Autoloader to Keep Delta Lake Hot With Data
This article will help you get started with the Autoloader feature and save on implementing a file-based notification framework.
Join the DZone community and get the full member experience.
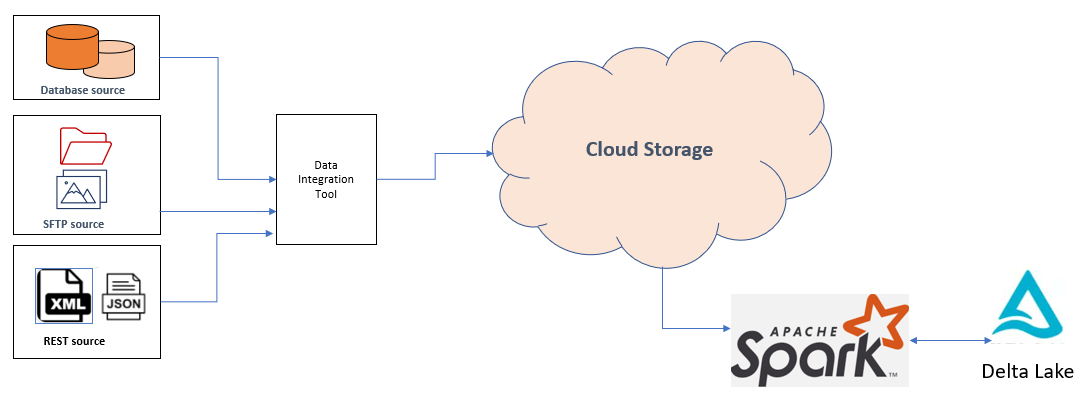
Join For FreeWhile working on batch ingestion use cases on Data Lake, we mainly deal with files for updates. While designing native Cloud-based data platforms and leveraging available frameworks, there is always a concern about reducing the laborious efforts of implementing file-based frameworks and notification mechanisms. Implementing own custom frameworks for file life cycle would be 'reinventing the wheel' with a high risk for failure when there has been native integration between Cloud native storages - S3, ADLS, and PaaS-based Data services - Databricks to provide a complete solution.
I encountered a similar decision-making process and saw that file-based ingestion was streamlined. The analytics delta lake layer was kept hot with incoming data updates with Databricks Autoloader. Autoloader has flawless integration between Azure ADLS, AWS S3, and Spark, Delta lake format on Azure, and AWS platforms with a native cloud file-based notification mechanism.
Native Cloud Support
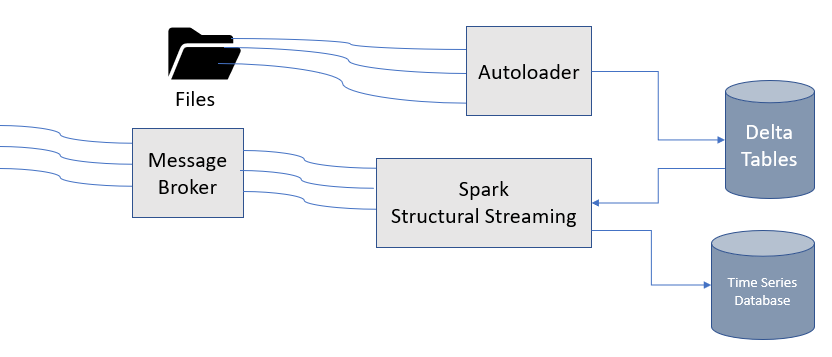
Autoloader uses Cloud Storage file upload notifications using subscription. Autoloader uses Spark Structural Streaming framework to create streams for newly uploaded blob files.
The below code will subscribe for notifications for file/blob upload, and Spark data frame will get updated with new blob file data. Notification Azure Storage Queues, AWS SQS will be created on the fly when we pass the option - "cloudFiles.useNotifications" as "True."
Azure Storage Queues are created on the fly with prefix - data bricks-query-*source. A Storage queue is created for each "source_path" to be synced with the Delta Lake table as the destination. This approach is better than using a system queue for Storage Account as multi-source path data can be synced with Delta Lake tables. This approach avoids notification message clashes when source paths can be updated independently of each other.
options = { "cloudFiles.subscriptionId" : 'XXXXXX',
"cloudFiles.format": "json",
"cloudFiles.tenantId" : 'XXXXX',
"cloudFiles.clientId" : 'XXXXX',
"cloudFiles.clientSecret" : 'X',
"cloudFiles.resourceGroup" : 'RG',
"cloudFiles.useNotifications": "True"}
schemaConf ={
"cloudFiles.inferColumnTypes": "True",
"cloudFiles.schemaEvolutionMode": "addNewColumns",
"cloudFiles.schemaLocation": "/path"}
df = (spark.readStream.format('cloudFiles') \
.options(**options) \
.options(**schemaConf) \
.load(source_path))Data Transformation on Streams
Data transformations can be applied to blob file sources to apply to masking and encryption. This will ensure that sensitive data fields are masked or encrypted in Delta lake tables and not exposed as plain text. UDF can transform plain text data fields into masked, encrypted data fields while dropping sensitive data fields in the data frame.
df.withColumn("masked_*", udf_mask(df.sensitive_col))
Incoming stream data can be enriched with master data or aggregated to provide quick refreshes to KPIs. Transformed data can be written to Delta Lake Table or Storage path. Merge query keeps the Delta table updated for existing records or inserts newly arrived records for new business keys. This feature can be helpful for slowly changing master data. Once merged, updates are quickly available for reads due to ACID compliance of Delta tables. The autoloader can be launched a few times per day for batch updates with a trigger option - "once" as "True" or can be continuously running streaming application. The batch option is more suitable for file source updates and would save costs in running spark notebooks.
def merge(df, batch_id):
merge_condition = " AND ".join([f"existing.{col} = updates.{col}" for col in key_columns])
if (DeltaTable.isDeltaTable(spark, delta_lake_path)):
delta_table = DeltaTable.forPath(spark, delta_lake_path)
delta_table.alias("existing").merge(source=df.alias("updates"), \
condition= merge_condition).whenMatchedUpdateAll().whenNotMatchedInsertAll().execute()
else:
df.write.format('delta').save(delta_lake_path)
query = df.writeStream.foreachBatch(merge).trigger(once = True) \
.option("checkpointLocation", checkpoint_path) \
.start()Delta Lake Tables
Databricks maintains history for every Delta table with regards to updates, merges, and inserts. Delta table data can be transformed further based on the use case using standard, popular ANSI SQL on Spark SQL.
Use Case Suitability
Autoloader file-based batch or streaming updates to the Delta Lake table can be used to enrich incoming continuous streaming data. This will ensure that changes in master data are absorbed by stream processing and would better handle late arriving master data problems. Autoloader and spark structural streaming handle both streaming and file dataset as streams and reduces the need for more complex Lambda architecture.
Recommendations and Limitations
- Autoloader can also work for Azure Synapse Analytics as a destination, but merge query is not possible with Synapse as a destination.
- Autoloader supports Databricks Delta Live tables[DLT] to create Delta tables from CSV and parquet datasets with SQL and Python syntax.
- Databricks Autoloader is best suited for loading files from ADLS or S3. Autoloader chooses the File notification approach over the Directory listing approach, thus reducing API calls needed to poll the changes in the storage directory.
- With Autoloader, files in the source storage path will be kept as-is and not be moved into the archive path. This would ensure the files arriving from the source as kept as-is and available for validation in case of any issue and reduces complexity in validating multiple directory paths.
- Files from the source path can be deleted, and Autoloader would not complain about the setting.
- In-build and proven frameworks reduce the risk of failure. No need to create a new file-based framework to keep track of processed and un-processed files. This would reduce development costs and help data engineers focus on building business logic.
- Autoloader can be used in conjunction with Azure Data Factory[ADF] or Stitch Data[Stitch], Qlik, and Streamsets which have built-in connectors for a wide range of data sources. Data can be ingested into ADLS or S3 in form of files by leveraging data ingestion tools.
- Autoloader promises exactly-once data ingestion guarantee and hence would make developers' life easier in making sure no duplicate records are inserted.
- Best suited for Delta Lake-centered Data Lake.
- Autoloader uses RocksDB to keep track of files processed by the framework. This dependency is internally managed by Autoloader.
- Though RocksDB is used to keep track of files, it is not possible to query RocksDB through a programmable API to get a list of all files. All operations to RocksDB are done internally and not exposed to end users. Opening read operations for developers might help.
- Autoloader works for S3 and ADLS storage and for Databricks hosted on Azure and AWS.
Autoloader makes the internal movement of data easy, just like short distance mover - Fork Lifts on an industrial floor. The autoloader can make Fork Lift job kids play as data engineers would not worry much about data movements within the data platform. This is a metaphor and intends to convey the simplicity of the framework and utility as must action in getting data for further processing. Power of Cloud-native services is effectively used to provide end-to-end data solutions with cloud-based, hosted Data Ingestion tools, Autoloader, Delta Lakes, and Cloud-based DWH; Cloud-based BI tools.
Opinions expressed by DZone contributors are their own.
Comments