Enterprise RAG in Amazon Bedrock: Introduction to KnowledgeBases
In this post, learn details of Amazon Bedrock KnowledgeBases capability and how to build a serverless RAG pipeline using KnowledgeBases.
Join the DZone community and get the full member experience.
Join For FreeAmazon Bedrock's KnowledgeBases is truly a serverless way to build a RAG pipeline rapidly, which allows the developer to connect almost all types of enterprise data sources including Jira or Confluence pages. This capability simplifies the process for developers looking to integrate document storage, chunking, retrieval, and analysis into their generative AI applications without spending much time writing code for document ingestion or deciding the chunking strategies, etc.
For instance, if a developer has a large set of customer support documents stored in Amazon S3, they can designate this storage location as the source for Bedrock. From there, Bedrock automatically manages the entire ingestion and retrieval workflow: it fetches documents from S3, splits them into manageable chunks, creates vector embeddings, and stores these in a chosen vector database. This architecture orchestrates the efficient retrieval of relevant information when a user query is submitted and the whole process is serverless.
When a user asks a question, Bedrock generates an embedding for the query, searches the vector database for related document chunks, and then feeds this information to a foundation model to formulate a response. This process enables applications, like an AI-powered support bot, to retrieve precise answers quickly from extensive document collections as well providing the citation to support the response for users to validate.
Bedrock supports multiple vector database options, such as:
- Amazon OpenSearch Serverless (with vector engine): Offers scalable, serverless search capabilities with vector support; ideal for retrieving relevant results from large datasets
