AWS CDK Project Blueprint - Modeling and Organizing (Part 2/2)
The second part of how to model, structure, and organize your Infrastructure-as-Code AWS CDK Project. Building from scratch until a CI/CD pipeline composition, all the cloud component resources, and services at AWS Cloud.
Join the DZone community and get the full member experience.
Join For FreeWelcome back! This is the second part of a two-part article series. With this article, my goal is to build a blueprint to show a way how to model, organize and structure our Infrastructure-as-Code Projects using the AWS-CDK framework. Check here to access the first part of this article.
Now, in this second part, as promised, comes the fun part, we get into the hands-on. Let's run our AWS CDK IaC Project, deploying all the services and resources, and then see the AngularJS Application up and running. Let's get started.
Before Start - Previous Steps
We are using the language Python for our AWS CDK Project, so before starting, we need to perform some previous steps, things like create and activate Python Virtual Environment, downloading the Project's AWS-CDK library dependencies, and also making sure you have already installed the AWS CDK Toolkit. AWS CDK Toolkit is installed using Node Package Manager (npm), for more info check here.
Here's them:
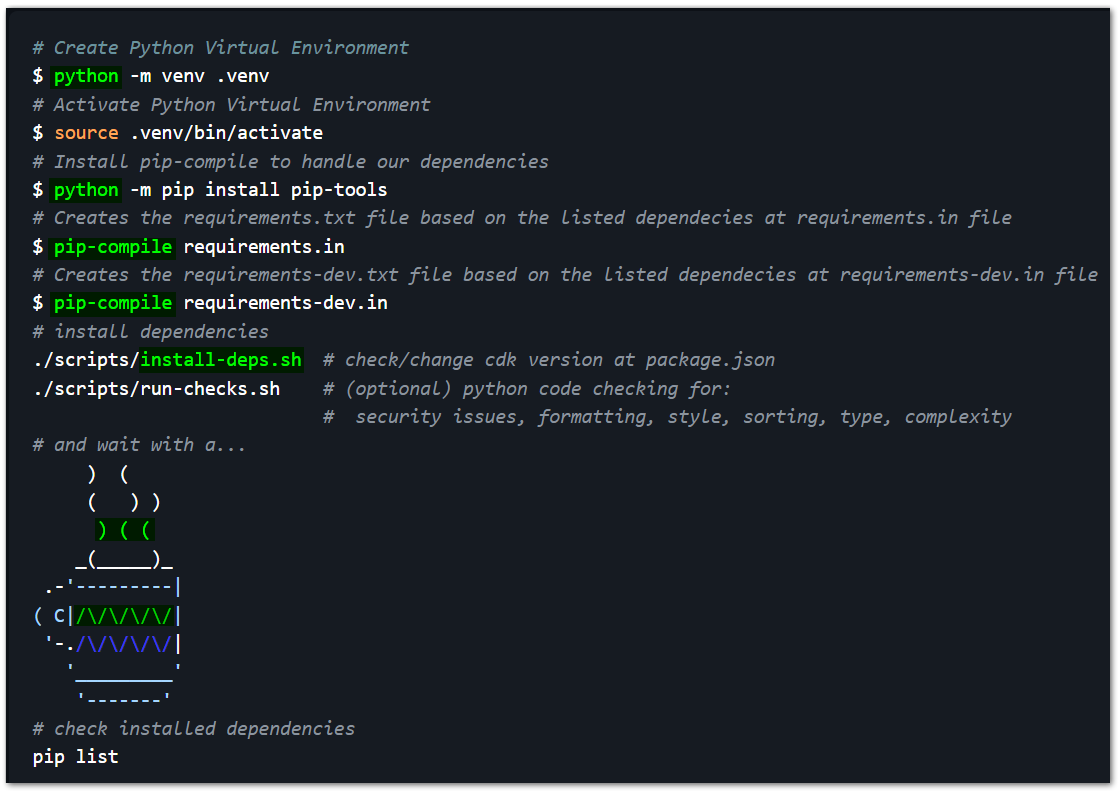
After (and if you) run ./scripts/run-checks.sh, you see this error:
error: Library stubs not installed for "yaml" (or incompatible with Python 3.8) [import]To fix this, run the following command:
python -m pip install types-PyYAMLNow, before going any further, in this same Terminal session, don't forget to open a valid AWS CLI Session for the AWS Account you want to deploy the solution.
