Attribute-Level Governance Using Apache Iceberg Tables
This article explains how data filter options in lake formation can be fruitful in managing fine-grained access leveraging Apache Iceberg tables.
Join the DZone community and get the full member experience.
Join For FreeLarge organizations where the number of users accessing crucial data is pretty high have to face a lot of challenges in managing fine-grained access.
A variety of AWS services like IAM, Lake Formation, and S3 ACL can help in fine-grained access control. But there are scenarios where a single entity containing the global data needs to be accessed by multiple user groups across the system with restrictive access. Also, organizations with a global presence might be working in different environments and with different toolsets, so data movement and cataloging become very tedious.
For example, a user wants to access the sales data from a table for analytics purposes, but he should be restricted to accessing only Australia region-related sales data. No other data should be visible to him. Also, he wants to access the data from a different cloud platform for multiple DML operations, so he needs to bring data and transform it into the tool’s native format for processing, which causes delays.
For this kind of scenario, we require data control at the attribute level and data across environments to support the native toolset formats and faster access.
We took a step ahead to address these challenges and deliver a cloud transformation solution leveraging Lake Formation for data governance on Apache Iceberg table, which can be queried and catalogued in AWS S3 itself and can be accessed across platforms and clouds.
Using the data filter option in Lake Formation, we can ensure column-level security, row-level security, and cell-level security.
What Is the Iceberg Table Format?
Iceberg is an open-source table format with the following benefits:
- Iceberg fully supports flexible SQL commands, making it possible to update, merge, and delete the data. Iceberg can be used to rewrite data files to enhance read performance and use delete deltas to quicken the pace of updates.
- Iceberg supports full schema evolution. Schema updates in Iceberg tables change only the metadata, leaving the data files themselves unaffected. Schema evolution changes include adds, drops, renaming, reordering, and type promotions.
- Data stored in a data lake or data mesh architecture is available to multiple independent applications across an organization simultaneously.
- Iceberg is designed for use with huge analytical data sets. It offers multiple features designed to increase querying speed and efficiency, including fast scan planning, pruning metadata files that aren’t needed, and the ability to filter out data files that don’t contain matching data.
Solution Overview
The solution we have proposed is using Lake Formation service to create data filters on which we can grant permissions to the user for access. The heart of the solution is using the Iceberg table format, which is catalogued and then added with filter conditions to govern access.
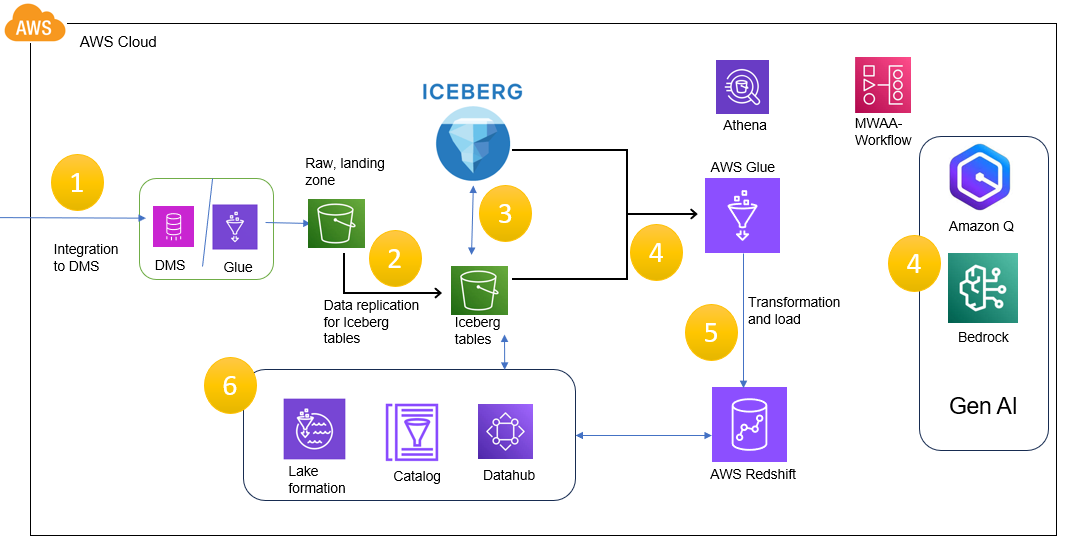
Data Flow
- DMS or Glue is used to fetch data from the source system repositories to store it in a designated S3 bucket.
- The event-based architecture triggers an event as S3 pushes to call the respective Lambda function to start the ETL process.
- Data will be stored in Iceberg table format and will be cataloged.
- Data can be processed and transformed using Glue, leveraging the GenAI readymade models.
- Processed data will be stored in Redshift for consumption.
- Cataloged Iceberg tables will be added with the tag column (tag value is mapped to the user group).
The image below describes a sample data filter and how it looks. We can also limit the number of columns using the data filters.
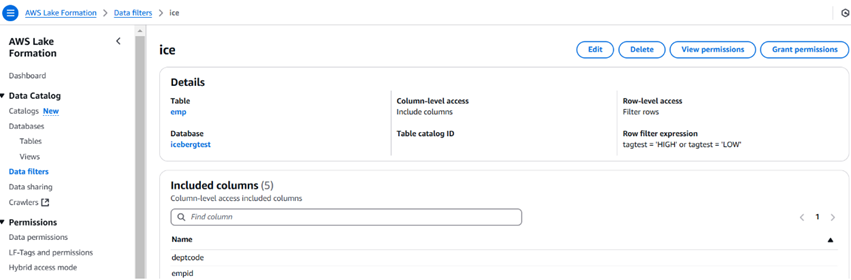
Once the filter is created, we can then use the grant permission option to give permission to users, roles, groups, and accounts. The user can use Athena to query the data.
The various capabilities of our solution are:
- Ability to effectively manage the fine-grained control of access to the data.
- Reusability of the data filters for multiple user groups.
- We can achieve column-level security, row-level security, and cell-level security.
- Effective use of Apache Iceberg table format features for seamless control over the data and its access.
- Efficiency and effectiveness in data preparation.
- Centralized access management and governance using lake formation.
- Less manual intervention in the fully integrated solution.
- End-to-end data delivery using cloud agnostic solution and serverless components to provide scalability and cost effectiveness.
Benefits
- Operational efficiency. The use of serverless components reduces the operational and maintenance overheads involved in managing it.
- Effort optimization. Up to 20-30% reduction in effort by using GenAI models to generate standardized and efficient ETL scripts.
- Governance and compliance benefits. Attribute-based control in lake formation helps to comply with the standard regulations and provide audit and logging capabilities.
Industrial Usage
Attribute-level governance using Apache Iceberg table can be very seamlessly implemented in the financial sector, like a bank or insurance company, where customers need to have restricted access to the data, ensuring authenticity and security of the data. The healthcare sector can use it to generate and share the patient's electronic health record in a fast manner, ensuring the sensitivity of data, which can lead to timely treatment and medication.
Conclusion
So, the overall solution will deliver attribute-level governance at scale with data preparation in a speedy manner using the Apache Iceberg table format needed for most organizations and implementing the solution leveraging Amazon Cloud services, which offers the benefit of quick wins, optimal cost, and unlimited scalability.
Opinions expressed by DZone contributors are their own.
Comments