- Pinecone: Known for fast and highly efficient similarity search; suitable for real-time applications
- Amazon Aurora: Combines traditional relational database features with vector capabilities; useful when additional structured data retrieval is required
- Redis Enterprise Cloud: Optimized for quick data access, this option works well when data needs to be frequently updated or accessed rapidly.
In practice, a company might use Amazon Bedrock to build an AI-driven knowledge assistant that accesses the latest product documentation, FAQs, and troubleshooting guides. The way the Bedrock AI platform works is by simply updating the data source which can be an S3 bucket with new documents. It automatically syncs the corresponding embeddings, which ensures the assistant always provides current information without requiring manual reprocessing if there is a change in the data source content.
In the following section, we’ll walk you through setting up your own RAG solution using KnowledgeBases for Amazon Bedrock — in just 10 minutes! Let’s dive in!
Setting Up Your Own RAG Solution Using KnowledgeBases
Step 1
Log in to the AWS console and launch the S3 service to create a bucket with a unique name and default configuration.
Step 2
Upload the document to the S3 bucket. We are going to use the PDF copy of the AWS documentation from this link as a sample. You can use your own document to test KnowledgeBases.

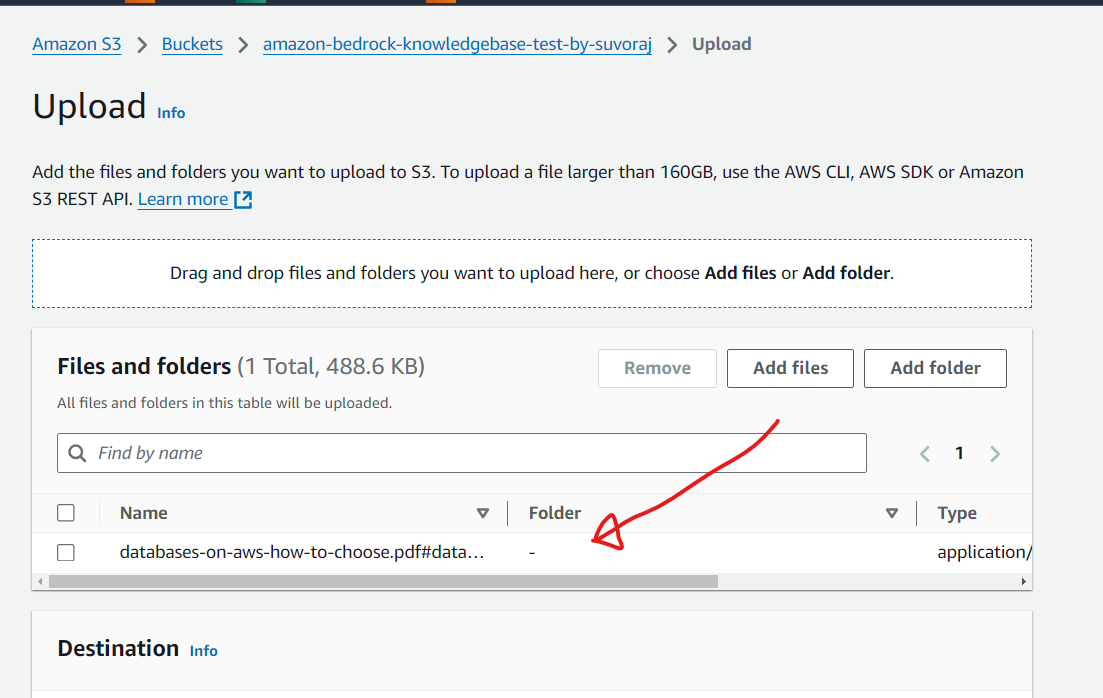
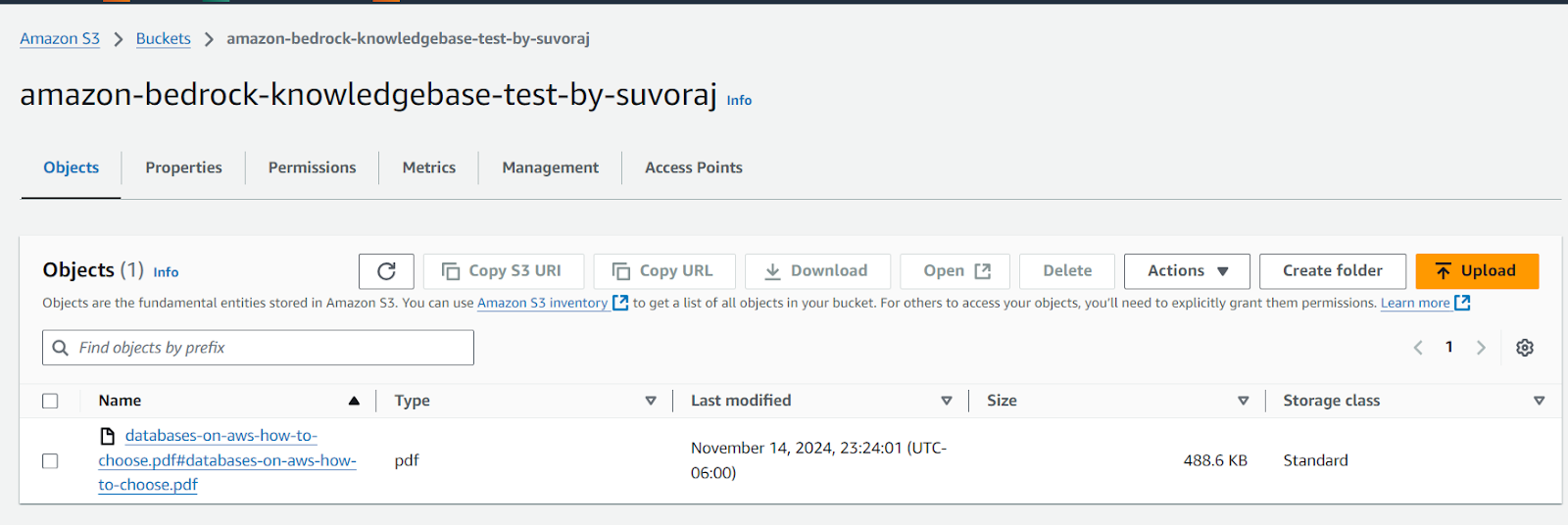
Step 3
Now we will navigate to the Amazon Bedrock console by searching "bedrock" in the same search bar above (remember using IAM user as the knowledge base can not be created in the root account). Once the Bedrock console opens, we’ll click the “Knowledge Base” link in the left panel.
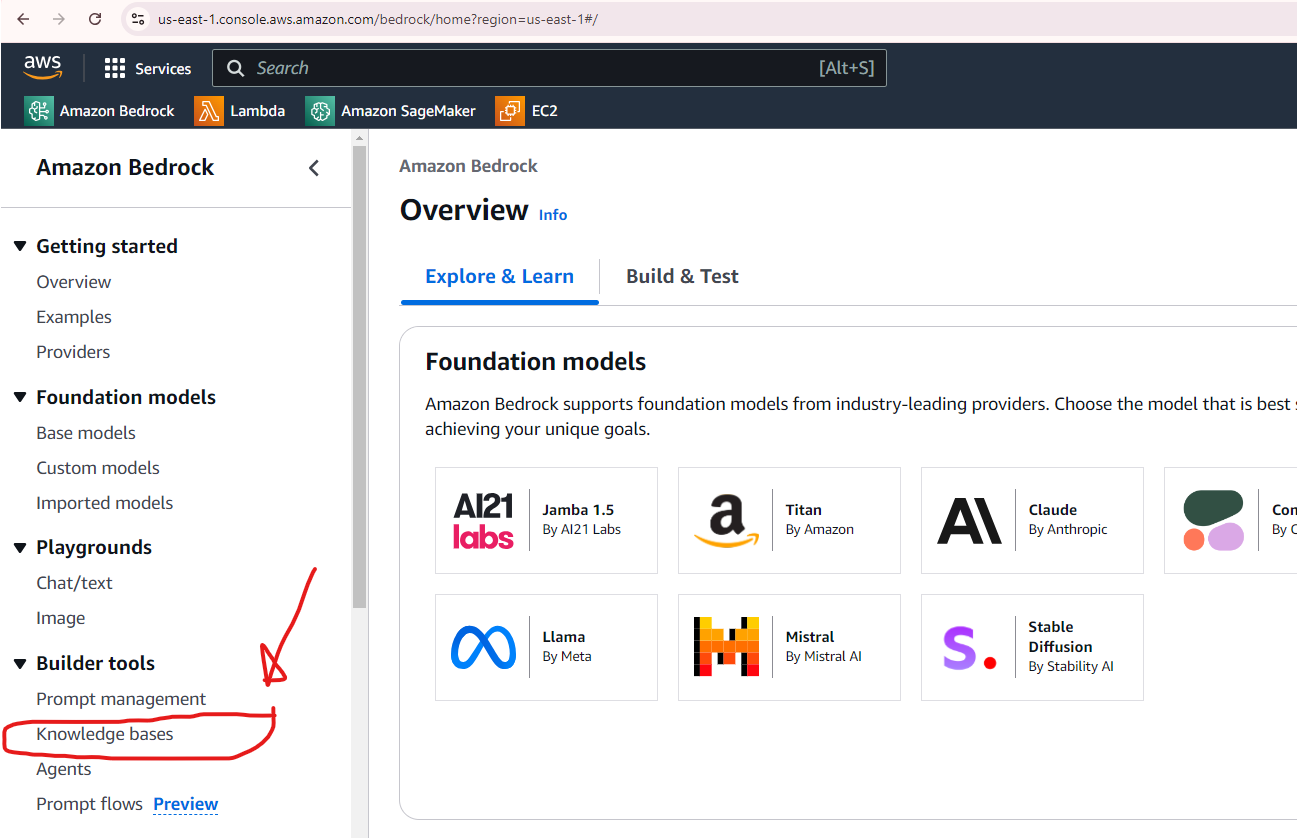
Click “Create Knowledge Base” once the page opens.

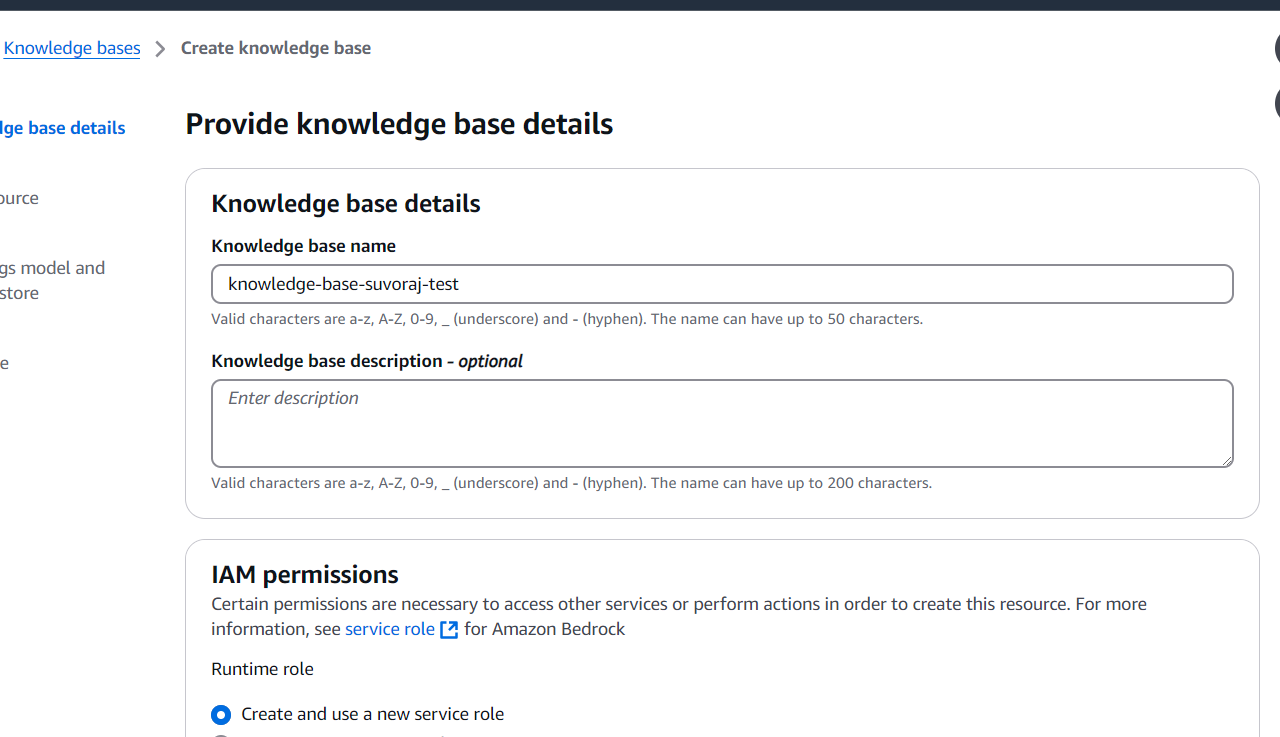
Step 4
Begin by providing details for the knowledge base, including its name, IAM permissions, and tags. Assign a user-friendly name to easily identify the knowledge base, and keep the remaining settings at their default values. Once completed, click the Next button at the bottom of the page to proceed.
Select “S3” as data source:
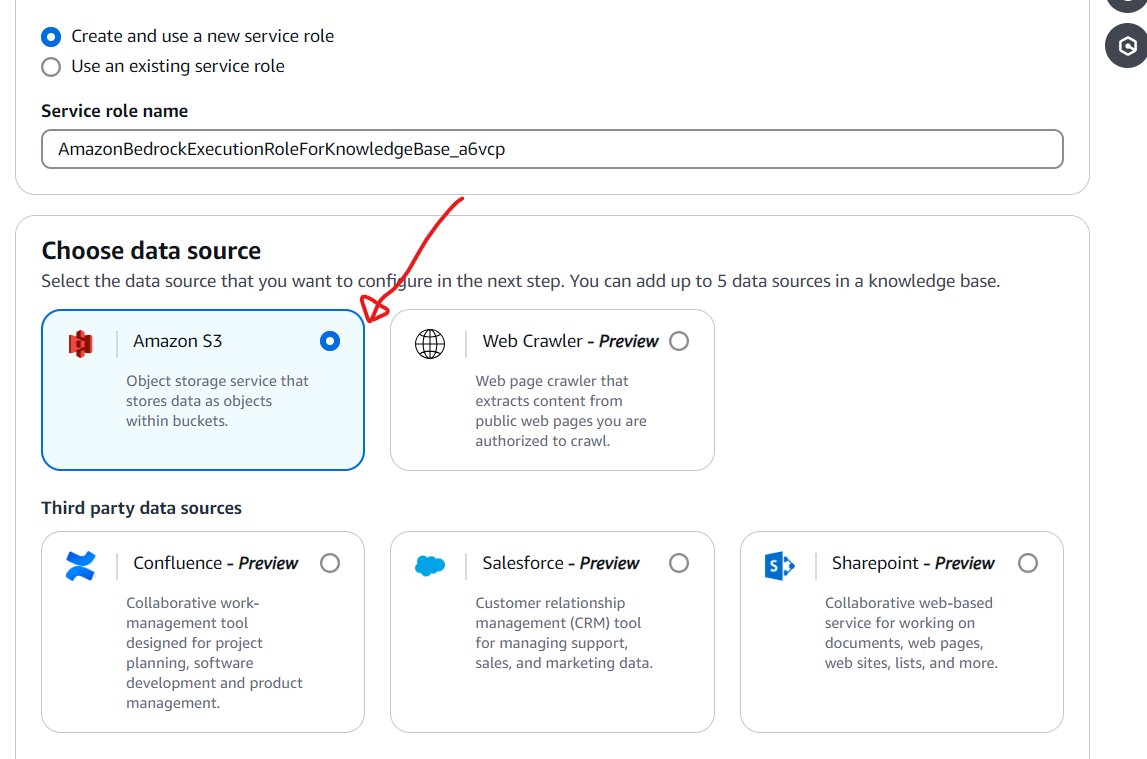
Step 5
Next, configure the data source by entering a descriptive name or select the default one and specify the URI for the S3 bucket created earlier. Once the information is complete, click the Next button at the bottom of the page to continue.
