Architectural Shift in Web Applications
Let's jump right into this series with a look at architectural shifts that have occurred recently in web application.
Join the DZone community and get the full member experience.
Join For FreeThe application development landscape has been changing continuously over the past few years, both on the client side (frontend) as well as on the server side (backend). On the client side, we have plenty of awesome new and updated JavaScript [and other scripting] frameworks; and on the server side, we have new architectural approaches such as single page applications, microservices, and serverless architectures.
This is going to be a series of articles for full stack developers, especially those coming from a server side background, introducing trends and best practices in web application design and development. To kick off this series, let’s start by looking into the server side architectural shifts that have been taking place.
The Recent Past: The Traditional N-Tier Architecture
In the last decade, the web has dominated as the preferred platform for delivering content and services. As a result, every business wanted to be online, and to meet this explosion in demand, developers adopted an N-Tier architectural approach to quickly build and deploy reliable applications.
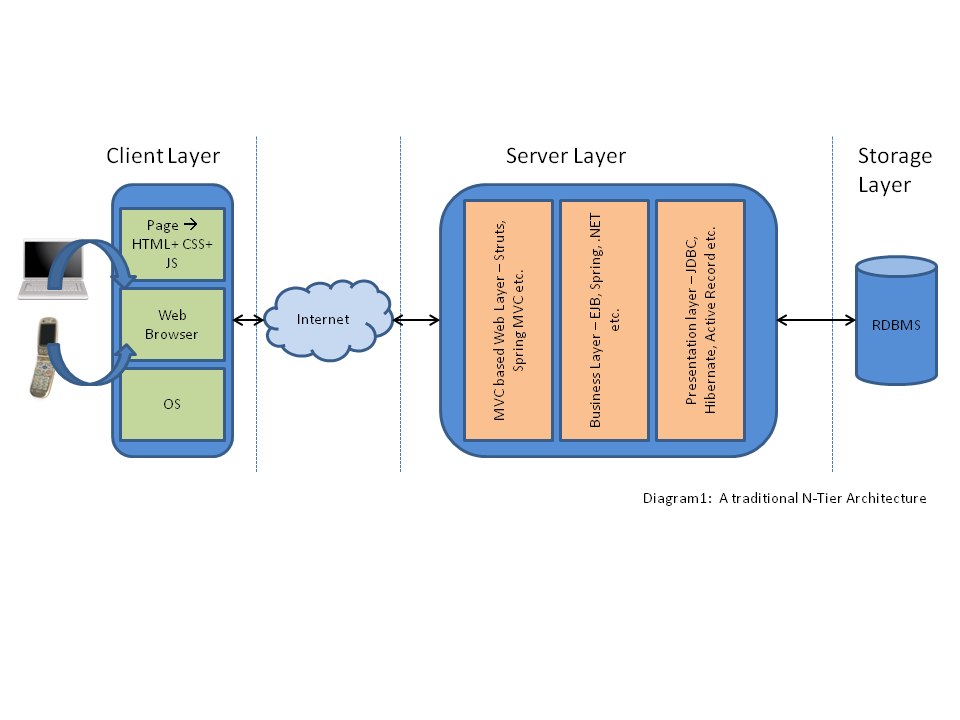
An N-Tier architecture consists of multiple independent layers; each layer represents a different concern of the system. From a high level, most systems are generally divided into three main layers: client, server, and storage.
The Client Layer is what the end user sees and interacts with and usually refers to either a thin client (like a web browser) or a thick client (like a full blown Java Swing/.Net based application).
The Storage Layer retains important data over time, even when power is turned off, and is often a basic relational database system (like MySQL, Oracle, or SQLServer).
The Server Layer sits between the Client and Storage layers and is where all the real action of the application takes place. Since so much happens within this layer, the Server Layer is usually further divided into multiple sub-layers: web, ubsiness, and persistence.
The Server Web Layer is the entry point of the application on the server side, and is responsible for handling user interactions, converting requests to models, generating and delivering dynamic User Interfaces, session management, and other tasks. Many Java developers rely on frameworks such as Spring MVC or Struts to implement this layer.
The Server Business Layer is where business logic is implemented as a carefully composed and well defined API (Application Programming Interface - a collection of function calls). Technologies like EJB, .NET, and Spring are often leveraged to implement this layer.
The Server Persistence Layer is responsible for abstracting away the application’s interaction with the Storage Layer’s specific relational database via Object Relational Mapping (ORM) tools like Hibernate, EclipseLink, Spring JDBC Template, or other ORM tools.
