Azure Cosmos DB — A to Z
In this article, explore Azure Cosmos DB and look at consistency, automatic indexing, and more.
Join the DZone community and get the full member experience.
Join For Free
Introduction
Cosmos DB can be considered one of the most lethal weapons in Azure’s arsenal. It comes with a bunch of features that makes this service stand out among its various database offerings.
Recently, I utilized it for a flash sale requirement, where the hits-per-second requirement was more than 6k, the application was storing the users and orders details from multiple regions in real-time.
We evaluated multiple databases and settled on Cosmos DB based on its high scalability, ease of use and globally distributed approach. This can be a good choice for highly data-intensive systems like IoT and telematics, online gaming applications, and more. In this blog, I've touched upon the concepts of Cosmos DB.
Cosmos DB Features
Here I’m highlighting some of the features that will help you in identifying whether it's a good fit for your use case or not.
- Globally Distributed: Cosmos DB can be deployed across regions. Suppose you are currently running only with Australia East; this can easily be replicated to other regions like Australia Central or US Central etc. It’s a multi-master setup.
- Highly Scalable: The read and write capacity of the database can be easily managed based on RUs (Read units). RUs are described later in this tutorial. This will be of help if you want to scale for some event like a flash sale.
- Low Latency: Azure Cosmos DB guarantees end-to-end latency of reads under 10ms and indexed writes under 15ms at the 99th percentile within the same Azure region
- Multi-Model: Cosmos DB is a multi-model database, meaning it can be used for storing data in Key-value Pair, Document-based, Germlin, and Column Family-based databases. There are multiple models that can be utilized.
- Cassandra API and MongoDB API: If you are already using Cassandra or MongoDB, then you can migrate to Cosmos DB without much changes in the code. A wide column format can be used.
- SQL API: If you are familiar with SQL queries or if you’re starting from scratch, you can go with SQL API. It is the most native version of working with Cosmos.
- Storage Table: Store your data as key and value pairs. This solution uses the standard Azure table API, which follows the same schema and design as Azure table storage.
- Gremlin API: This model is used to create the graph databases to hold the relationships. This is an open-source API based on Apache TinkerPop.
- High Availability: Data can be replicated across regions. Within single regions, the SLA is 99.99%, whereas for multi-region setup SLA is 99.999%. Under the hood, data is distributed across partitions, within each region this partition is replicated.
- Consistency: Based on the CAP theorem, a system can have only 2 of the 3: Consistency, Availability, and Partition Tolerance. Developers need to understand the trade-offs. Cosmos DB provides multiple consistency options.
Consistency Levels
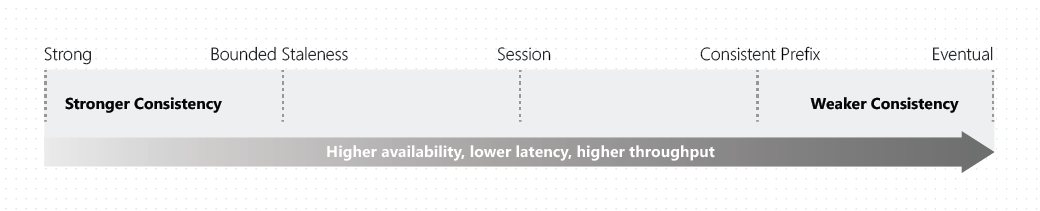
- Strong Consistency: User never sees an uncommitted or partial write. Reads are guaranteed to return the most recent committed version of an item. Highest consistency and low throughput and as you scale, write latency will further deteriorate.
- Bounded Staleness: Instead of 100% consistency, this level allows a lag in operations or time. It is kind of a MySQL dirty read. For example, you can configure the database to allow a lag of 5 seconds. It is eventual, but you can control the eventuality. Consistency is still high, but throughput is low.
- Session Consistency: It is the default consistency. This is bounded by session; it can be considered strongly consistent within that session and anything outside that session may or may not lag. This provides good performance and good throughput.
- Consistent Prefix: Reads are consistent to a specific time, but not necessarily the current timestamp. It is similar to Bounded Staleness in that you neither control nor know the lag if there is any. Normally you can see the delays in seconds. Good performance and excellent availability.
- Eventual Consistency: No guarantee how much time it will take to become consistent. Moreover, updates aren’t guaranteed to come in order. This is also the highest performing, lowest cost, and highest availability level.
Automatic Indexing
Indexing policy is defined over a container, which explains how the data within that container can be indexed. The default is to index every property of each item. This can be customized by specifying the required indices.
The concept of an index is pretty similar to any other database: it enhances the read performance and negatively affects the write performance. Be cautious and identify the right indexes for your application. More indexes also mean more data and then more RUs, which in turn means less performance and more cost. You can include or exclude the properties from indexing by defining them in the include path and exclude path.
Include the root path to selectively exclude paths that don't need to be indexed. This is the recommended approach as it lets Azure Cosmos DB proactively index any new property that may be added to your model. Exclude the root path to selectively include paths that need to be indexed.
Indexing Mode
- Consistence: The index is updated synchronously as you create, update or delete items.
- None: Indexing is disabled on the container when you don't need the secondary index.
Indexes Types
- Hash: Supports efficient equality queries.
- Range: Supports efficient equality queries, range queries, and order by queries.
- Spatial: Supports efficient spatial (within and distance) queries. The data type can be Point, Polygon, or LineString.
Partition Keys
![Image title]()
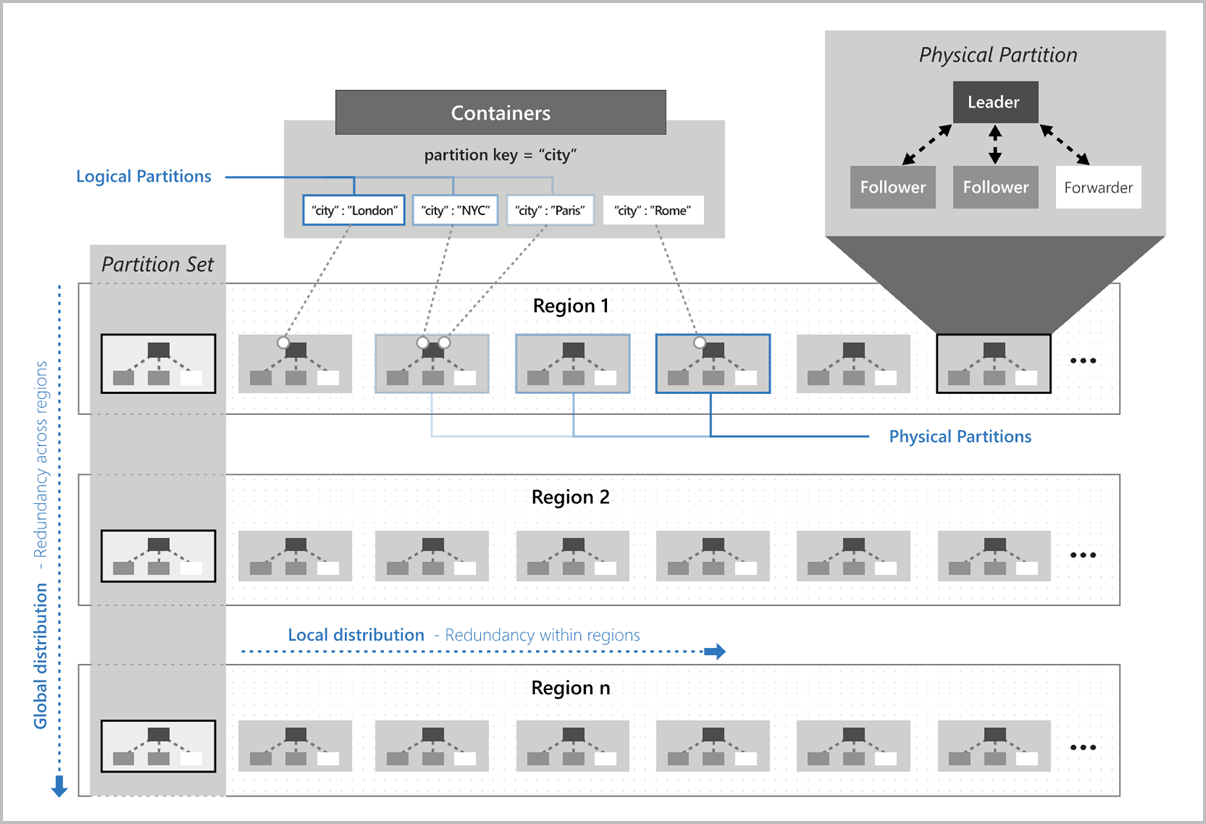
Behind the scenes, Cosmos DB uses distributed data algorithm to increase the RUs/performance of the database, every container is divided into logical partitions based on the partition key. The hash algorithm is used to divide and distribute the data across multiple containers. Further, these logical containers are mapped with multiple physical containers (hosted on multiple servers).
