How to Identify Bottlenecks and Increase Copy Activity Throughput in Azure Data Factory
Learn how to optimize the throughput of a copy activity in Azure Data Factory by identifying bottlenecks, scaling integration runtimes, and more.
Join the DZone community and get the full member experience.
Join For FreeAzure Data Factory (ADF) is a cloud-native ETL tool to process data seamlessly across different sources and sinks.
Copy activity is mostly used to copy data from one source to another source. While copying data between two different sources, we need to make sure that the activity is completed in a timely manner to meet business needs and process data within the service level agreement.
Identifying Bottlenecks and Improving Throughput
There are two main things in ADF that will affect throughput performance. Those are compute using in-copy such as Azure Public or managed VNET Integration Runtime (IR), Self-Hosted Integration Runtime (SHIR), and the number of parallel copies. If the compute is not properly scaled for copy job size, it will result in slow performance when it is overutilized. As well as scaling parallel copies to achieve faster performance, this will require even more compute from the IR and from the sources involved. So, as we scale one option, we might need to scale other things as well.
When observing bad performance during copy activity execution, below are the most common causes.
SHIR Capacity Issue
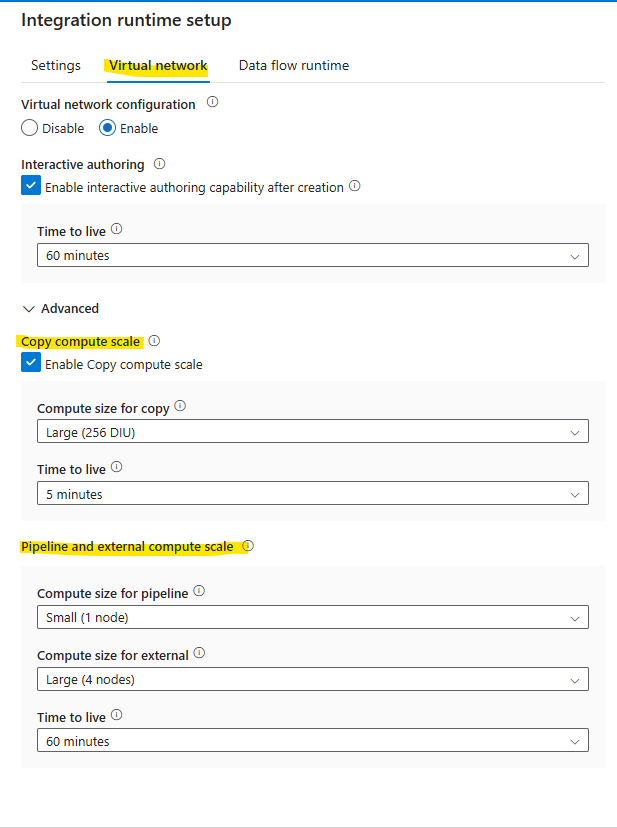
Check if SHIR is overutilized for resources like CPU, and memory during the copy run. This can be checked in the ADF Studio integration runtime monitoring tab. If it is overutilized (ideally usage threshold is 80%), then it needs to scale out or scale up to handle the job. This problem might have occurred due to recent changes in the execution of the number of pipelines in ADF or could be changed in the dataset size that is being copied as part of the job.
For Azure Public IR and Managed VNET IR, the resources are handled through Data Integration Units and Copy compute scale options, respectively.
Parallel Copies Not Enabled
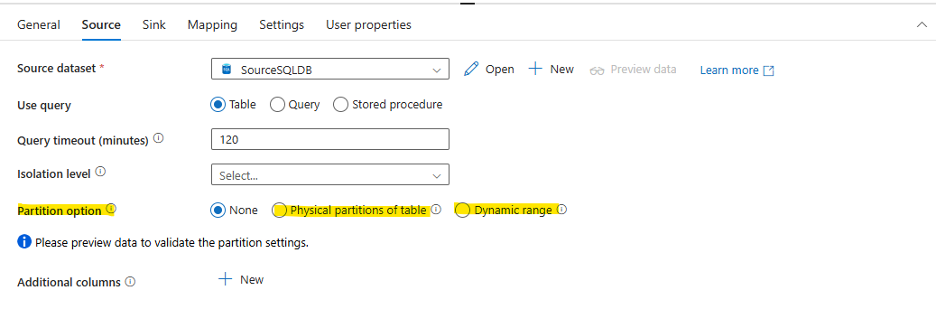
Check if the parallel copies have been enabled or not in the copy activity. If it is not enabled (by default), then it needs to enable this setting to achieve parallelism and increase throughput performance. By increasing the number of parallel copies, it will have more load on the Integration Runtime, the source, and the sink data stores. So, consider scaling up resources on these as well.
Also, when enabling this feature, we need to make sure the source dataset table has an optimal partition column to choose to split the data evenly within each parallel thread. This property also depends on which type of source it is, as some sources don’t support this property. For those scenarios, we need to implement the dynamic query and utilize the ForEach activity to increase parallelism. Refer to this document for more information on parallel copy.
Source/Sink Resource Utilization Issue
After scaling ADF IR resources and adjusting parallel settings, then we need to further scale source and sink data stores to handle the ADF requests and process them. Monitor the source/sink side resource utilization stats (CPU, memory, Input/Output operations) and scale out the resources accordingly.
Check the query option for the source data store, if applicable. If the copy is using a query on the source side to filter or transform the data before copying, make sure the query is efficient and optimized. The ADF monitor shows that it took a long time to read the data, so it is most likely an issue with the query or source data store resource scaling. When we run the same query outside of ADF using some other client tools and it also takes a long time, this is a query issue and a matter of optimizing the query to be more efficient.
Network Bandwidth and Latency
Check if there are any issues with bandwidth in Express Route when transferring data using SHIR from on-prem data sources. Make sure that the bandwidth is configured as per the data transfer needs. When using SHIR, make sure that this is close to the source data store and in the same local network path to avoid latencies. If the SHIR is running on Azure Virtual Machine (VM), then make sure that the VM is on higher network bandwidth and close to the region where the source data store is located to avoid latencies.
Conclusion
Optimizing the Integration Runtime resources, enabling parallelism, and scaling the source/sink system resources enable the copy activity can achieve better throughput in Azure Data Factory. Addressing these factors ensures that data is transferred more quickly and meets business needs within service-level agreements.
Opinions expressed by DZone contributors are their own.
Comments