The AWS CDK Project comes with a Makefile with several rules that try to help in some repeatable tasks/scripts, mainly those we usually forget, after a period of inactivity over the project. To check all of them, just run make with no parameters. Bear in mind that some of those rules/scripts may need Environment Variables set, like AWS Account and Region (check ./scripts/set-env-template.sh). Later on, we are going to use some of these Makefile rules in an attempt to make our life easier.
Let's try out, to be presented with a list of all Stacks in this CDK App, and choose one (or all of them) to synthesize (AWS CloudFormation template translation), execute this command:
make synth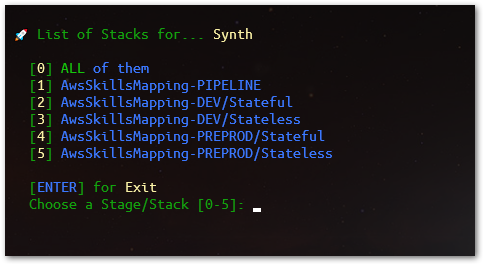
Bootstrapping
Before deploying anything with AWS CDK, we need to prepare the environment (combination of an AWS account and region). For that, we have to provide the resources the AWS CDK needs to perform the deployments. Things like Amazon S3 Bucket for storing files, and IAM Roles that grant permissions to perform deployments. The process of provisioning these initial resources is called bootstrapping.
Using the command make check-bootstrap we can check the bootstrap status for all of our environments if they were or are not bootstrapped yet.
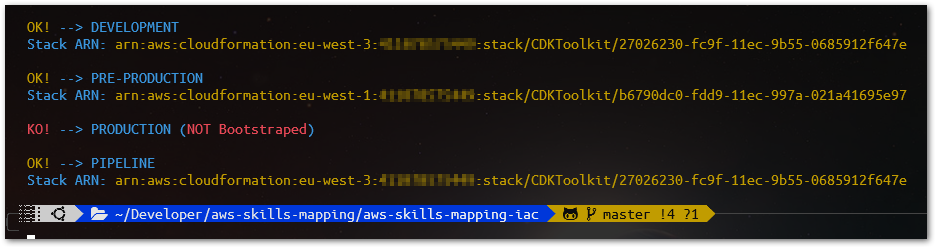
More on this, check here.
Deploying
Now, let's deploy the solution. Remember, the configuration YAML files we have seen in the first part of this article, have the AWS Account and AWS Region that are going to be used to deploy each distinct stage.
In the app.py we instantiate our IaC modeled application (defined at deployment.py) twice, each one for the two distinct stages (Dev and Pre prod), loading them with their respective specific configuration. We add both to the cdk.App, the root construct of an AWS CDK application.
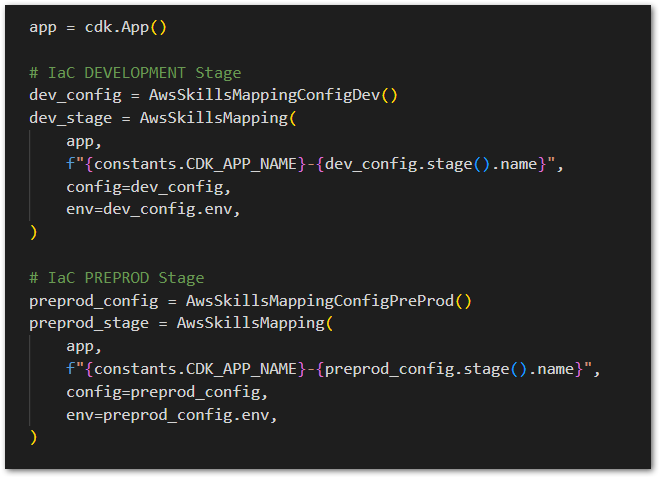
We can, of course, deploy each stage separately and isolated. For instance, deploy only the Dev stage (AwsSkillsMapping-DEV/Stateful and AwsSkillsMapping-DEV/Stateless). In the case of performing specific Stacks deployment, bear in mind the dependencies mentioned in the first part of this article. For that same reason, to deploy all the solution (all Stacks, including the Pipeline), let's use a Makefile rule/script called deploy-all. It will deploy them in the proper sequence, first and all together Dev/* and Preprod/*, and then, the Pipeline. Below, the sequence is shown before starting:
make deploy-all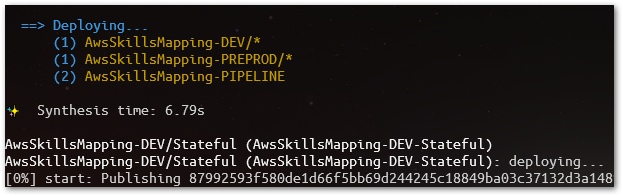
Now would be a good time for some coffee...
After some time, in the middle of the Pipeline deployment, the e-mails configured in ./configuration/pipeline.yml (for sre-team and application-team) will receive a notification requesting them to confirm their subscription, like this:
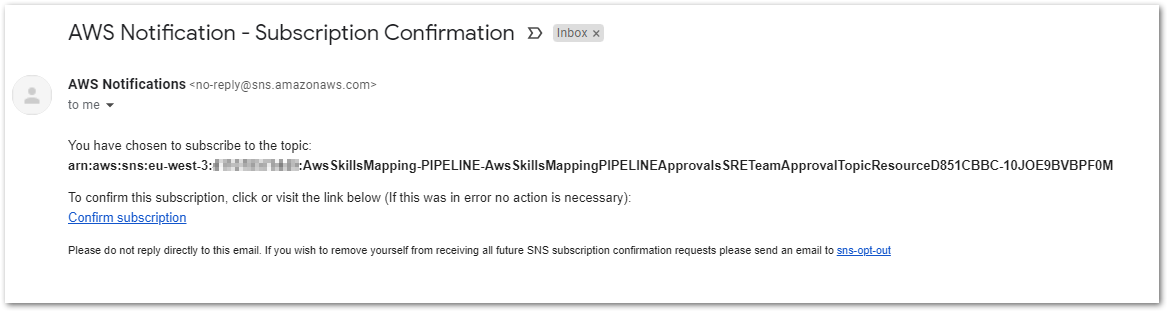
We wait until...
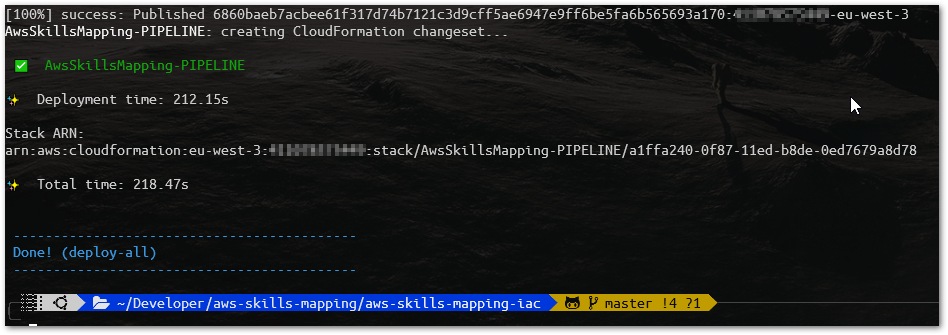
Checking the Results
When the deployment is finalized, we will find a file named deploy-outputs-dev-preprod.json, there we can find in the AwsSkillsMapping-DEV-Stateful, and in the AwsSkillsMapping-PREPROD-Stateful section, the S3 Website URLs. But before opening them in our navigator, we have to run our Pipeline once, at least (deploying the AngularJS in the S3 Bucket).
Notice! The Pipeline application, still during its deployment by AWS CDK, before everything is finished, will trigger a CodePipeline Release, that might fail with something like: "is not authorized to perform: codebuild:StartBuild on resource". It happens because the Pipeline deployment is still on course. After the Pipeline deployment has really finalized, you could, either in the CodePipeline hit the "Retry" button at the Build-DEV stage that failed, or simply start a new CodePipeline Release.
If we confirm the subscription mentioned before, we're going to receive a notification e-mail saying that de CodePipeline needs our approval. At this point, the Dev stage of our AngularJS application is already deployed, and the CodePipeline is stopped waiting for the Approvals to go ahead for Pre prod deployment.

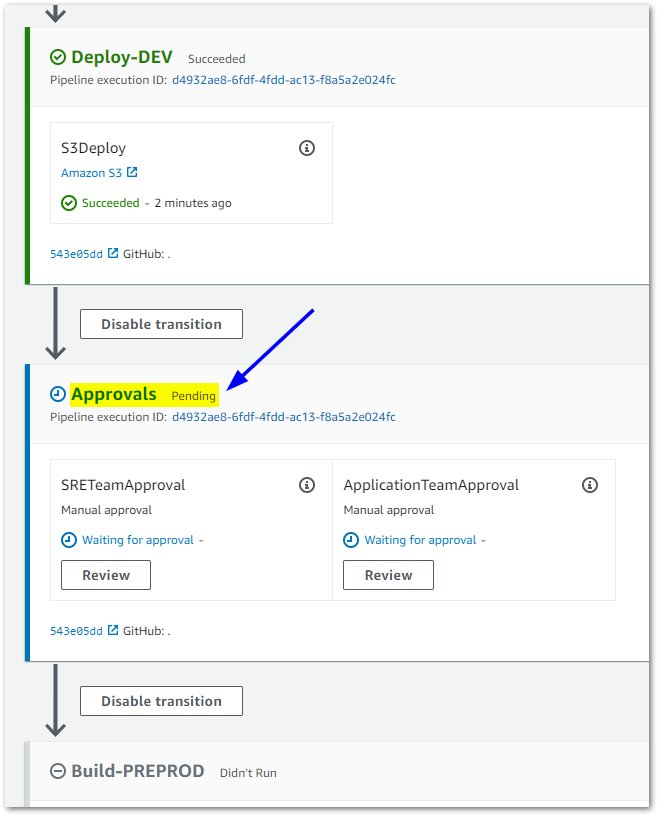
There you are! After the CodePipeline release has finished successfully, we can open both S3 Website URLs. To visually and easily differentiate between the Dev and Pre prod, the AngularJS application has different toolbar colors for each one of them. Don't forget (to save some money), remember to clean all resources, you can use the command make destroy-all for that.
What's Next?
As a next step "in the evolution", we could extract some of the Logical Units (e.g. API) we have used in this AWS CDK Project and transform them into reusable components for other projects, i.e. create our own "generic" reusable Constructs. Then, we can compose our own library of AWS CDK Cloud Components (with some technical or business semantics embedded already), making our own common building blocks useful for all other IaC AWS CDK Projects. That way, for instance, a team could create a DynamoDB Table component that encapsulates the company's best practices and policies, already embedded (e.g. backup, monitoring, scaling, etc.). In the case of Python, handling those libraries with the Python Package Installer (pip, PyPI).
But this would be a story for another future article. :-)
Conclusion (Part 2/2)
In the second part of this two-part article, we went through all the steps to deploy our IaC AWS CDK Application, as well the AngularJS Application sample using CodePipeline. We tested whether the implemented design model, structure, and organization fulfill our needs (at the moment), and help us to achieve our objectives in building IaC projects with the AWS CDK framework. And mostly, this project is intended to be a sandbox, a "living" blueprint model, that we are continuously analyzing, checking, thinking, and modifying, seeking improvements that make us do a better job.
The source code of this IaC AWS CDK Project and all of the artifacts used in this blueprint solution are available in the two Github repositories provided below:

Published at DZone with permission of Ualter Junior. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments