Automate Azure Databricks Unity Catalog Permissions at the Schema Level
Steps and scripts to apply permissions at the Unity Catalog schema level, reducing manual effort related to permissions at schema level.
Join the DZone community and get the full member experience.
Join For FreeDisclaimer: All the views and opinions expressed in the blog belong solely to the author and not necessarily to the author's employer or any other group or individual. This article is not a promotion for any cloud/data management platform. All the images and code snippets are publicly available on the Azure/Databricks website.
In this article, I will provide the script to automate permission management at the Unity Catalog schema level.
Privileges at the Unity Catalog Schema Level
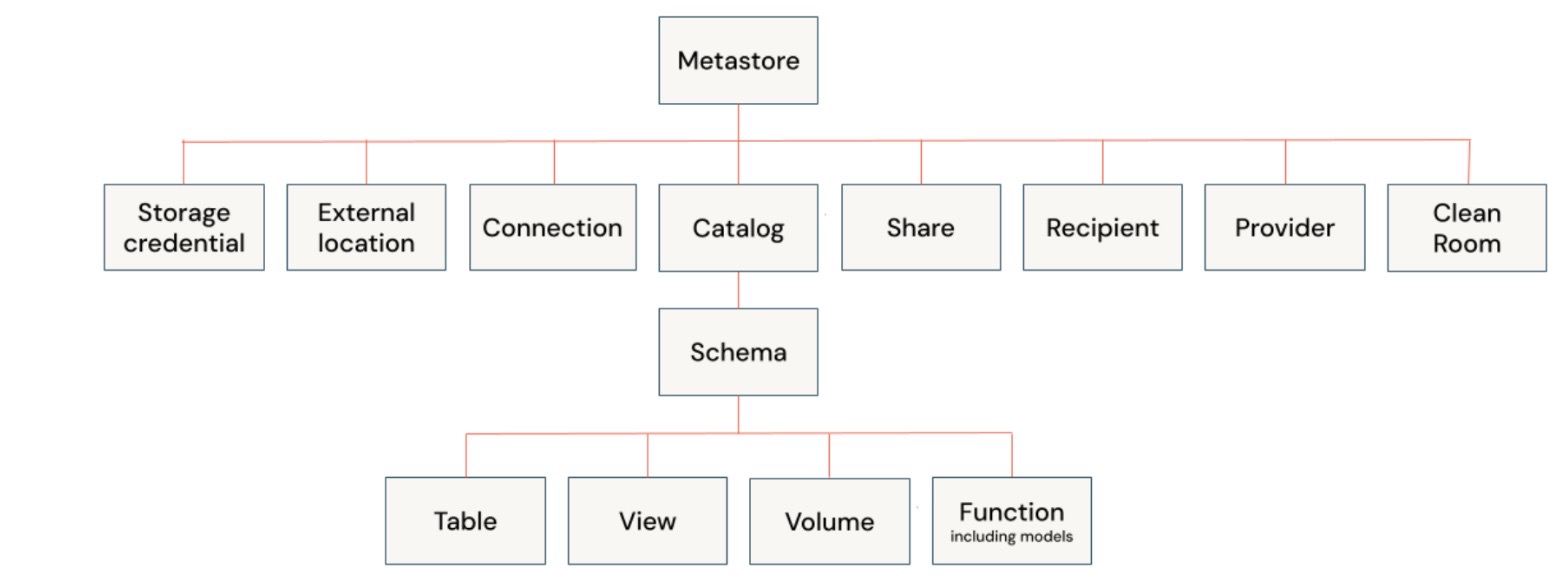
The hierarchal privilege model in Unity Catalog enables users to apply privileges at any level in the hierarchy, and the child object(s) inherit the same permissions automatically. So, if permission is applied at the schema level, it will automatically be applied to all tables, views, volumes, and functions inside the schema.
In Unity Catalog (Databricks), permissions at the schema level are applied when you want to control access to a set of tables and views within a specific schema. Schema-level permissions are typically applied in the following scenarios:
- Granting access to groups of objects: If you want to manage permissions for multiple tables and views collectively, it's efficient to apply permissions at the schema level rather than individually for each table or view. This allows you to control access to all objects within that schema simultaneously.
- Organizational control: When different teams or departments within an organization need access to specific datasets, which are stored under separate schemas. Applying schema-level permissions allows you to grant or restrict access to all objects relevant to a team within that schema.
- Consistent permission management: For environments where new objects (tables/views) are frequently added to a schema, setting permissions at the schema level ensures that new objects inherit the permissions automatically, reducing the need for manual permission updates.
- Maintaining data security: When you want to enforce access controls over a particular dataset category (e.g., finance data, HR data) that is logically organized under a schema. By setting permissions at the schema level, you maintain data security while simplifying administration.
Automation Script
Prerequisites
- Unity Catalog is already set up.
- Principal(s) is/are associated with the Databricks workspace.
- The user running the permission script has proper permissions on the schema and catalog.
Step1: Create a Notebook and Declare the Variables
Create a notebook in Databricks workspace. To create a notebook in your workspace, click the "+" New in the sidebar, then choose Notebook.
Copy and paste the code snippet below into the notebook cell and run the cell.
catalog = 'main' # Specify your catalog name
schema = 'default' # Specify your schema name
principals_arr = '' # Specify the Comma(,) seperated values for principals in the blank text section (e.g. groups, username)
principals = principals_arr.split(',')
privileges_arr = 'SELECT,APPLY TAG' # Specify the Comma(,) seperated values for priviledges in the blank text section (e.g. SELECT,APPLY TAG)
privileges = privileges_arr.split(',')Step 2: Set the Catalog and the Schema
Copy, paste, and run the code block below in a new or existing cell and run the cell.
query = f"USE CATALOG `{catalog}`" #Sets the Catalog
spark.sql(query) Step 3: Loop Through the Principals and Privileges and Apply Grant at the Catalog and the Schema
Copy, paste, and run the code block below in a new or existing cell, then run the cell to apply the permissions.
for principal in principals:
query = f"GRANT USE_CATALOG ON CATALOG `{catalog}` TO `{principal}`" # Apply use catalog permission at Catalog level
spark.sql(query)
query = f"USE SCHEMA `{schema}`" # Sets the schema
spark.sql(query)
query = f"GRANT USE_SCHEMA ON SCHEMA `{schema}` TO `{principal}`" # Apply use schema permission at Schema level
spark.sql(query)
for privilege in privileges:
query = f"GRANT `{privilege}` ON SCHEMA `{schema}` TO `{principal}`" # Use schema permission at Schema level
spark.sql(query) Validation
You can validate the privileges by opening Databricks UI and navigating to Catalog in the Data Explorer. Once the catalog shows up in the Data section, click on the catalog, then select the schema where you have applied the permissions and go to the Permissions tab. You can now see all the privileges applied to the schema.
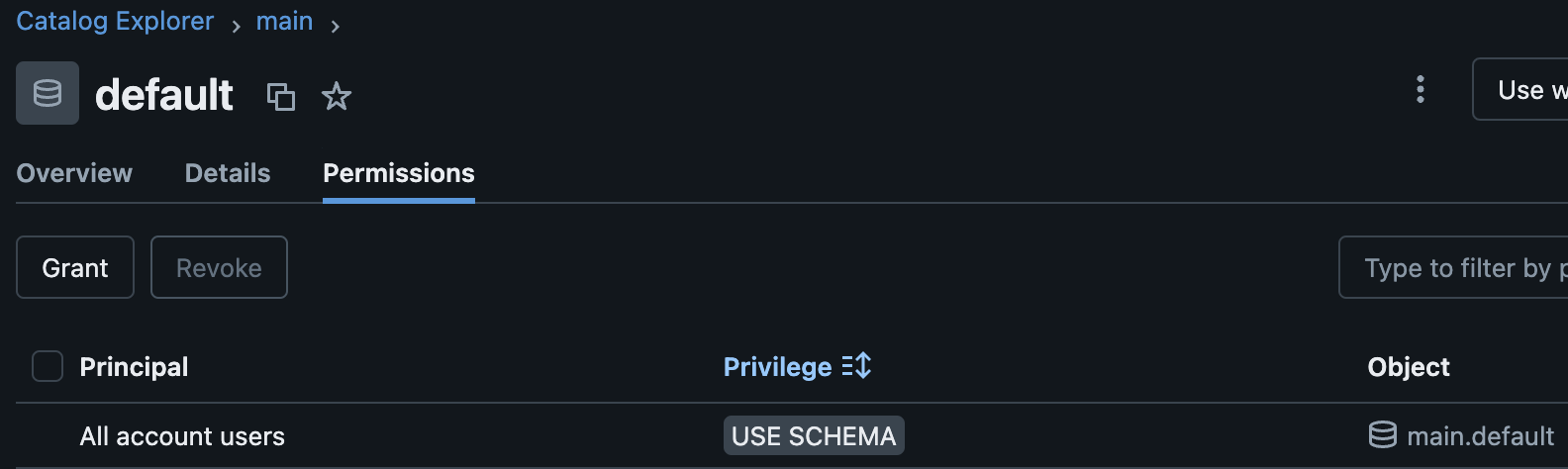
You can also run the SQL script below in a notebook to display all the permissions for a schema as part of your validation.
SHOW GRANTS ON SCHEMA my_schema; Conclusion
Automating privilege management in Databricks Unity Catalog at the schema level helps ensure consistent and efficient access control for the group of objects (e.g., tables, views, functions, and volumes) in the catalog. The code provided demonstrates a practical way to assign schema-level privileges, making it easier to manage permissions across principals (e.g., users and groups). This approach reduces the management tasks and the chance of manual errors by grouping tables and views inside a schema and applying consistent permissions for the entire schema.
Opinions expressed by DZone contributors are their own.
Comments