Apache Storm Tutorial
We cover the basics of Apache Storm and implement a simple example of Store that we use to count the words in a list.
Join the DZone community and get the full member experience.
Join For FreeStorm is a open source, real-time distributed computation system designed to process real-time data. It is designed to process petabytes of data coming in from different data sources, process it, and publish results to a UI or to any other place. One popular use case is to process and analyze the hashtags that are trending most on Twitter.
It is extremely fast and a benchmark has clocked it at processing a million tuples per second per node. Let's perform a basic comparison between Storm and Hadoop:
Hadoop |
Apache Strom |
It is used for distributed batch processing of data. |
It is used for distributed real-time processing of data. |
Latency is high due to batch processing of data. |
Latency is low due to real-time processing of data. |
Its architecture consists of HDFS for data storage and Map-Reducefor data storage. |
Its architecture consists of spouts and bolts. |
It is stateful in nature so that if a stream stops the latest state needs to be saved. |
It is stateless and thereby simpler to implement. |
Open source |
Open source |
Storm Architecture

Topology
The complete logic for defining a series of steps, streams, and bolts are defined in the Topology. It also contains definitions to specify if a local topology or a remote topology are required.
Spouts
A spout is a stream source for bolts. It reads data from different data sources and emits a tuple as its output. A spout can further be categorized into the below two categories:
Reliable: It replays a tuple if it is not processed by any bolt.
Unreliable: It does not replays a tuple even if it is not processed by any bolt.
Bolts
A bolt processes the tuple emitted by a spout. There can be multiple bolts in a topology that can be used to either perform sequential or parallel execution of tuples. Bolts can be used to perform filtering, aggregation, joins, etc.
A complete operation, like processing data from Twitter, may require multiple bolts that will execute sequentially for performing operations like: filtering relevant tweets, using a bolt for aggregating the hashtags, and then using another bolt for writing it in a file as an output.
Tuple
A tuple is a list of value that may be of the same or different types.
Working Example
We will create a Storm topology to count the number of times a word appears in a collection. For this, we will create a spout, a bolt, and define a topology that can run in a local cluster.
1. Create a Maven Project
Copy the following content into a pom.xmlfole
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.sagar</groupId>
<artifactId>storm</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>storm</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- This is a version of Storm from the Hortonworks repository that is
compatible with HDInsight 3.6. -->
<storm.version>1.1.0.2.6.1.9-1</storm.version>
</properties>
<repositories>
<repository>
<releases>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>warn</checksumPolicy>
</releases>
<snapshots>
<enabled>false</enabled>
<updatePolicy>never</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
<id>HDPReleases</id>
<name>HDP Releases</name>
<url>https://repo.hortonworks.com/content/repositories/releases/</url>
<layout>default</layout>
</repository>
<repository>
<releases>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>warn</checksumPolicy>
</releases>
<snapshots>
<enabled>false</enabled>
<updatePolicy>never</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
<id>HDPJetty</id>
<name>Hadoop Jetty</name>
<url>https://repo.hortonworks.com/content/repositories/jetty-hadoop/</url>
<layout>default</layout>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
<!-- keep storm out of the jar-with-dependencies -->
<scope>provided</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>true</includeProjectDependencies>
<includePluginDependencies>false</includePluginDependencies>
<classpathScope>compile</classpathScope>
<mainClass>${storm.topology}</mainClass>
<cleanupDaemonThreads>false</cleanupDaemonThreads>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
<resources>
<resource>
<directory>${basedir}/resources</directory>
<filtering>false</filtering>
<includes>
<include>log4j2.xml</include>
</includes>
</resource>
</resources>
</build>
</project>2. Create a Spout
IRichSpout: This is an interface that needs to be implemented by the Java class that will work as a spout. It has a few key methods that need to be overridden and explained as below:
open: This method can be used to provide/load the configuration for the spout. It is called only once the spout is created.nextTuple: This method is used to emit a tuple to be processed by the bolt. It can define the logic for reading from the different datasources, like a file or an external data-source.declareOutputField: This method is used to declare the structure of the tuple that will be produced by this spout.
There are some other useful methods defined in a spout that can be used for ensuring reliability. However, they do not fall under the scope of this article and will be covered in my next article in detail.
package com.sagar.wordcount;
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichSpout;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
public class WordReaderSpout implements IRichSpout {
/**
*
*/
private static final long serialVersionUID = 441966625018520917 L;
private SpoutOutputCollector collector;
private String[] sentences = {
"Hello World",
"Apache Storm",
"Big Data",
"Big Data",
"Machine Learning",
"Hello World",
"World",
"Hello"
};
boolean isCompleted;
String fileName;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void close() {
// TODO Auto-generated method stub
}
@Override
public void activate() {
// TODO Auto-generated method stub
}
@Override
public void deactivate() {
// TODO Auto-generated method stub
}
@Override
public void nextTuple() {
if (!isCompleted) {
for (String sentence: sentences) {
for (String word: sentence.split(" ")) {
this.collector.emit(new Values(word));
}
}
isCompleted = true;
} else {
this.close();
}
}
@Override
public void ack(Object msgId) {
// TODO Auto-generated method stub
}
@Override
public void fail(Object msgId) {
// TODO Auto-generated method stub
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public Map < String, Object > getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}In the above code, we are reading from a file that contains different words in a new line. In the open method we have created a input stream that will be used to read data from a file.
In the declareOutputFields method, we have declared the structure of a tuple.
In the nextTuple method, we are removing the word that is read from the array.
3. Create a Bolt
IRichBolt: This is an interface that needs to be implemented by a class that needs to be defined in a bolt. It has several methods that are overridden by the child class. Some of the key methods are as follows:
prepare: This method is called only once a bolt is created. It has a reference to a Storm context and a config object to read configurations provided in the topology.execute: This method contains the actual processing logic.cleanup: This method is called when a bolt is getting killed to cleanup the resources.
package com.sagar.wordcount;
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Tuple;
public class WordCountBolt implements IRichBolt {
/**
*
*/
private static final long serialVersionUID = -4130092930769665618 L;
Map < String, Integer > counters;
Integer id;
String name;
String fileName;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.counters = new HashMap < > ();
this.name = context.getThisComponentId();
this.id = context.getThisTaskId();
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
if (!counters.containsKey(word)) {
counters.put(word, 1);
} else {
counters.put(word, counters.get(word) + 1);
}
}
@Override
public void cleanup() {
System.out.println("Final word count:::::");
for (Map.Entry < String, Integer > entry: counters.entrySet()) {
System.out.println(entry.getKey() + "-" + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
@Override
public Map < String, Object > getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}In the above snippet, the prepare method has initialized the empty HashMap.
The execute method will read every word emitted by the spout and put them in a HashMap with the key as a word and the value as its counter. A value is incremented by 1 if a word appears again in the file.
The cleanup method is used to clean the resources once the processing is completed.
4. Create a Topology
package com.sagar.wordcount;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
public class WordCountTopology {
public static void main(String args[]) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word-reader", new WordReaderSpout());
builder.setBolt("word-counter", new WordCountBolt(), 1).shuffleGrouping("word-reader");
Config conf = new Config();
conf.setDebug(true);
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("wordcounter-topology", conf, builder.createTopology());
try {
Thread.sleep(10000);
localCluster.shutdown();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
localCluster.shutdown();
}
}
}TopologyBuilderis a class that is used to create a Storm topology. A template for creating a topology is provided above.
In line 12, we have defined a spout with a unique name and created an object with a spout class and passed it as a parameter in the method.
In line 13, we have defined a bolt with a unique name and created an object with bolt class and passed it as a parameter in the method and the number of instances of bolt that need to be initialized. In our case, we have initialized two bolts.
Also we have defined a grouping strategy with shuffleGrouping. It randomly distributes the tuple among bolts. There are other grouping strategies as well that are not covered in this article.
In line 14, we have a config object and defined few config paramters that will be passed and available to both the spout and bolt.
In line 19, we have created a local cluster. In this, we need not to install ZoopKeeper, Nimbus, and a Storm Server separately that can be used internally by Storm.
We have submitted the topology to the local cluster and assigned it a unique name.
Finally, we are shutting down the cluster in the main method.
5. Output
We get a word count for each and every word passed to the spout.
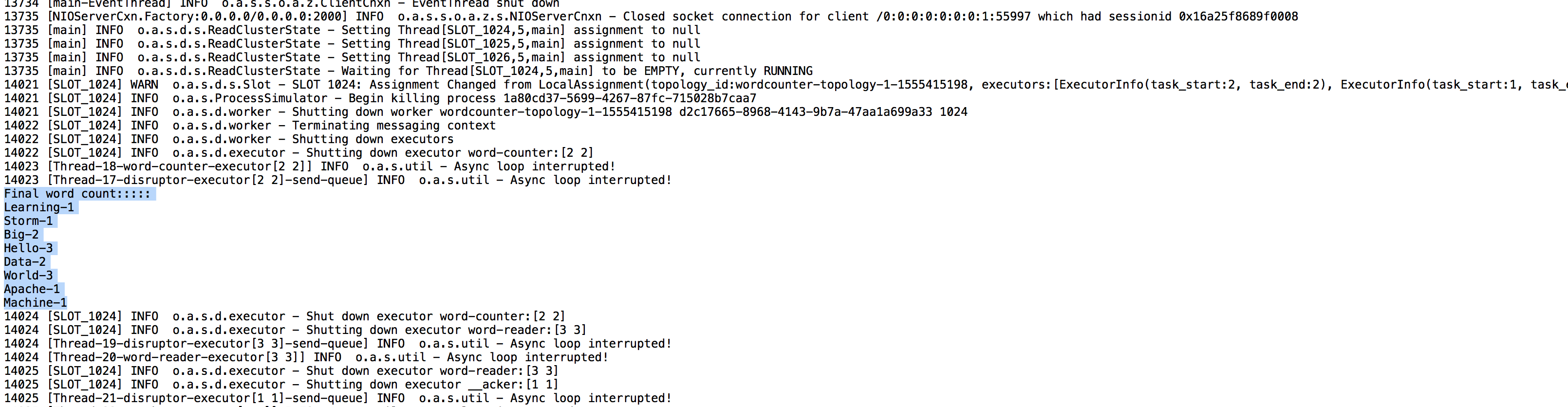
We have covered the basics of Apache Storm and implemented a simple example to count the words in the list. Hope you enjoyed this article!
Opinions expressed by DZone contributors are their own.
Comments