new one for July. And no changes were necessary on the application side. Our microservices continued to query the PizzaOrders table directly without bothering underlying partitions.
To Be Continued…
Alright, with this article we finished the review of partition pruning and maintenance capabilities that can improve performance and facilitate the design of your application. Check out this PostgreSQL resource to learn more.
In a follow-up article, you’ll learn how to use geo-partitioning to pin pizza orders to a specific geographic location. After all, we’ve been working on the application for a large pizza chain that feeds and delights customers across countries and continents. Stay tuned!
Opinions expressed by DZone contributors are their own.
Comments