Placement of Logical partitions over physical partitions is handled by Cosmos DB to efficiently satisfy the scalability and performance needs of the container. As the RU needs increase, it increases the number of Physical partitions (More Servers).
As the best practice, you must choose a partition key that has a wide range of values and access patterns that are evenly spread across logical partitions. For example, if you are collecting some data from multiple schools, but 75% of your data is collected from one school only, then, it’s not a good idea to create the school as the partition key.
Throughput
Cost is very much dependent on the throughput you have provisioned. Remember it's not whatever you are consuming, it is whatever you have provisioned. Throughput is further expressed as RUs (Read Units); this defines the read and write capabilities per container or database. It abstracts the system resources such as CPU, IOPS, and memory that are required to perform the database operations.
The following are the parameters that define the RUs requirement.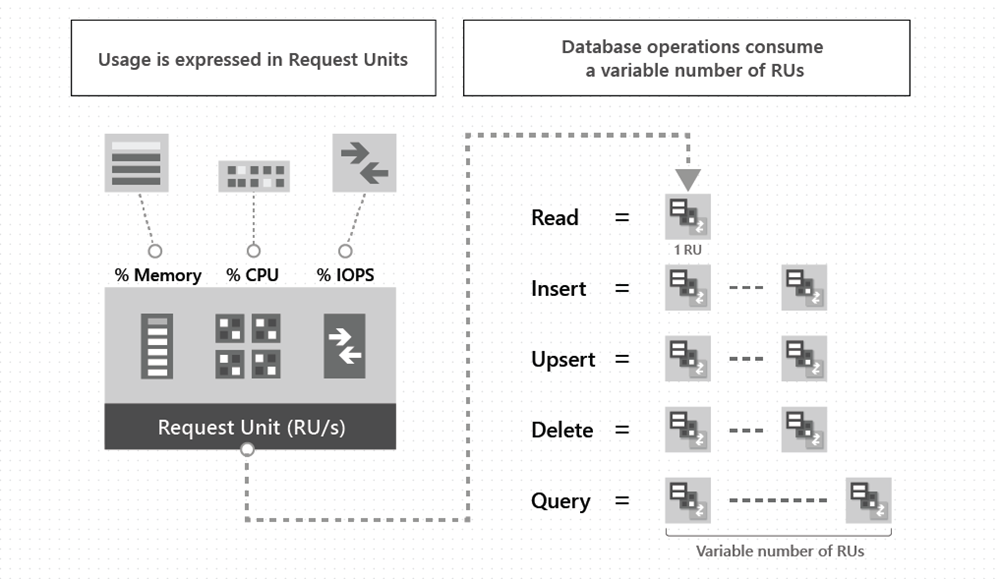
Item Size
• Indexing
• Item Property Count
• Indexed Properties
• Consistency level
• Query Complexity
• Script Usage
Cosmos DB will throttle the requests if you try to run any load where the RU/s requirement is more than the defined due to rate limiting. Cosmos DB throws "Too many Request" responses with a status code of 429. Along with the response, it also returns a header with a value, which defines after how much time you can retry.
Programmatic Access Sample (Python)
In this section, I have provided a brief introduction of the SQL APIs. SQL APIs supports the CRUD functionality. In case, you don't get the required SDK, you can switch to this mode.
The most prominent and tricky part of the API access is the creation of the authorization string. Entities required to create the string are:
- Master Key: Best practice is to keep it inside the AzureVault. During the operations, you can call the Vault APIs to fetch the master keys and keep it in the memory.
- ResourceID: This is the path of the object, which you want to reference or more precisely the parent path of the object. Example for docs — the parent will be the collection, so it should be the complete path of the collection. "/dbs/{databasename}/colls/{collectionname}/docs"
- Resource Type: Type of the resource you want to access. For the database, it is dbs, for collections, it is colls, and for documents, it is docs.
- Verb: HTTP verb like "Get," "POST," or "PUT."
- x-ms-date: This should be UTC date and time the message was sent. Format "Fri, 29 Nov 2019 08:15:00 GMT".
Authorization String Creation
- Create a payload string: Verb.toLowerCase() + "\n" + ResourceType.toLowerCase() + "\n" + ResourceLink + "\n" + Date.toLowerCase() + "\n" + "" + "\n"
- Encode the payload string with base64
- Generate a signature by applying an HMAC-SHA512 hash function
- URL encode the string type={typeoftoken}&ver={tokenversion}&sig={hashsignature}
Samples
Authentication String Generation
xxxxxxxxxx
#master keys
key = 'abcdefghijklmnopqrstuvwxyz=='
#Date Generation UTC Format.
now = datetime.utcnow().strftime('%a, %d %b %Y %H:%M:00 GMT')
print(now)
#Verb is "Get", resourceID is "dbs/testcosmosdb/colls/testcosmostable", resource type is "docs"
payload = ('get\ndocs\ndbs/testcosmosdb/colls/testcosmostable\n' + now + '\n\n').lower()
#Base64 Encoding
payload = bytes(payload, encoding='utf8')
key = base64.b64decode(key.encode('utf-8'))
#HMAC hashing
signature = base64.b64encode(hmac.new(key, msg = payload, digestmod = hashlib.sha256).digest()).decode()
#URL Encoding
authStr = urllib.parse.quote('type=master&ver=1.0&sig={}'.format(signature))
print(authStr)
Database Creation
xxxxxxxxxx
import requests
import json
import hmac
import hashlib
import base64
from datetime import datetime
import urllib
key = 'abcdefghijklmnopqrstuvwxyz=='
now = datetime.utcnow().strftime('%a, %d %b %Y %H:%M:00 GMT')
payload = ('post\ndbs\n\n' + now + '\n\n').lower()
payload = bytes(payload, encoding='utf8')
key = base64.b64decode(key.encode('utf-8'))
signature = base64.b64encode(hmac.new(key, msg = payload, digestmod = hashlib.sha256).digest()).decode()
authStr = urllib.parse.quote('type=master&ver=1.0&sig={}'.format(signature))
print(authStr)
headers = {
'Authorization': authStr,
"x-ms-date": now,
"x-ms-version": "2017-02-22"
}
data={"id":"mydb"}
url = 'https://mycosmosdb.documents.azure.com/dbs'
res = requests.post(url, headers = headers ,data = json.dumps(data))
print(res.content)
Collection Creation with custom Index and partition keys
xxxxxxxxxx
import requests
import json
import hmac
import hashlib
import base64
from datetime import datetime
import urllib
key = 'abcdefghijklmnopqrstuvwxyz=='
now = datetime.utcnow().strftime('%a, %d %b %Y %H:%M:00 GMT')
payload = ('post\ncolls\ndbs/mydb\n' + now + '\n\n').lower()
payload = bytes(payload, encoding='utf8')
key = base64.b64decode(key.encode('utf-8'))
signature = base64.b64encode(hmac.new(key, msg = payload, digestmod = hashlib.sha256).digest()).decode()
authStr = urllib.parse.quote('type=master&ver=1.0&sig={}'.format(signature))
//Custom Index
headers = {
'Authorization': authStr,
"x-ms-date": now,
"x-ms-version": "2017-02-22"
}
data={ "id": "mytable1",
"indexingPolicy": {
"automatic": True,
"indexingMode": "Consistent",
"includedPaths": [
{
"path":"/userId/?",
"indexes": [
{
"dataType": "String",
"precision": -1,
"kind": "Range"
}
]
},
{
"path": "/\"_ts\"/?",
"indexes": [
{
"kind": "Range",
"dataType": "Number",
"precision": -1
},
{
"kind": "Hash",
"dataType": "String",
"precision": 3
}
]
}
],
"excludedPaths":[
{
"path":"/*",
}
]
},
"partitionKey": {
"paths": [
"/userId"
],
"kind": "Hash",
"Version": 2
}
}
url = 'https://mycosmosdb.documents.azure.com/dbs/mydb/colls'
res = requests.post(url, headers = headers ,data = json.dumps(data))
print(res.content)
Document Creation
xxxxxxxxxx
import requests
import json
import hmac
import hashlib
import base64
from datetime import datetime
import urllib
key = 'abcdefghijklmnopqrstuvwxyz=='
now = datetime.utcnow().strftime('%a, %d %b %Y %H:%M:00 GMT')
payload = ('post\ndocs\ndbs/mydb/colls/mytable1\n' + now + '\n\n').lower()
payload = bytes(payload, encoding='utf8')
key = base64.b64decode(key.encode('utf-8'))
signature = base64.b64encode(hmac.new(key, msg = payload, digestmod = hashlib.sha256).digest()).decode()
authStr = urllib.parse.quote('type=master&ver=1.0&sig={}'.format(signature))
headers = {
'Authorization': authStr,
"x-ms-date": now,
"x-ms-version": "2017-02-22",
"x-ms-documentdb-partitionkey": "[\"iasbjsb25\"]"
}
data={"id": "order1", "userId": "iasbjsb25"}
url = 'https://mycosmosdb.documents.azure.com/dbs/mydb/colls/mytable1/docs'
res = requests.post(url, headers = headers ,data = json.dumps(data))
print(res.content)
Read documents (Query)
xxxxxxxxxx
import requests
import json
import hmac
import hashlib
import base64
from datetime import datetime
import urllib
key = 'abcdefghijklmnopqrstuvwxyz=='
now = datetime.utcnow().strftime('%a, %d %b %Y %H:%M:00 GMT')
payload = ('post\ndocs\ndbs/mydb/colls/mytable\n' + now + '\n\n').lower()
payload = bytes(payload, encoding='utf8')
key = base64.b64decode(key.encode('utf-8'))
signature = base64.b64encode(hmac.new(key, msg = payload, digestmod = hashlib.sha256).digest()).decode()
authStr = urllib.parse.quote('type=master&ver=1.0&sig={}'.format(signature))
headers = {
'Authorization': authStr,
"x-ms-date": now,
"x-ms-version": "2018-12-31",
"x-ms-documentdb-isquery": "True",
"Content-Type":"application/query+json",
"x-ms-documentdb-query-enablecrosspartition": "True"
}
data={ "query": "select * from mytable c",
"parameters":[{
"name": "@userId",
"value": "iasbjsb25"
}]}
url = 'https://mycosmosdb.documents.azure.com/dbs/mydb/colls/mytable/docs'
res = requests.post(url, headers = headers ,data = json.dumps(data))
print(res.content)
Read documents (By ID)
import requests
import json
import hmac
import hashlib
import base64
from datetime import datetime
import urllib
key = 'abcdefghijklmnopqrstuvwxyz=='
now = datetime.utcnow().strftime('%a, %d %b %Y %H:%M:00 GMT')
print(now)
payload = ('get\ndocs\ndbs/mydb/colls/mytable/docs/order1\n' + now + '\n\n').lower()
payload = bytes(payload, encoding='utf8')
print("payload is \n" )
print(payload)
key = base64.b64decode(key.encode('utf-8'))
print("Key is \n")
print(key)
signature = base64.b64encode(hmac.new(key, msg = payload, digestmod = hashlib.sha256).digest()).decode()
authStr = urllib.parse.quote('type=master&ver=1.0&sig={}'.format(signature))
headers = {
'Authorization': authStr,
"x-ms-date": now,
"x-ms-version": "2018-12-31",
"x-ms-documentdb-partitionkey": "[\"iasbjsb25\"]"
}
url = 'https://mycosmosdb.documents.azure.com/dbs/mydb/colls/mytable/docs/order1'
res = requests.get(url, headers = headers)
print(res.content)
Recommendations
- Cosmos DB performance can be monitored from Metric Page or Azure Monitoring. Reports/Graphs can be fetched based on timeframes, regions, and containers.
- Use Replication across the globe at least in two regions if the data is very critical.
- Create alerts to check the performance and the RUs requirements continuously.
- Create alerts to verify the attacks.
- Automated backups are already there. Retention period and frequency can be increased by using the Datafactory.
- Cosmos DB access key should be saved inside the vault and not inside the code.
- Storage encryption is already managed by Microsoft.
- Configure proper permissions to the users using IAM, follow the principle of least privilege.
Default Firewall allows "All Network", this should be configured for whitelisting the specific IPs or limiting the access to particular VNets. - Geo-fencing can be done.
- Data in-transit should be accessible through SSL only.
Further Reading
Experience Using Azure Cosmos DB in a Commercial Project
Opinions expressed by DZone contributors are their own.
Comments