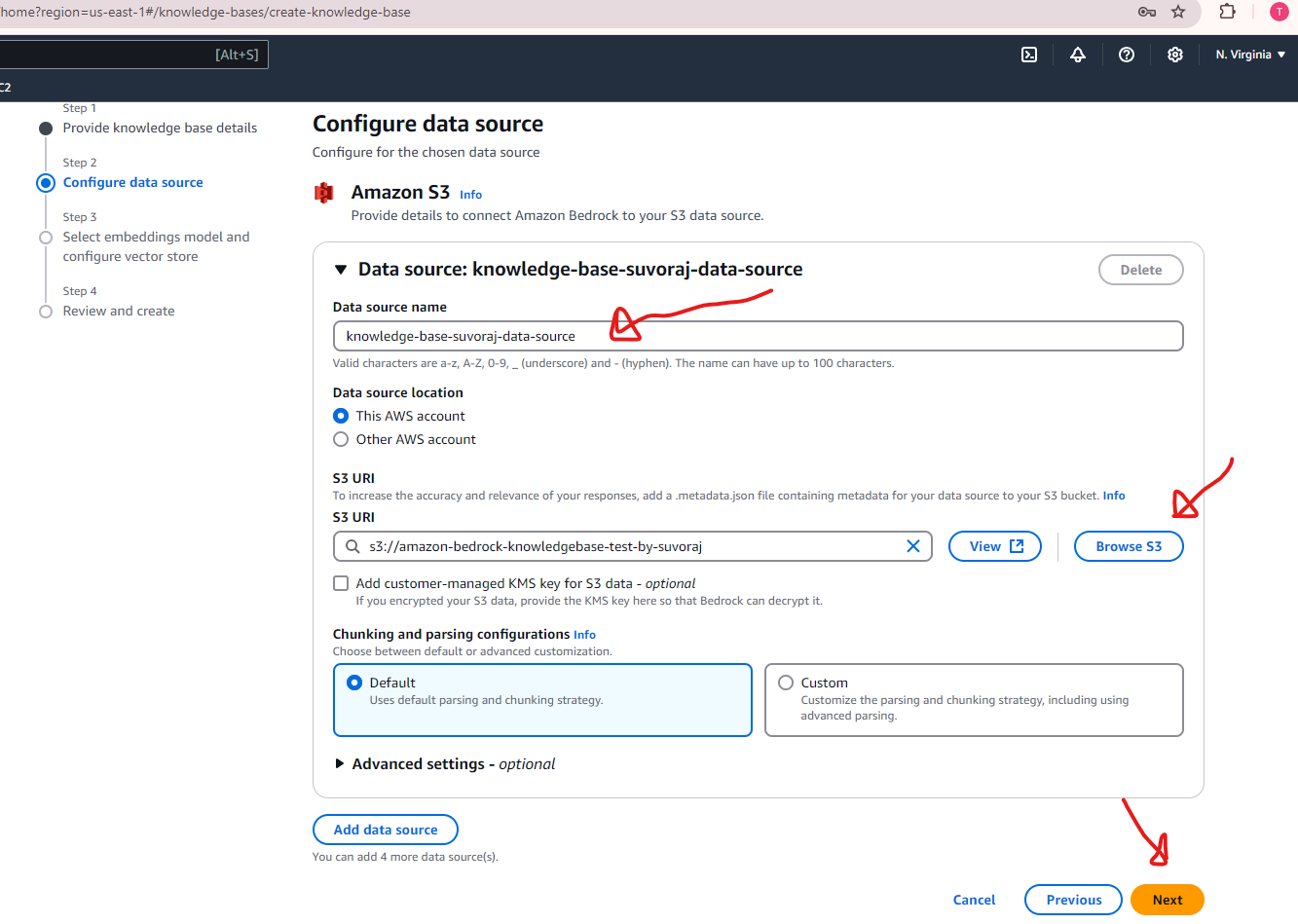
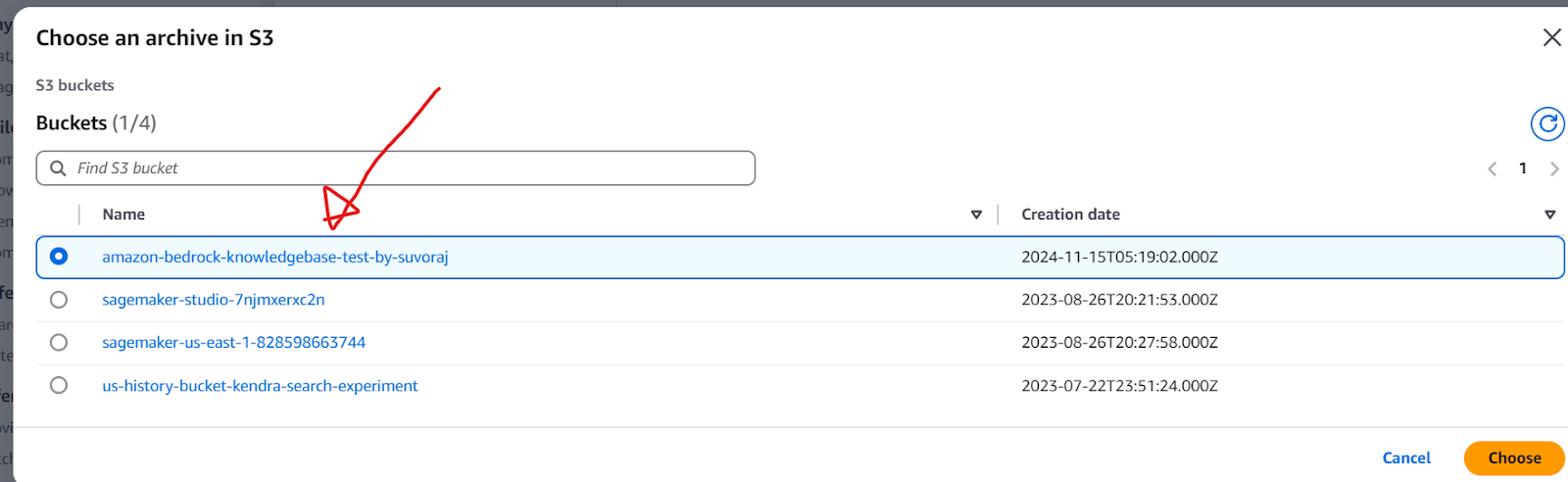
Step 6
Next, we’ll configure the embedding model and vector database. For this test scenario, we’ll select Titan Embeddings G1 - Text v1.2 as the embedding model, and choose the option Quick create a new vector store for the vector database. If you already have an existing vector database you’d prefer to use, you can specify that instead. For simplicity, we’ll proceed with creating a new vector store and leave all other settings at their default values. Once configured, click the Next button at the bottom of the page to continue.