The following diagram (1) depicts the traditional N-Tier Architecture.
Architectural Shift #1:The Rise of Single Page Applications (SPA)
We woke up to new era of AJAX with the overnight success of applications like Gmail and Google Maps, where refreshing the entire page became a thing of the past. Applications were now designed to request only the necessary bits and pieces (partial responses) of content and information as needed to create highly interactive user experiences using Thin Clients that up until now were only possible using Thick Clients. The additional logic required to do this on the client side wasn’t anything dramatically new — it was almost the same thing that had been previously used in the Server Web Layer. We essentially moved the Web Layer from the server to the client (Web Browser).
However, this additional logic on the client side brought about new challenges and complexities, such as having to deal with numerous XMLHttpRequests and understand the web browser’s DOM (Document Object Model) at a much deeper level than ever before necessary. To handle this added complexity many new JavaScript based frameworks emerged to handle low-level details and routine actions. Some frameworks are opinionated and some are not; some are bare bones and some are end-to-end solutions. And while it seemed like a new framework was appearing every other day, the good ones were all leveraging the same best practices and patterns that had been previously used with success in the Server Web Layer including Components, MVC (Model, View and Controller), Annotations, Dependency Injection, Services and Contracts by Interfaces etc.
Since the Web Layer was removed from the Server Layer and moved to the Client Layer, a new thin layer was introduced to the Server Layer in order to expose the existing Server Business Layer directly to the new Client Web Layer. This was most frequently done using custom SOAP or REST APIs. The creation of these APIs and the architectural shift in the placement of the Web Layer paved the way to support functionalities like off-line support, but more importantly, the ability to support multiple client types, even those with different native implementations, using the same back end (think of a single backend powering iOS and Android apps, as well as desktop and mobile Web interfaces).
The following diagram (2) depicts Architectural Shift 1: The moving of the Web Layer from the Server to the Client.

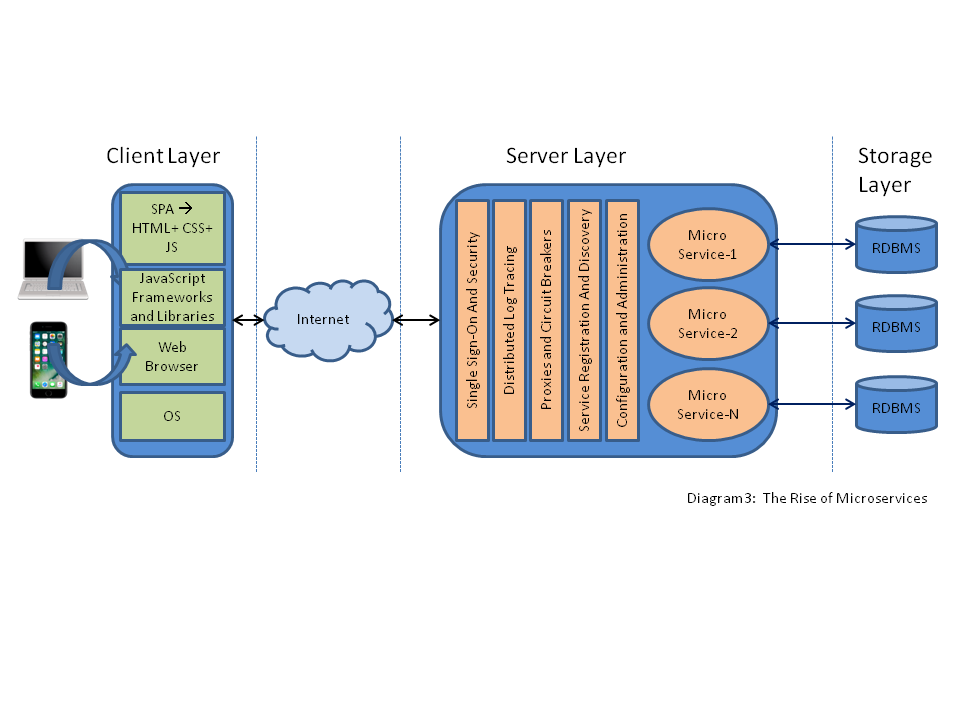
Architectural Shift #2: The rise of Microservices
The traditional way of building and deploying an application as a single tarball is how monolithic applications are created. A microservice is a tiny application that implements just a small subset of the full applications functionalities. The goal of a microservice is to do one thing, and do that one thing well, and can be implemented using almost any technical stack, not necessarily the same stack as other services. Having numerous microservices increases the complexity in distributed management, inter microservice communication, authentication and authorization, distributed logging and tracing, service registration and discovery, reverse proxy and gateways, etc. There are frameworks like Spring and Lagom that can make implementation easier by abstracting away much of this distributed nature.
Although microservices are the current shinny new trend in building modern applications, there is nothing inherently wrong with choosing to design and build a monolithic application. Monolithic applications are easy to deploy, manage and develop from a single codebase as long your software scalability needs and rate of requirement changes are constant.
However, when the application’s feature growth and/or uptime requirements and scalability needs are very high – it would be wise to consider refactoring or designing your application as a set of microservices. Microservices allow an application to scale horizontally and change independently, but these benefits do not come for free. Distributed applications are notoriously difficult to monitor, manage and test.
The following diagram (3) depicts Architectural Shift 2: The Rise of Microservices.
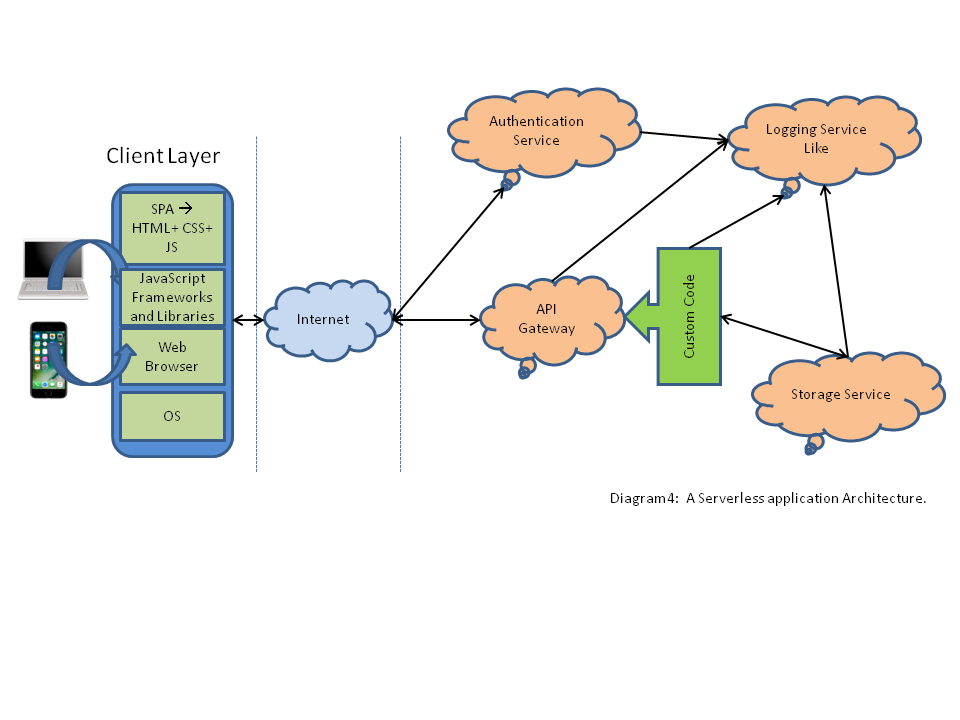
Architectural Shift #3: The Serverless Architecture
Serverless Architecture is a buzzword you’ll frequently see in headlines today. I intentionally do not want to call it the next iteration of web application architecture just yet. It’s more of an interesting idea for now.
The concept is pretty simple – we already have a Client Web Layer, so why not refactor (or design) the backend to leverage third-party hosted services for cross cutting concerns; by using Lambda (or pure functions) your application can execute any required custom logic on a third party’s cloud infrastructure. It’s a very similar concept to microservices, however, the primary difference is that you do not own the backend services, hence you do not need to develop, manage, nor support those services and hardware on which they run, thereby making your life simpler.
This idea of baking all cross cutting concerns (including persistence) into the infrastructure has many advantages. It will potentially simplify the distributed application architecture a lot, but it will also take time before all of the issues get worked out and serverless architectures become mainstream. Currently, serverless architectures stand in the same position where cloud hosting was a few year’s back; where enterprises and customers were more focused on cloud hostings threat to data privacy, rather than seeing its full potential for infrastructure simplification.
The following diagram (4) depicts Architectural Shift (?): The Serverless Architecture.
Opinions expressed by DZone contributors are their own.
Comments