Handling Dynamic Data Using Schema Evolution in Delta
This article is intended to help data practitioners learn an effective way of dealing with dynamically changing data through Delta Lake.
Join the DZone community and get the full member experience.
Join For FreeOne of the biggest challenges of managing data nowadays is its constantly changing nature. We recently came across a requirement to ingest survey data and send it for sentimental analysis. The survey data is very dynamic, and even for existing surveys, new questions will be added, modified, or deleted.
As the data source evolves and adapts to new changes, the challenge is how to deal with the dynamically changing data to be represented in a table format. We implemented this by leveraging the schema evolution feature in Delta tables.
Why Delta Lake?
Delta Lake (or Delta Table) is designed to bring reliability and robustness to data lakes. Delta Lake is an open-source table format that supports ACID transactions, scalable metadata handling, enhanced data reliability, faster query performance, and seamless integration with Spark.
Delta Lake also supports schema evolution. In data management, the ability to change the structure of data over time is a common requirement, known as schema evolution.
Source Data and Ingestion
The source data is semi-structured data, and in this case, we receive the file in text format. Usually, these kinds of data are available in XML or JSON file formats. The first step is to read the data from the source and flatten it accordingly to the data governance standards.
In this example, we receive source data in four batches, and each batch will be ingested in the Delta table one after the other. The Delta table is created initially with this structure.
CREATE TABLE IF NOT EXISTS surveydb.CampaignTable
(
CustomerID STRING
,Tier STRING
,CampaignQn1 STRING
)
USING DELTA
LOCATION '/mnt/blobname/DeltaLake/CampaignTable'This is the Pyspark code that is used to load the incoming Dataframe to the Delta table, and this is executed for every batch. Delta does not allow us to append data with mismatched schema by default, and this feature is known as schema enforcement. So, we do an empty Dataframe append with schema merge and then do the regular merge.
from delta.tables import DeltaTable
MergeColumns=[Col for Col in SourceDF.columns]
SourceDF.limit(0).write.format("delta") \
.mode("append") \
.option("mergeSchema",True) \
.save(TargetPath)
DeltaTable.forPath(spark,TargetPath).alias("TGT") \
.merge(SourceDF.alias("STG")
,f"TGT.CustomerID=STG.CustomerID") \
.whenNotMatchedInsert(values={Col:f"STG.{Col}" for Col in MergeColumns}) \
.execute()Schema Evolution in Every Batch
Let’s examine the source data and the Delta table structure after the execution of each batch. In the initial batch, the data is received in the same structure as the table, but that is not mandatory in this approach.
Batch 1
Source data for the initial batch.
|
CustomerID |
Tier |
CampaignQn1 |
|
1001 |
Tier2 |
Q1_1001 |

Batch 2
In the second batch, a new column is added to the source data. The write command with the mergeSchema option and limit(0) will only append schema, so the new column CampaignQn2 is automatically added to the table.
The merge command that follows next will only insert specific columns available on the list. The MergeColumns list has only the columns available in the incoming Dataframe. In this way, the new column is created and loaded with data.
|
CustomerID |
Tier |
CampaignQn1 |
CampaignQn2 |
|
1003 |
Tierl |
Q1_1003 |
Q2_1003 |

Batch 3
Unlike the previous batches, here, the incoming data have CampaignQn1 column missing. Even though the mergeSchema runs, there is no schema change, then the merge command with MergeColumns list inserts only the columns available in the source Dataframe.
|
CustomerID |
Tier |
CampaignQn2 |
|
1005 |
Tier1 |
Q2_1005 |
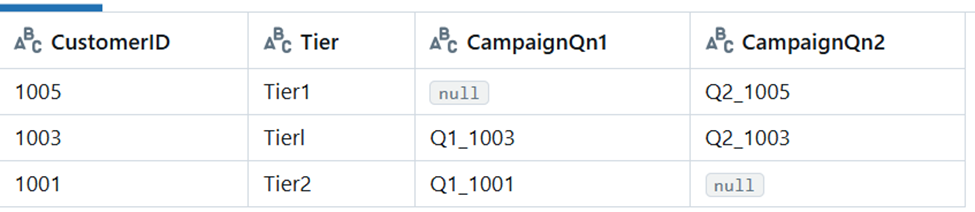
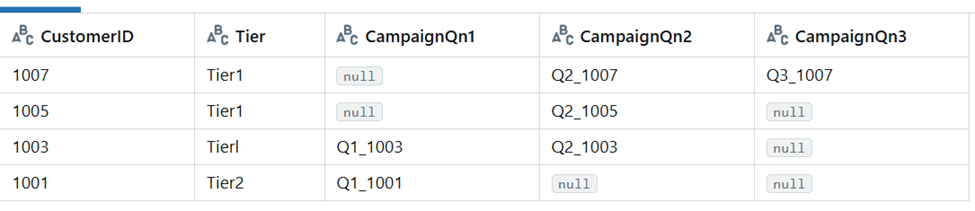
Batch 4
Here, the column positions are shuffled, and there is a new column, CampaignQn3. The mergeSchema makes an empty Dataframe and appends with schema merge, and that creates the new column.
The column position change is handled by naming the columns during merge using the MergeColumns list. In this way, the data is appended in the correct columns in the Delta table.
|
CustomerID |
Tier |
CampaignQn3 |
CampaignQn2 |
|
1007 |
Tier1 |
Q3_1007 |
Q2_1007 |
This allows us to change the schema of the table without doing a full data rewrite. This feature offers a lot of flexibility, but we must use it carefully. In Delta, the delta log tracks all the schema and data changes. In addition to that, we can track the history of these changes by using the describe history command.
DESCRIBE HISTORY surveydb.CampaignTableDelta Lake allows us to add, change, or delete columns in a table without impacting data pipelines and thereby simplifies schema evolution. In addition to that, it tracks changes, making it easier to understand how the data has evolved over time. Schema enforcement and evolution in Delta help maintain data consistency and integrity by preventing errors, resulting in improved data quality and more efficient data governance.
Conclusion
The automatic schema evolution in Delta is a very useful feature when dealing with dynamic data sources and supports most complex scenarios. When data sources evolve, we can avoid the manual intervention of updating the table schema with a straightforward command that can be executed along with the load process. Schema evolution is especially useful when consuming multiple data sources with dynamically changing data.
Opinions expressed by DZone contributors are their own.
Comments