AWS Bedrock vs. SageMaker: Choosing the Right GenAI Stack in 2026
Deciding between Bedrock's serverless ease and SageMaker's deep control? This guide breaks down the 2026 AWS GenAI landscape for you.
Join the DZone community and get the full member experience.
Join For FreeBy 2026, the landscape of Generative AI has shifted from simple prompt engineering to complex agentic workflows, autonomous RAG (Retrieval-Augmented Generation) pipelines, and highly specialized small language models (SLMs). For architects and developers building on Amazon Web Services (AWS), the central question remains: Should you use the managed simplicity of Amazon Bedrock or the granular control of Amazon SageMaker?
This article provides a deep-dive technical comparison of these two powerhouses, helping you navigate the trade-offs in performance, cost, and operational overhead.
The Evolution of the GenAI Stack
In the early 2020s, the choice was binary: Bedrock for APIs, SageMaker for training. In 2026, the lines have blurred. Bedrock now supports advanced fine-tuning and complex orchestration, while SageMaker has introduced JumpStart features that rival the ease of managed services. However, the fundamental architectural philosophy of each service remains distinct.
Amazon Bedrock: The Serverless Powerhouse
Bedrock is designed as a serverless abstraction layer. It provides access to Foundation Models (FMs) from leading providers (Anthropic, Meta, Mistral, and Amazon’s own Titan/Olympus series) via a unified API. In 2026, Bedrock’s value proposition centers on Agents, Knowledge Bases, and Guardrails.
Amazon SageMaker: The Full-Spectrum Workbench
SageMaker is the industrial-grade environment for the entire machine learning lifecycle. It is the destination for organizations building proprietary models from scratch, performing massive-scale distributed training (via SageMaker HyperPod), or requiring specialized inference hardware (like AWS Inferentia3).
Architectural Deep Dive
1. The Bedrock Workflow: Managed Orchestration
Bedrock’s architecture is built around the concept of a "GenAI Application Stack" where the heavy lifting of infrastructure is hidden. Developers interact with high-level constructs.
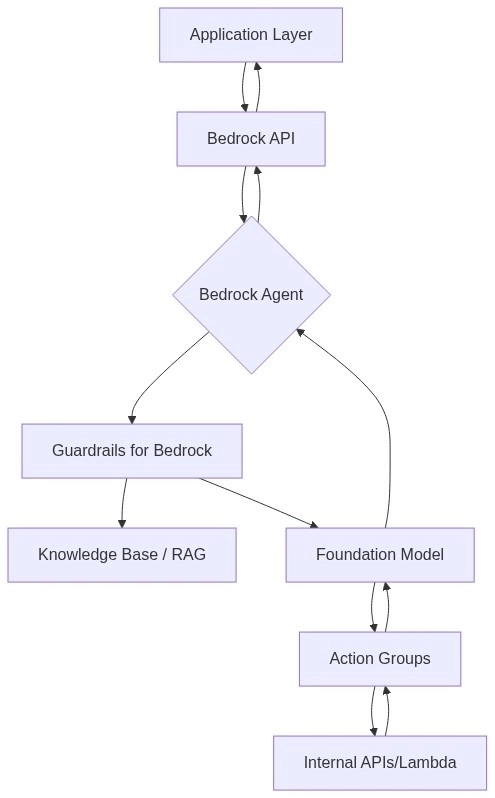
In this architecture, the Bedrock Agent acts as the reasoning engine. It uses a "ReAct" (Reason + Act) prompting framework internally to break down user requests, query a Knowledge Base (vector store) for context, and trigger Action Groups (AWS Lambda functions) to perform tasks.
2. The SageMaker Workflow: Infrastructure Control
SageMaker provides a lower-level abstraction where you manage the container, the instance type, and the scaling logic. This is critical for 2026-era "Model Distillation" and "RLHF" (Reinforcement Learning from Human Feedback) workflows.

SageMaker HyperPod, a key feature in 2026, allows for resilient, multi-node training across thousands of accelerators, automatically repairing hardware failures to ensure long-running training jobs for trillion-parameter models don't crash.