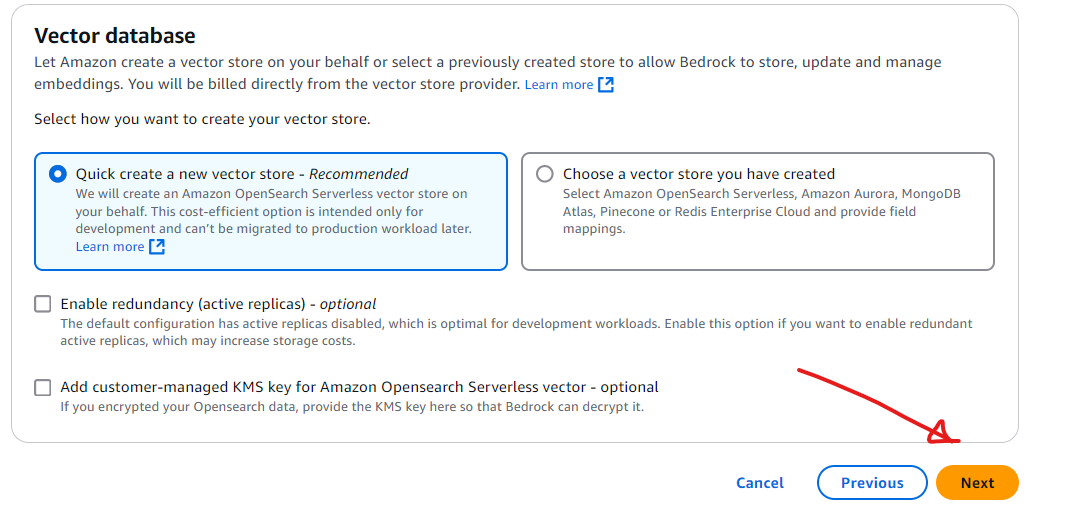
Step 7
In the final step, we need to review the details to ensure everything is accurate. Once confirmed, click the Create Knowledge Base button at the bottom of the page. The process may take a few minutes as Amazon OpenSearch Serverless sets up the vector database. During this time, a banner will appear at the top of the page, indicating that the vector database is being prepared.
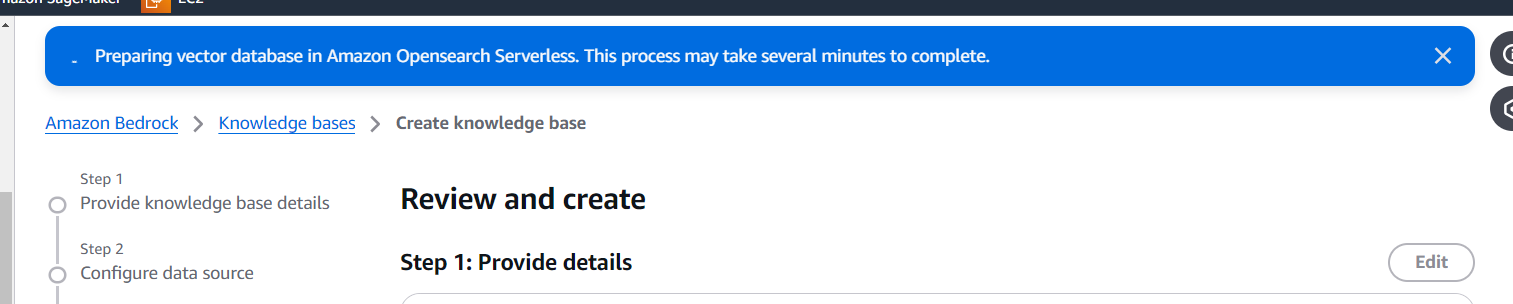
Once the vector database is instantiated and the knowledge base is created, a green banner will appear indicating that the process is successful and you will be automatically redirected to the knowledge base page.
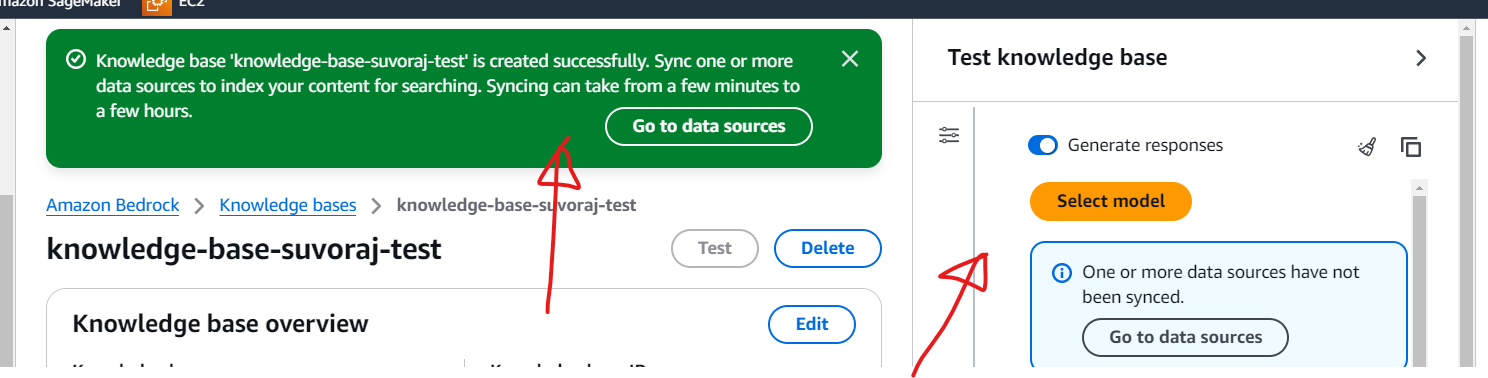
Step 8
The next step involves syncing the data source. Navigate to the Data Source section and click the Sync button. The synchronization process may take a few minutes, depending on the size of your documents. Once the sync is complete, a green banner will appear and the status column will update to display Available, indicating that the data source is successfully synced.
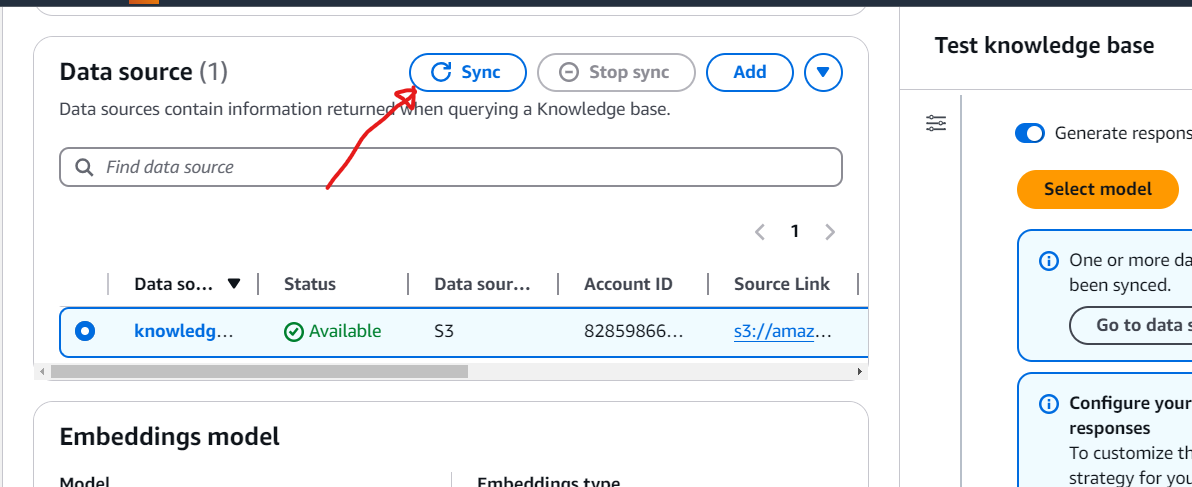

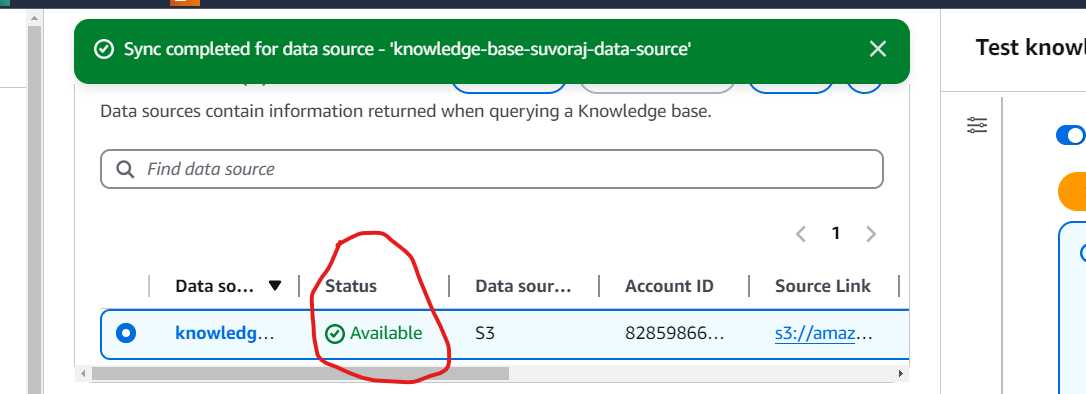
Step 9
Now we will test the knowledge base from the right side panel. Click “Select Model” to select the LLM to use:

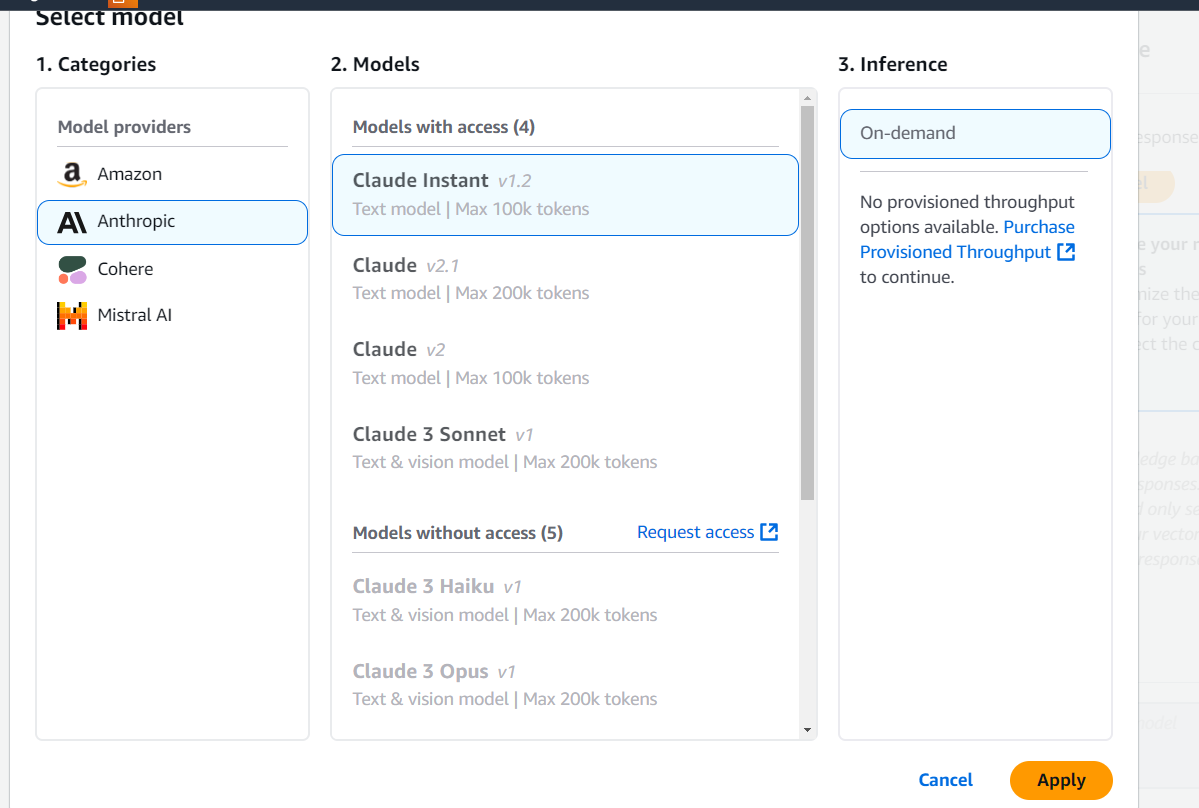
Step 10
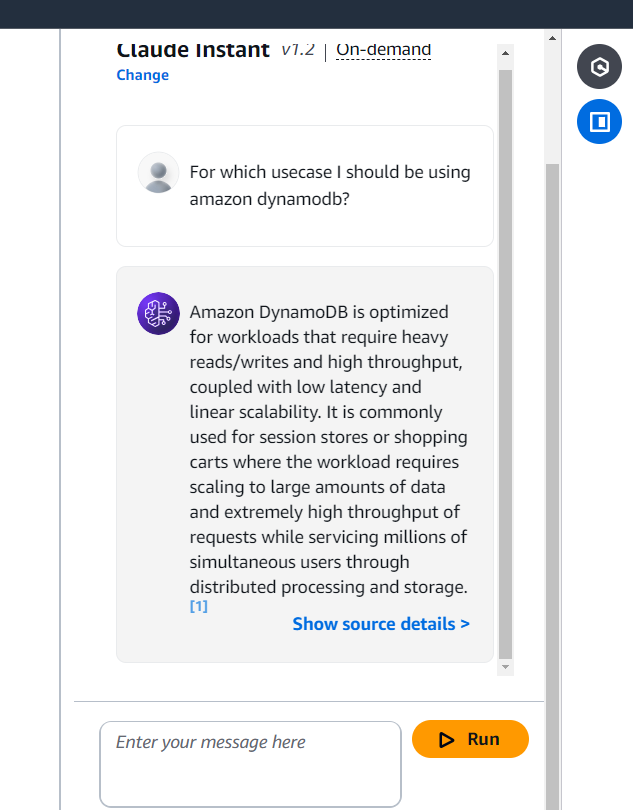
Now it’s time to test the setup. Enter your message or question in the input field and click the Run button. Your query will be processed by the knowledge base you created, leveraging Amazon Bedrock to run the RAG model behind the scenes and generate a response. Below is a screenshot showcasing an example question and its corresponding response, generated using the uploaded source data.
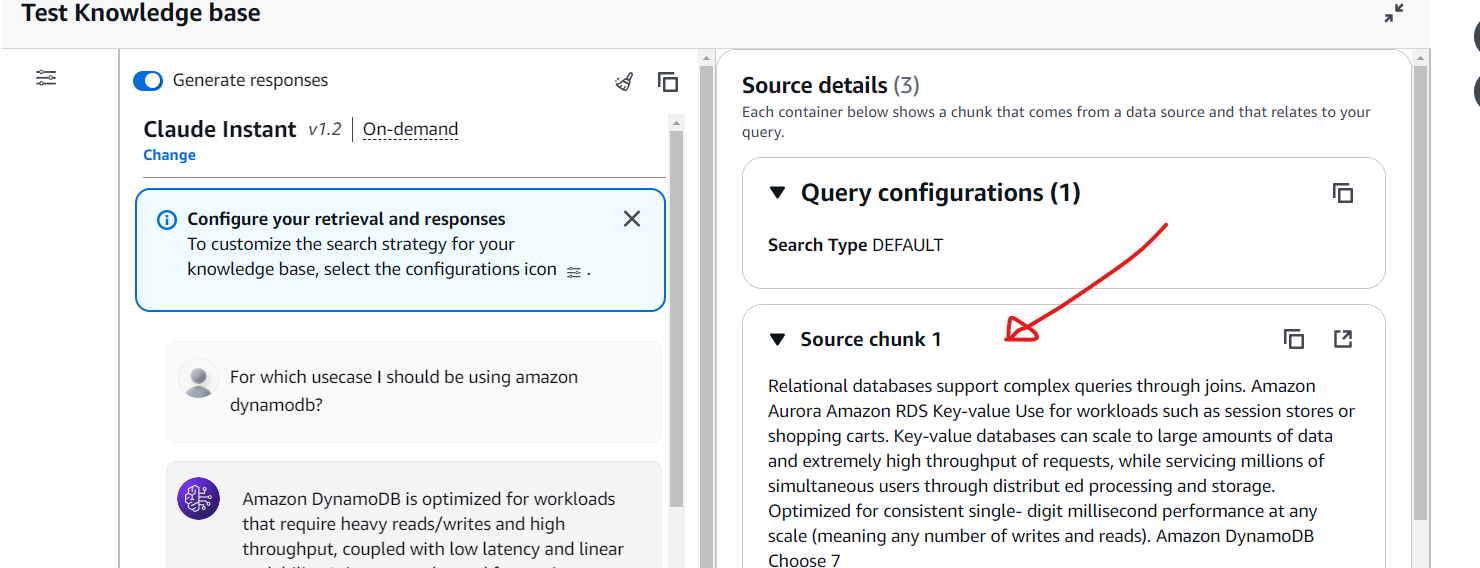
Also, you can review the specific documents Amazon Bedrock referenced to generate the response. Simply click on Show Source Details to view the details of the source materials used.
Congratulations on successfully building a RAG solution with KnowledgeBases on Amazon Bedrock!
Next Steps
As a next step, remember to clean up the vector database and the knowledge base if they are no longer needed to avoid incurring unnecessary costs.
Since we used OpenSearch as the default vector database, we will open the OpenSearch console to delete the collections created.
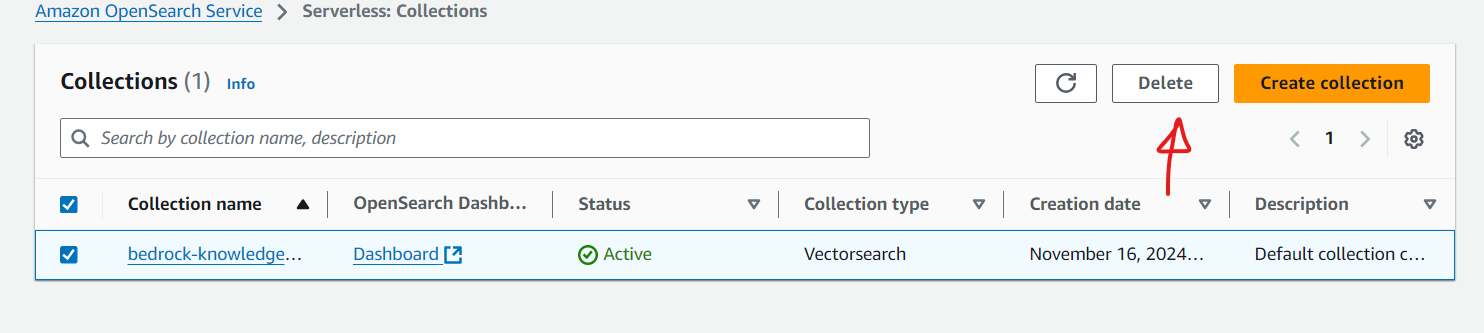
Verify the index name is matching with the index name as shown in the knowledge base configuration before deleting.
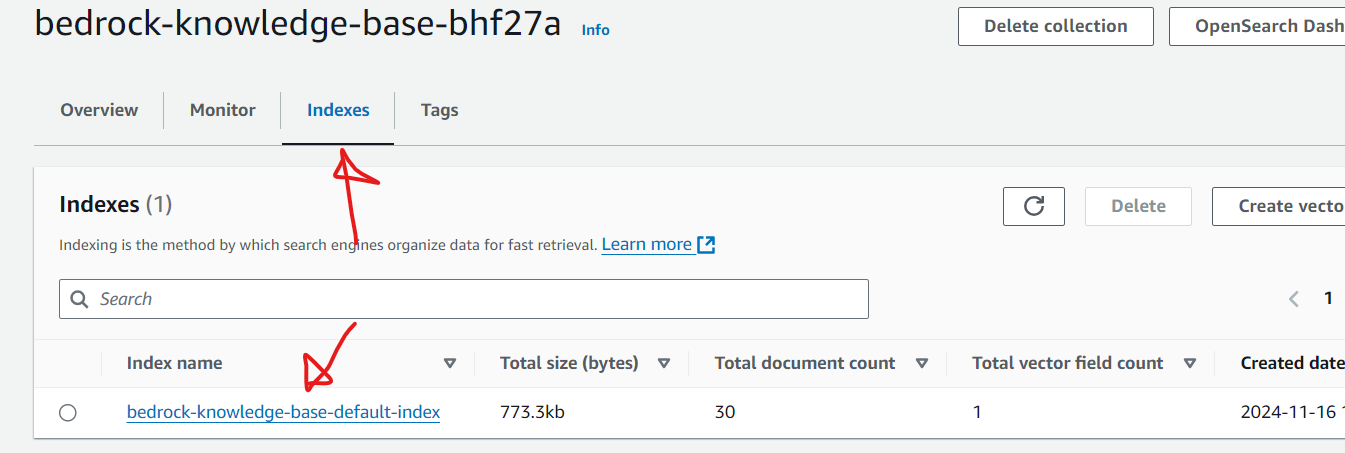
Don’t forget to delete the knowledge base once the underlying OpenSearch vector service is deleted. Follow the AWS documentation on how to delete an Amazon Bedrock knowledge base.

Opinions expressed by DZone contributors are their own.
Comments