Azure Data Factory Interview Questions
This article presents some of the most commonly asked Azure Data Factory interview questions for experienced professionals
Join the DZone community and get the full member experience.
Join For FreeAs cloud computing continues to gain popularity, more and more organizations are adopting cloud-based data solutions to manage their ever-growing data needs. One of the most popular data integration services in the cloud is Azure Data Factory, a fully managed, cloud-based data integration service that allows you to create, schedule, and orchestrate ETL and ELT workflows.
With the increasing demand for Azure Data Factory expertise, it's no surprise that experienced professionals in the field are in high demand. If you're looking to land a job as an Azure Data Factory expert or simply looking to improve your knowledge in the area, it's important to be well-prepared for the interview process.
In this article, we'll take a look at some of the most commonly asked Azure Data Factory interview questions for experienced professionals. These questions cover a wide range of topics, from basic concepts to more advanced scenarios, and will help you understand what interviewers are looking for in a candidate. Whether you're preparing for an interview or simply want to expand your knowledge, this article will provide valuable insights into Azure Data Factory.
Before we go for ADF Interview Questions, let’s first understand what exactly is the Azure Data Factory.
What Is Azure Data Factory?
Azure Data Factory is a cloud-based data integration service that allows us to create, schedule, and manage workflows to move and transform data. It helps in integrating data from different sources, such as (on-premises data sources), (cloud data sources), and (hybrid data sources), etc. then transforming it into a format that meets the required needs.
Azure Data Factory provides a fully managed, scalable, and reliable platform for building data integration solutions, which allows us to focus on data rather than infrastructure. It also provides a graphical user interface and a code-based environment for building and managing data pipelines.
It also supports various data processing activities such as copy, transform, and load (ETL) and extracts, load, and transform (ELT), which helps in enabling us for creating workflows that fit our specific needs. Additionally, it integrates with various Azure services such as Azure Databricks, Azure Synapse Analytics, Azure HDInsight, and Azure Machine Learning, allowing you to create end-to-end solutions for your data needs.
Now, let’s look at some Azure Data Factory interview questions for experienced professionals.
1. Can You Explain the Architecture of Azure Data Factory and Its Components?
In addition to the definition of what Azure Data Factory is, it is a fully managed service, meaning that Microsoft handles the infrastructure and maintenance of the service so that we can only focus on our data integration tasks without worrying about data management.
The architecture of Azure Data Factory consists of several components that work together and provides a complete data integration solution. Some of the main components are:
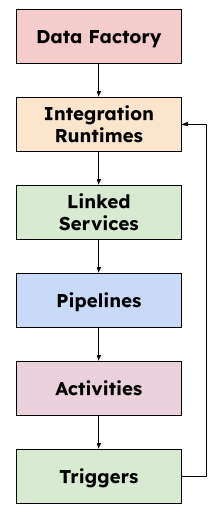
Data Factory: This is the main component of Azure Data Factory. It serves as the management and orchestration layer for all data integration tasks. It provides a graphical user interface (GUI) as well as a REST-based API for creating, scheduling, and managing data pipelines.
Integration Runtimes: These are computed environments that run the data integration tasks. There are three types of integration runtimes in Azure Data Factory:
a. Azure: This is a fully managed integration runtime that runs within the Azure environment.
b. Self-hosted: This integration runtime is installed on (on-premises servers or virtual machines), and it is used to move data between on-premises systems and the cloud.
c. Azure-SSIS: This integration runtime is used to run SQL Server Integration Services (SSIS) packages within ADF.
Linked Services: These are the connections to data sources and destinations, such as Azure Storage, Azure SQL Database, and Amazon S3. It provides the connection information and authentication credentials needed to access these data sources.
Pipelines: These are the workflows that move and transform data between sources and destinations. This consists of one or more activities that perform specific data integration tasks, such as copying data, transforming data, or running a stored procedure.
Activities: These are the building blocks of pipelines, and each activity performs a specific data integration task. For example, a ‘Copy Activity’ can copy data from one source to another, and a ‘Data Flow’ activity can transform data using a visual data transformation tool.
Triggers: These are used to schedule the execution of pipelines at a specified time or when a specific event occurs, such as the arrival of new data in a source system.
These components can be used in conjunction to build complex data integration workflows that transfer and transform data between different sources and destinations.
2. How Do You Handle Failures and Retries in Azure Data Factory Pipelines?
Azure Data Factory provides built-in mechanisms for handling failures and retries in pipelines. Here are some ways to handle failures and retries in ADF pipelines:
- Retry policy: ADF allows configuring retry policies for each activity within a pipeline. We can set the number of retries, the interval between retries, and the maximum wait time for the retry attempts.
- Checkpoints: Checkpoints allow restarting a pipeline from the point of failure rather than rerunning the entire pipeline. ADF automatically creates checkpoints for activities that support it, and we can also manually create checkpoints at specific points in the pipeline.
- Error handling: We can configure error handling for each activity within a pipeline to specify what should happen if an activity fails. For example, we can specify that the pipeline should continue running, skip the failed activity, or fail the entire pipeline.
- Monitoring: ADF provides built-in monitoring and logging capabilities that allow tracking the progress of pipelines and identifying any failures or issues. We can view the status of each activity and monitor the performance of the pipeline as a whole.
- Custom code: ADF also allows using custom code to handle failures and retries. For example, we can use Azure Functions or Logic Apps to implement custom retry logic or error handling.
All things considered, ADF offers a variety of built-in mechanisms for managing errors and retries in pipelines, and we can also use custom code to implement trickier scenarios. We can make sure that your pipelines are dependable and resilient in the face of errors or failures by utilizing these capabilities.
3. Consider a Scenario
“A company wants to migrate its data from an on-premises SQL Server database to an Azure SQL Database in the cloud. The company decides to use Azure Data Factory to handle the data migration.” Can you explain in detail what challenges the company faces in this situation and how it can overcome them?
Challenges:
- Data validation: In this scenario, the company may need to validate the data in the on-premises database before migrating it to the cloud. This can be a complex process, especially if the data is spread across multiple tables or databases.
- Connectivity: Another challenge is ensuring the on-premises database is connected to the cloud-based Azure SQL Database. This requires configuring network settings and security protocols, which can be difficult and time-consuming.
- Data transformation: The company may need to transform the data before migrating it to the cloud because the on-premises database may not be in the same format or structure as the data in the Azure SQL Database. This can involve writing custom scripts or using third-party tools to convert the data.
- Data loss: The company must ensure that all data is transferred securely and that there are no errors or discrepancies during the migration process.
Overcoming Challenges:
- To overcome the data validation challenge, the company can use data profiling tools to analyze the data and identify any inconsistencies or errors. This will help to ensure that the data is valid and consistent before migrating it to the cloud.
- To overcome the connectivity challenge, the company can use Azure Data Factory's connectivity features, which provide a secure and reliable connection between on-premises and cloud-based databases.
- To overcome the data transformation challenges, the company can use Azure Data Factory's data transformation capabilities, like - data mapping and transformation functions. This will help to ensure that the data is in the correct format and structure before migrating it to the cloud.
- To mitigate the risk of data loss or corruption, the company can use Azure Data Factory's built-in monitoring and logging features to track the progress of the migration and identify any errors or issues. Additionally, the company can perform regular backups of the data to ensure that it is not lost during the migration process.
4. Can You Explain the Concept of Data Flow in Azure Data Factory and How It Differs From Pipeline Activities?
Data Flows |
Pipeline Activities |
|
Purpose |
Used specifically for data transformation tasks like ETL processes. |
More general-purpose and can perform a variety of tasks. |
Graphical Interface |
Yes |
No |
Components |
Source, transformation, and sink components. |
Copying files, executing scripts, and triggering external processes. |
Data Transformation |
Yes |
Yes |
Orchestration |
No |
Yes |
Data Integration Approach |
Code-free data integration using a drag-and-drop interface. |
Code-based data integration using JSON definitions. |
Performance |
Optimized for large-scale data transformation operations with parallel data processing. |
Can handle high volumes of data but may not be as optimized for large-scale data transformations as Data Flows. |
Monitoring |
Data Flows have their own monitoring interface, which is separate from pipeline monitoring. |
Pipeline activities are monitored through the pipeline monitoring interface. |
5. How Do You Monitor and Troubleshoot Azure Data Factory Pipelines? Can You Provide an Example of a Pipeline You Had to Troubleshoot and How You Resolved the Issue?
Azure Data Factory provides several tools for monitoring and troubleshooting pipelines. Some of these include
- Monitoring dashboards: Data Factory provides monitoring dashboards to track pipeline executions, errors, and performance metrics.
- Logs: Data Factory logs all pipeline activities, errors, and status updates to Azure Monitor Logs. We can use this information to troubleshoot pipeline issues and analyze pipeline performance.
- Alerts: Data Factory provides alerting capabilities to notify you when pipeline activities fail or specific performance metrics are exceeded. Alerts can be configured to trigger actions, such as sending email notifications or executing custom scripts.
- Debugging: Data Factory provides debugging capabilities to help you diagnose and fix pipeline issues. Debugging enables you to step through a pipeline execution and examine data at each stage of the pipeline.
As an example, let's say we have a pipeline that is failing to load data into a target system. The pipeline consists of a data flow that transforms data from a source system and loads it into a target Azure SQL database.
To troubleshoot this issue, we would begin by checking the pipeline monitoring dashboard and logs to identify any errors or performance issues. We may also review the pipeline activities to ensure that they are executing correctly and that any dependencies between them are configured correctly.
If we cannot identify the issue from the monitoring dashboard or logs, we may need to enable debugging and step through the pipeline execution to identify the issue. In this case, we would set a breakpoint in the data flow and execute the pipeline in debug mode. As the pipeline executes, we would examine the data at each stage of the pipeline and identify any issues with data transformation or loading.
Once we have identified the issue, we can take steps to resolve it. For example, we may need to adjust the data flow transformations or mappings, modify the schema of the target database, or adjust the pipeline dependencies or triggers.
6. How Do You Handle Schema Drift in Azure Data Factory and Ensure Your Data Is Accurately Mapped to Your Target Schema?
Schema drift can happen when the source data's schema alters, which makes it challenging to accurately map the data to the target schema. To manage schema drift and make sure your data is accurately mapped to the target schema, we can take the following actions in Azure Data Factory:
- Use dynamic mapping: Azure Data Factory supports dynamic mapping, which enables us to handle schema changes by automatically mapping the fields in the source data to the appropriate fields in the target schema.
- Use the "Schema Drift" feature: Azure Data Factory's Schema Drift feature can detect changes in the source data schema and alert for discrepancies. This feature enables us to modify your mapping to account for the schema changes.
- Use data preview and sampling: Use Azure Data Factory's data preview and sampling features to verify that the source data is correctly mapped to the target schema. This enables us to catch any issues early on and make the necessary modifications to mapping.
- Use mapping data flows: Using this, we can more easily modify the data mapping as needed and take a more visual approach to design data transformations. Schema changes can be handled more easily when mapping data flows, which makes it simpler to guarantee accurate data mapping.
7. Can You Describe a Scenario Where You Had To Optimize the Performance of an Azure Data Factory Pipeline? What Techniques Did You Use, and What Were the Results?
Consider a situation where a business was having trouble with slow performance when transferring large amounts of data from an on-premises SQL Server database to an Azure SQL Database using Azure Data Factory. Data processing was being delayed because the pipeline was taking longer than anticipated to finish.
To optimize the performance of the pipeline, We can use the following techniques:
- Parallel execution: Setting the number of parallel copy activities to a higher number increased the pipeline's parallelism and allowed for the simultaneous transfer of more data.
- Optimized data flow: The data can be transformed and optimized for the target schema using Azure Data Factory's mapping data flows, which increased the pipeline's efficiency and decreased the amount of data that needed to be transferred.
- Reduced network latency: To decrease network latency and boost performance, we can move the Azure SQL Database to a region that is nearer the on-premises SQL Server database.
After implementing these techniques, the pipeline's performance improved significantly. The data transfer time was reduced by more than 50%, and the pipeline was able to process large amounts of data more efficiently.
8. How Do You Secure Azure Data Factory Pipelines and Ensure That Sensitive Data Is Protected?
Azure Data Factory provides several features to help secure pipelines and ensure that sensitive data is protected. Here are some steps you can take:
- Use Azure Key Vault: It is a secure storage option for private information like passwords, trade secrets, and keys. To store and manage credentials and other sensitive information that your pipeline needs access to, we can use Azure Key Vault. This helps keep your pipeline secure by avoiding the need to store sensitive information in plain text.
- Use Azure Managed Identities: It provides a way to securely authenticate with Azure services without needing to manage credentials manually. You can use Azure Managed Identities to authenticate Azure Data Factory to access other Azure services, such as Azure Storage or Azure Synapse Analytics. This helps ensure that only authorized users and services can access your data and pipelines.
9. Can You Explain the Difference Between a Self-Hosted Integration Runtime and an Azure Integration Runtime in Azure Data Factory?
In Azure Data Factory, there are two types of Integration Runtimes:
I. Self-Hosted — It is installed on your own on-premises servers or virtual machines and is used to move data between on-premises systems and the cloud. This type of Integration Runtime provides connectivity to your on-premises data sources and destinations.
II. Azure — It is a fully managed Integration Runtime that runs within the Azure environment. It provides connectivity to various Azure data sources and destinations.
The key difference between the two types of Integration Runtimes is where the compute resources are located.

The above diagram illustrates how data flows between the various components in a Self-Hosted Integration Runtime and how the Integration Runtime provides connectivity to on-premises data sources and destinations.
10. How Would You Use Azure Data Factory to Load Data From Multiple Tables in an On-Premises SQL Server Database Into a Single Table in an Azure Synapse Analytics Database While Also Applying Transformations to the Data?
To load data from multiple tables in an on-premises SQL Server database into a single table in an Azure Synapse Analytics database using Azure Data Factory, you would need to follow these steps:
- Create Linked Services: Create linked services for your source SQL Server database and your destination Synapse Analytics database.
- Create Datasets: Create datasets for each of the tables in your source SQL Server database that you want to load data from, and create a dataset for your destination table in your Synapse Analytics database.
- Create a Pipeline: Create a pipeline with a Copy Activity for each source table you want to load data from and any additional transformations that may be required. Within the Copy Activity, you can use a SQL Server query to specify the data you want to copy from each source table, and you can use mapping data flow to apply transformations to the data as it is copied.
- Schedule the Pipeline: Once your pipeline is created, you can schedule it to run on a regular basis to ensure that your data is always up-to-date.
Conclusion
As an experienced user or potential candidate for an Azure Data Factory role, it's important to have a strong understanding of the platform's key features, capabilities, and best practices.
In this article, we've covered some of the most common interview questions for experienced Azure Data Factory users.
Opinions expressed by DZone contributors are their own.
Comments