Feature Comparison: A 2026 Perspective
| Feature | Amazon Bedrock | Amazon SageMaker |
|---|---|---|
| Model Access | Curated list of FMs via API | Any model (Hugging Face, Custom, JumpStart) |
| Infrastructure | Serverless (No instances to manage) | Instance-based (P5, G6, Trn2, Inf3) |
| Fine-Tuning | Managed (Adapter-based/LoRA) | Full-parameter, PEFT, RLHF, DPO |
| RAG Integration | Built-in (Knowledge Bases) | Custom (SageMaker Canvas or Manual) |
| Scaling | On-demand or Provisioned Throughput | Manual/Autoscaling of Endpoints |
| Security | Guardrails (Native Filtering) | Network Isolation (VPC, PrivateLink) |
When to Choose Bedrock
Bedrock is the optimal choice when speed-to-market and operational efficiency are the primary drivers.
Use Case: Enterprise Agentic Workflows
If you are building a customer service bot that needs to verify identity, check order status in a SQL database, and issue a refund, Bedrock Agents simplify this complexity. You don't need to manage the underlying LLM hosting; you only define the "Action Groups."
Practical Code Example: Invoking Bedrock with Converse API
The Converse API is the standardized way in 2026 to handle multi-turn dialogues across different models.
import boto3
from botocore.exceptions import ClientError
# Initialize the Bedrock client
client = boto3.client("bedrock-runtime", region_name="us-east-1")
model_id = "anthropic.claude-3-5-sonnet-20240620-v1:0"
# Define the conversation
messages = [
{
"role": "user",
"content": [{"text": "Explain the difference between RAG and Fine-tuning."}]
}
]
# Invoke the model
try:
response = client.converse(
modelId=model_id,
messages=messages,
inferenceConfig={"maxTokens": 512, "temperature": 0.5}
)
# Extract and print the response
output_text = response['output']['message']['content'][0]['text']
print(f"Model Response: {output_text}")
except ClientError as e:
print(f"Error: {e}")What this code does: It uses the high-level converse method which abstracts model-specific prompt templates. This allows you to swap Claude for a Llama or Titan model by simply changing the modelId, without rewriting your message formatting logic.
When to Choose SageMaker
SageMaker is required when you need to own the weights or optimize for extreme latency/throughput.
Use Case: Domain-Specific Model Distillation
Suppose your organization has 10 years of proprietary medical research. You want to train a custom 7B parameter model that outperforms 70B models in your specific niche. You would use SageMaker to run a full-parameter fine-tuning job on a cluster of P5 instances.
Practical Code Example: SageMaker Training with Hugging Face
In 2026, the SageMaker SDK has become even more integrated with open-source libraries.
from sagemaker.huggingface import HuggingFace
# Define hyperparameters for fine-tuning
hyperparameters = {
'model_name_or_path': 'meta-llama/Llama-3.1-8B',
'output_dir': '/opt/ml/model',
'per_device_train_batch_size': 4,
'learning_rate': 2e-5,
'num_train_epochs': 3,
'fp16': True
}
# Initialize the HuggingFace Estimator
hf_estimator = HuggingFace(
entry_point='train.py', # Your custom training script
instance_type='ml.p4d.24xlarge', # High-end GPU instance
instance_count=2, # Distributed training across 2 nodes
role='SageMakerExecutionRole',
transformers_version='4.36',
pytorch_version='2.1',
py_version='py310',
hyperparameters=hyperparameters
)
# Start the training job
hf_estimator.fit({"train": "s3://my-bucket/training-data/"})What this code does: It provisions a cluster of powerful GPU instances, sets up the PyTorch/Transformers environment, distributes the training data from S3, and executes a training script. This level of control over the training environment is not available in Bedrock.
Deep Dive: The Cost Factor
In 2026, cost management is the biggest differentiator.
Bedrock Pricing Models
- On-Demand: You pay per 1,000 tokens. Ideal for unpredictable traffic or low-volume apps.
- Provisioned Throughput: You reserve capacity for a specific model. This is necessary for large-scale production apps requiring guaranteed latency, but it requires a time commitment (1-month or 6-months).
