Architecture for Building a Serverless Data Pipeline Using AWS
This article will walk you through architecture patterns that can be used to process data in batches and in near-real time depending on the use case.
Join the DZone community and get the full member experience.
Join For FreeThis article was authored by AWS Solutions Architect, Zaiba Jamadar, and published with permission.
“Data powers everything we do.”
- Jeff Weiner
Organizations have been looking for ways to derive useful insights from the data to derive business value. Developers, data analysts, and data scientists spend a lot of their time provisioning and maintaining infrastructure. This blog post will walk you through architecture patterns that can be used to process data in batches and in near-real time depending on the use case.
AWS Serverless services allow us to build applications without having to worry about provisioning servers, scaling servers, and managing resource utilization.
Apache Kafka allows multiple data producers - e.g, websites, Internet of Things (IoT) devices, Amazon Elastic Compute Cloud (Amazon EC2) instances - to continuously publish streaming data and categorize it using Apache Kafka topics. Multiple data consumers (e.g., Machine Learning applications, AWS Lambda functions, or microservices) read from these topics at their own rate, similar to a message queue or enterprise messaging system.
In this blog post, I will walk you through the architecture that can be leveraged to build a Serverless Apache Kafka Data Pipeline which enables data to be consumed from different client applications and visualized by using Amazon QuickSight and Amazon OpenSearch Service (using both services to show different options but based on the use case, certain service can be selected over the other service).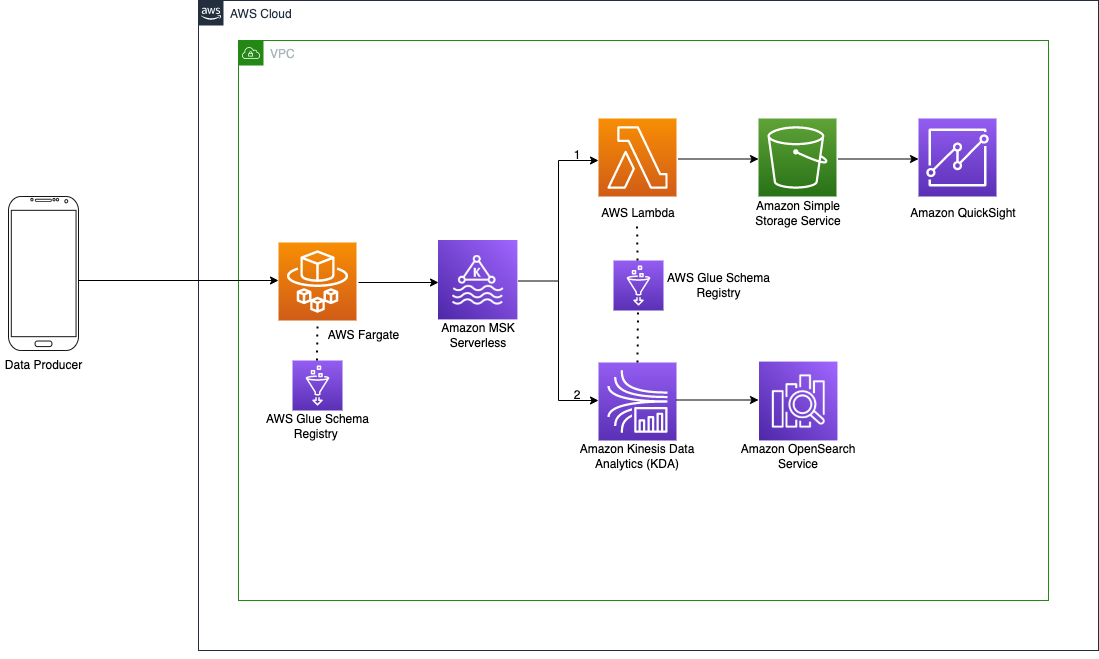 For the purposes of the blog post, let's consider a use case where an e-commerce application is running on AWS Fargate which is producing clickstream data. Before we discuss how the data can be processed in batches and in real time, let's discuss how the data being produced can be consumed using AWS Serverless Services. This clickstream can be consumed by Amazon MSK Serverless. Clickstream data is unstructured and therefore enforcing a uniform schema can be difficult. We can use AWS Glue Schema Registry to enforce a uniform schema.
For the purposes of the blog post, let's consider a use case where an e-commerce application is running on AWS Fargate which is producing clickstream data. Before we discuss how the data can be processed in batches and in real time, let's discuss how the data being produced can be consumed using AWS Serverless Services. This clickstream can be consumed by Amazon MSK Serverless. Clickstream data is unstructured and therefore enforcing a uniform schema can be difficult. We can use AWS Glue Schema Registry to enforce a uniform schema.
Clickstream data can be processed in batches and in real time. Therefore, the architecture diagram shows two flows as follows:
- Architecture for batch processing: AWS Lambda function consumes the messages off Kafka topics in batches which can then be pushed into an Amazon S3 bucket. Amazon S3 can be used as a data lake to store data from multiple sources. Schema validations can be done through AWS Glue Schema Registry. This will help to prevent downstream system failure because of schema metadata changes. This also helps enforce schema at the source before pushing it into the Kafka topic which results in schema validations happening before ingestion as well as during consumption. Amazon QuickSight can then consume the transformed and processed data from the Amazon S3 bucket. You can play with the data and pull useful insights like getting the number of devices and so on using Amazon QuickSight.
- Architecture for real-time processing: If data needs to be processed in near real-time, we can use Amazon Kinesis Data Analytics to consume messages from Amazon MSK Serverless in real-time. Schema validations are done through AWS Glue Schema Registry. This will help to prevent downstream system failure because of schema metadata changes. This also helps enforce schema at the source before pushing it into the Kafka topic which results in schema validations happening before ingestion as well as during consumption. Transformed data is then pushed to the Amazon OpenSearch service. You will be able to see the dashboard visualization generated based on the ingested data from the Kinesis Analytics application.
Conclusion
In this blog, we walked through an architecture that can be leveraged to build a serverless data pipeline for batch processing and real-time analysis. Please note that the architecture can change depending on the use case. Using AWS serverless services, we can build applications without having to worry about provisioning servers, scaling servers, and managing resource utilization while deriving useful insights that are beneficial for making business decisions.
Opinions expressed by DZone contributors are their own.
Comments