Basic Convolutional Neural Network Architectures
This article reviews some ways that CNN architectures differ, including how the layers are structured, the elements used in each layer, and how they are designed.
Join the DZone community and get the full member experience.
Join For FreeThere are many convolutional neural network (CNN) architectures. Those architectures differ in how the layers are structured, the elements used in each layer, and how they are designed. This affects the speed and the accuracy of the model which will help to perform various tasks.
The following are some of the common CNN architectures. The word "common" is referring to pre-trained weights which are fine-tuned by deep learning libraries such as Keras, TensorFlow, Fastai, and so on (Karim, 2019).
AlexNet
This architecture consists of 8 layers (convolutional — 5 and fully connected — 3). There are several features that make the AlexNet architecture special:
- ReLU nonlinearity: instead of the tanh function (a rescaled logistic sigmoid function) the architectures use Rectified Linear Units. The advantage of using ReLu is the training time. It was skilled to identify a 25% error on the CIFAR-10 dataset, six times faster than using tanh (Wei, 2019).
- Multiple GPU: the architecture allows multi-GPU training. This process is done by putting half of the network’s neurons in a GPU and the rest on a different GPU. This allows to cut down the training time and allows to train bigger models as well (Wei, 2019).
- Overlapping pooling: the traditional CNN "pool" outputs of neighboring groups of neurons with no overlapping. Nevertheless, after introducing the overlap, there was a reduction in error by 0.5% (Wei, 2019).
- Data Augmentation: label-preserving transformation was used to make the data more varied. Also, image translation and horizontal reflections increased the training (Wei, 2019).
- Dropout: this will turn off neurons with a predetermined probability. This means that every iteration is using a different model parameter (Wei, 2019).
In an ImageNet competition in 2010, “the best model achieved 47.1% top-1 error and 28.2% top-5 error. AlexNet vastly outpaced this with a 37.5% top-1 error and a 17.0% top-5 error” (Wei, 2019). AlexNet architecture is recognized as a powerful model that is capable of achieving high accuracies on every dataset.
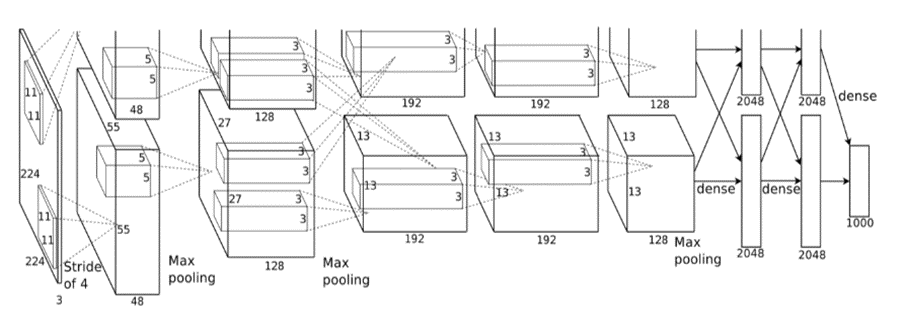

ResNet (Residual Network)
According to author Jay (2018), the problem that ResNet is solving is: “When deeper networks start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated and then degrades rapidly” (Jay, 2018).
It is stated that in order to get a better accuracy going deeper into layers would benefit. But the author (Shorten, 2019) mentions that adding more layers to an existing system won’t help to achieve the goal because with the network depth increasing, the accuracy gets saturated. When back-propagating it might give unusual values. This will eventually increase the error rate of the network. In order to give a solution for this, the ResNet provides "skip connections." The below diagrams demonstrates the skip connection in the ResNet.
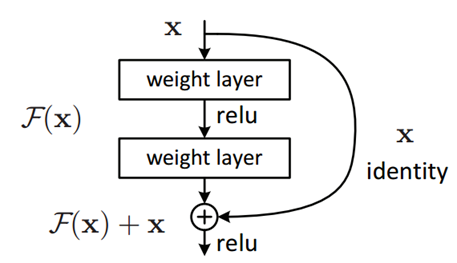
In the traditional neural networks, the output of each layer will pass on to the next set of layers but in the ResNet, each layer is fed with the output of the previous layer along with the input of the few layers back (figure: identity). This will avoid the vanishing gradient problem and eventually increases the accuracy and the speed of training (Shorten, 2019).
ResNet50 is a convolutional neural network that consists of fifty layers. This allows us to load a pre-trained edition of a network with more than a million images (Mathworks, 2020). This was the winner of the image-net competition and currently, developers use ResNet as the backbone of many data science projects (Shorten, 2019).
Inception Net
ResNet network created a deeper network, whereas in the Inception Net it will make the network wider. This is done by a parallel connection of multiple layers having different filters. Then concatenating all the parallel paths to pass it to the following layer.
There are different types of Inception Net. According to the author (Basaveswara, 2019), the differences between them are:
- “Instead of using a 5*5 filter, use two 3*3 filters as they are computationally efficient” (Basaveswara, 2019).
- “Using a 1*1 Conv2D layer with smaller filter count before performing any Conv2D layer with larger filter sizes as 1*1 filter with less filter count will reduce the depth of the input and hence is computationally efficient” (Basaveswara, 2019).
- “Instead of performing a 3*3 filter, perform 1*3 filter followed by a 3*1 filter. This will drastically improve the computational efficiency” (Basaveswara, 2019).
VGG Net
The VGG network is known for its simplicity. The architecture only consists of 3x3 convolutional layers along with two fully connected layers. Each of the FC has around 4,096 nodes and those are supported by a SoftMax classifier (Rosebrock, 2017).
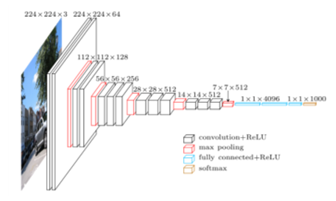
The VGG Net has two types, 16 and 19, which vary on the number of layers consists. The authors first trained the small version of the VGG network, and then it was used for the larger deeper network. According to the authors, you can notice the described process if you attentively examine the architecture. They also suggest recording all of the outcomes in each layer so that you may compare them. The drawbacks of this network are it has a very slow training process and architecture weights are large — it takes a lot of disk and bandwidth (Rosebrock, 2017).
References
- https://towardsdatascience.com/illustrated-10-cnn-architectures-95d78ace614d#e971
- https://towardsdatascience.com/alexnet-the-architecture-that-challenged-cnns-e406d5297951
- https://medium.com/@14prakash/understanding-and-implementing-architectures-of-resnet-and-resnext-for-state-of-the-art-image-cf51669e1624
- https://towardsdatascience.com/introduction-to-resnets-c0a830a288a4
- https://www.mathworks.com/help/deeplearning/ref/resnet50.html#:~:text=ResNet%2D50%20is%20a%20convolutional,%2C%20pencil%2C%20and%20many%20animals.
- https://towardsdatascience.com/cnn-architectures-a-deep-dive-a99441d18049#:~:text=Various%20CNN%20Architectures,many%20other%20image%20processing%20tasks
- https://www.pyimagesearch.com/2017/03/20/imagenet-vggnet-resnet-inception-xception-keras/
Opinions expressed by DZone contributors are their own.
Comments