SageMaker Pricing Models
- Instance-based: You pay for the hourly rate of the instance (e.g.,
ml.g6e.xlarge). - Inference Endpoints: You pay for the instance regardless of whether it is processing requests (unless using Serverless Inference, which has limitations on cold starts and model size).
The Rule of Thumb:
- If your traffic is bursty and diverse, Bedrock On-Demand is cheaper.
- If you have high, steady-state volume, hosting a distilled model on SageMaker with Reserved Instances or using AWS Inferentia3 chips often yields a 40-60% cost saving over Bedrock Provisioned Throughput.
Advanced Integration: The Hybrid Approach
Many sophisticated organizations in 2026 don't choose just one. They use a Hybrid GenAI Architecture.
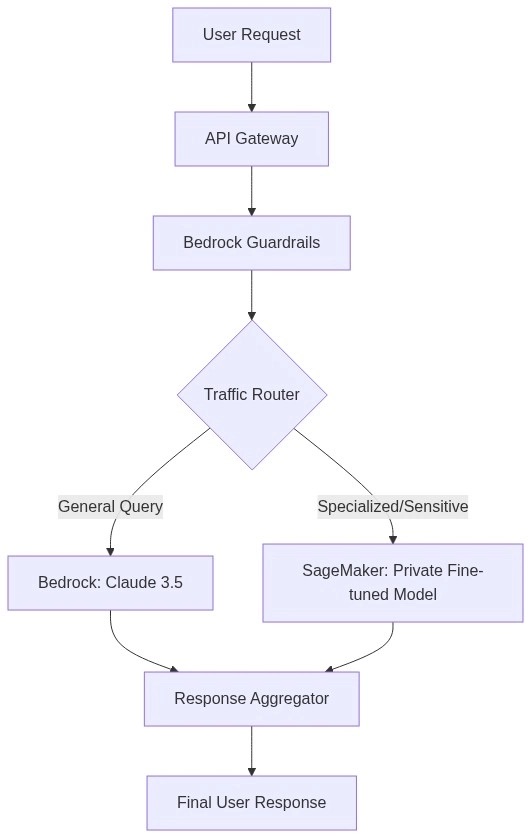
In this hybrid model:
- Bedrock handles general reasoning and common tasks, benefiting from the latest third-party models.
- SageMaker handles highly sensitive data or specialized tasks where a proprietary, smaller model is faster and more secure.
Security and Governance
In 2026, regulatory compliance (like the EU AI Act) requires strict governance.
- Bedrock Guardrails: Provides built-in PII (Personally Identifiable Information) masking and content filtering. This happens at the API level, making it easy to apply across multiple models.
- SageMaker Model Monitor: Allows for deep analysis of data drift and feature attribution. It is better suited for teams that need to explain why a model made a specific prediction for auditing purposes.
Decision Matrix: How to Choose
Ask yourself these four questions:
-
Do you need to customize the model architecture or use specific weights?
- Yes: SageMaker.
- No: Bedrock.
-
Is your team composed of Data Scientists or Application Developers?
- Data Scientists (Deep ML knowledge): SageMaker.
- App Developers (API focus): Bedrock.
-
Does your use case require "Always-On" high-throughput inference for a specific, small model?
- Yes: SageMaker (using Inferentia for cost efficiency).
- No: Bedrock.
-
Do you need to orchestrate multi-step agents with external tools?
- Yes: Bedrock (using Bedrock Agents).
- No: Either (but Bedrock is easier).
Conclusion
In 2026, the choice between Bedrock and SageMaker is no longer about which service is "better," but which fits your operational maturity and performance requirements. Amazon Bedrock has become the default for most enterprise applications, offering a frictionless path to powerful agentic capabilities. Amazon SageMaker remains the essential forge for those creating their own AI "secret sauce" through custom training and optimized deployment.
As models become smaller and more efficient, the ability to deploy them cost-effectively on SageMaker while using Bedrock for high-level reasoning will becom
Published at DZone with permission of Jubin Abhishek Soni. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments