Transform Settlement Process Using AWS Data Pipeline
Modern AWS data pipelines automate ETL for settlement files using S3, Glue, Lambda, and Step Functions, transforming data from raw to curated with full orchestration.
Join the DZone community and get the full member experience.
Join For FreeData modernization involves simplifying, automating, and orchestrating data pipelines, as well as improving the claim and settlement process using various AWS SaaS services, converting large data settlement files to a new business-required format. The task involves processing settlement files from various sources using AWS data pipelines. These files may be received as zip files, Excel sheets, or database tables. The pipeline applies business logic to transform inputs (often Excel) into outputs (also in Excel).
Our inputs typically come from a variety of sources. Utilize inputs from existing AWS tables and external inputs in Excel format. These diverse inputs are ultimately converted to Parquet format. This documentation outlines the process and includes the AWS data pipeline ETL jobs architecture for replication purposes.
This modernization involves standardized procedures for ETL jobs. Event rules are set based on domain and tenant. For instance, a file landing in S3 triggers a Lambda function as part of our Glue ETL job, which identifies the file type, unzips if necessary, and converts it into Parquet format. Files move through S3 layers: landing, exploratory, and curated, with specific transformations stored in DynamoDB.
Domains
Producer provides data, consumer generates new outputs. Entities can act as both. it has involved capturing the entire architecture, outlined in the diagram showing zones (raw, exploratory, curated) and file movement. Data ingestion methods include MFT processes. Data transitions from raw to exploratory to curated zones, undergoing transformations and final formatting for third-party access or local downloads.
AWS Data Pipeline Architecture
The architecture involves AWS components such as S3, DynamoDB, Event Bridge, Lambdas, and ETL jobs using the Glue ETL architecture, including AWS Glue Catalog and Athena. Depending on your use case, it may utilize all or some of these components. Also, use of SNS for notification if jobs has been failed and monitoring has been done via CloudWatch. Since this architecture use for mostly AWS cloud native services so it help a lot in terms of scaling the settlement process, pay as use since process / files can be received based on settlement (daily, weekly, monthly, quarterly and yearly) . In below architecture diagram depiction of how the flow processed each and every steps.
Jobs use patterns and metadata, specifying details like catalogue names and destinations for Spark SQL transformations. Data retrieval from S3 uses file patterns, checking dependencies before proceeding. The process includes audit logs and resource decisions (Athena and Glue). Specify job names and scripts for ETL Glue jobs, ending with data placement in S3's curated layer and integration into a Glue catalogue table for querying via Athena.
AWS SNS handles notifications, ensuring efficient processing across different services. Configuration can be done via RSS, with SNS providing notifications. Example: files from four domains in an S3 bucket trigger events via step functions connected to Lambda functions, retrieving information from DynamoDB to initiate Glue ETL jobs, storing processed data in various S3 locations. Notifications are sent upon data reaching curated buckets, used to build Glue catalogue tables accessible via Athena. Input files transformed into output files feed another pipeline for further processing.
The following illustrates an end-to-end file processing ETL job pipeline.
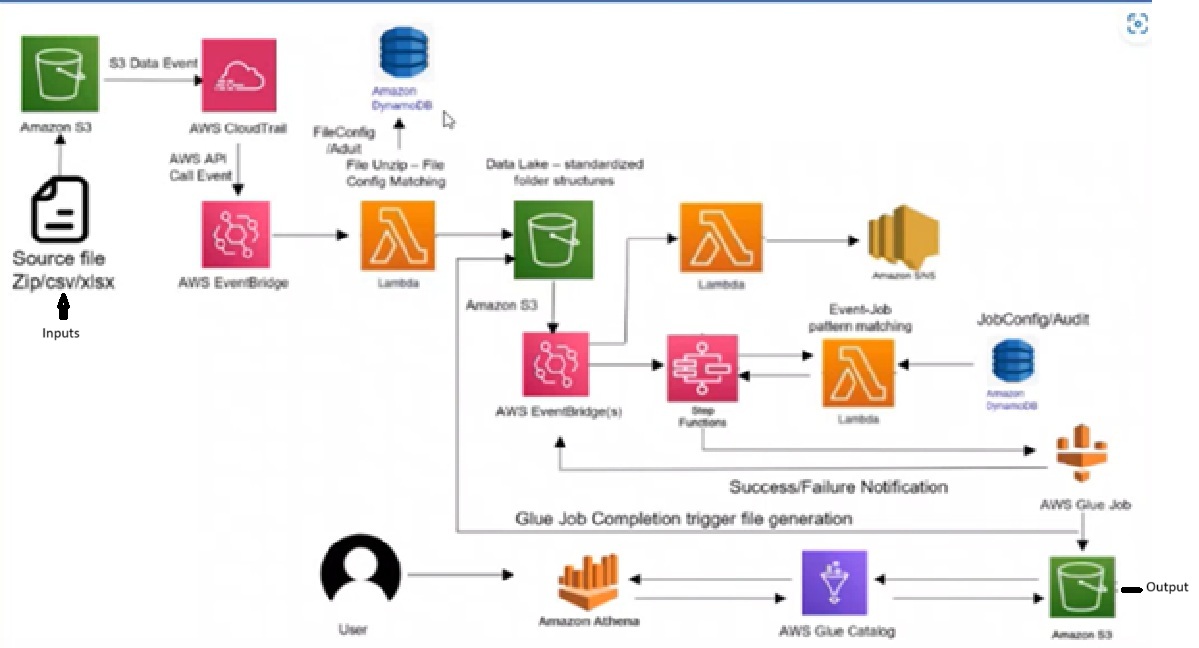
Event Rules and Domains
This section described the setup of event rules in AWS, which trigger ETL processes when files are dropped in specific S3 folders. It also explains how domains and tenants in AWS are used to create the data pipeline, depicted in architectural diagrams.
S3 Layer Storage
Landing Zone
This is where files first arrive, usually within the landing bucket. This could serve as the destination for source files.
Exploratory Zone
In this zone, files are converted from other formats to Parquet format. Initially, files such as those in Excel format will be converted to Parquet in the base folder. From here, they proceed to the reprocessing phase, where all transformations occur.
Curated Zone
Calculations or column manipulations are performed within this area before moving the data to the curated zone, which contains the cleanest version of data for others to use. There are two types of domains: consumer and producer.
This S3 file architecture involves the exploratory zone, landing zone, and curated zone. Based on specified rules and domains, it triggers the ETL process or jobs using AWS Glue, Step Functions for orchestration, and a data lake for a single source of truth. This approach aims to create a unified and integrated data repository providing real-time insights to both internal and external users.
The cloud-native solutions integrate data from various sources, including structured, unstructured, and time-series data, with metadata retrieved from AWS DynamoDB.
File Processing and Metadata
This section covers the process of unzipping files using Lambda functions and fetching metadata from DynamoDB. It describes the different layers of S3 (landing, exploratory, and curated) and the processing that occurs within these layers, including transformations and data type conversions.
Data is catalogued with Glue tables for each S3 folder. The enterprise domain stores clean data without a landing zone, defining exploratory and application buckets. Exploratory data undergoes internal transformations before moving to the curated zone, all catalogued with Glue tables reflecting S3 structures. Specific columns like "process date" aid in quick issue resolution. Failures in transformations can be diagnosed via CloudWatch logs, commonly due to misconfigurations or incompatible data types.
Step Function Orchestration, Lambda and DynamoDB Configurations
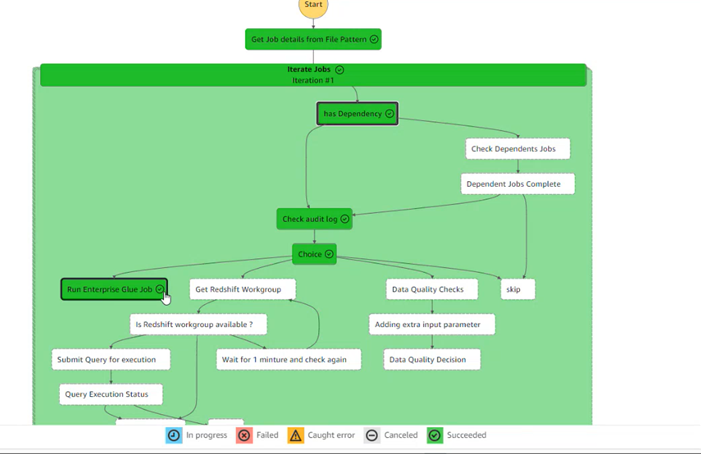
The step function orchestration used in pipeline, which handles the entire ETL process. step function fetches job details from DynamoDB based on file patterns and executes customized jobs using SQL queries or Python scripts.
Step functions orchestrate everything, using metadata from DynamoDB to guide file movements and transformations. Background Lambda manage transfers between S3 buckets. Business logic is within DynamoDB configurations while orchestration uses standardized functions. The step function starts with a file drop in S3, fetching job details from DynamoDB, guiding the process based on file patterns. Adjust settings in the metadata for CSV headers or quotes. Over 100 pipelines operate in AWS, handling multiple inputs and outputs.
Below is a diagram of the job workflow.
Error Handling and Debugging
Error handling during the transformation process in the exploratory layer is described. Errors are logged in CloudWatch and DynamoDB, and failed jobs can be debugged and retried by fixing the errors and retriggering the ETL job.
Final Output and Notifications
Data transitions from raw to exploratory to curated zones, undergoing transformations using the flow and final formatting for third-party access or local downloads. All output files are available in S3 curated bucket, and it can send to downstream systems or available for download also. Once ETL job success or fails via SNS notification also triggered and send to respective members.
Conclusion
Settlement files can come from various sources (daily, monthly, quarterly, or yearly) based on the use case. The described data pipeline streamlines the settlement process and shares the final output files with different downstream systems. Using AWS native services reduces downtime and enhances processing speed and accuracy. The scalable architecture allows new sources to be added as required by the specific ETL jobs.
Published at DZone with permission of Prabhakar Mishra. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments