How to Port CV/ML Models to NPU for Faster Face Recognition
This article explains the process of porting face recognition models to Rockchip NPU for higher performance in access control systems (ACS).
Join the DZone community and get the full member experience.
Join For FreeRecently, our development team faced a new challenge: one of our partners was implementing an access control system using a single-board computer from Forlinx. To meet the existing time constraints for face recognition operations, we decided to port our models to the NPU. What we can say after porting is that the NPU is generally a reliable way to put heavy processing on an edge device.
So, our partner needed to detect faces in a video stream and provide 1:1 matching (face verification). To better understand what this means, let's recall the basic face recognition pipeline diagram.
How Face Recognition Works: Basic Pipeline
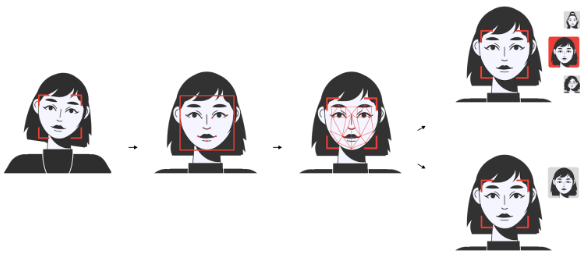
Step 1
First, the detection module finds a face in the image. As a rule, all face detectors that are used in production today are convolutional neural networks (CNNs). The detection result is the coordinates of a bounding box (bbox) around the detected face.
Step 2
After the face is detected, to optimize further operations, the image is automatically cropped based on the calculated coordinates of the bounding box (bbox). Then, the system finds the key points of the face. This is also done by a neural network, sometimes a separate one (face fitter), sometimes the same one that does the detection. In our case, we use a separate convolutional neural network for this operation.
Step 3
Then, based on the key points found, the face is aligned to the frontal position (normalized) for better handling of face recognition tasks. This is an algorithmic procedure, and in our case, it is performed as part of creating a face biometric template.
Step 4
And finally, another neural network extracts a face biometric template from the aligned face crop. These templates are used to determine a similarity degree between two facial images, i.e. verify faces.
Time Constraints and Hardware Used
Often, we can neglect the time of image preprocessing, postprocessing of the neural network results, as well as the time of comparing two biometric templates — these are a few tens of milliseconds. The longest time here is the inference time of neural networks. In our case, there are three neural networks in a pipeline:
- Face detector
- Face fitter
- Face template extractor
At the same time, we had the following time constraints:
- The total operating time of face detector and face fitter should be no more than 40 ms
- Extracting a biometric template and comparing two templates should be no more than 500 ms
It would seem that the time constraints are generally quite acceptable. But now let’s examine the hardware we worked with: OK3568-C.
OK3568-C Basic Parameters
- CPU: Rockchip RK3568 quad-core [email protected]
- GPU: Mali-G52-2EE
- NPU: 1TOPS, supports INT8/INT16/FP16/BFP16 mixed operations
- RAM: 4GB
- ROM: 16GB eMMC
- OS: Linux
The OK3568-C is not the most powerful device, which presented its own challenge. We chose specific models of face detector, face fitter, and face template extractor and tested their operating time. The results presented in the table below, as expected, did not fit into the stated time limits.
After that, we moved on to inference on the Rockchip NPU.
Rockchip NPU Inference
To work with Rockchip NPU, you need to use a special inference framework — RKNN-Toolkit2. Fortunately, it supports converting models from PyTorch, TensorFlow, and ONNX. We successfully used the last option.
Note that inference on the Rockchip NPU can be carried out in two ways (at least for our target NPU model):
- Default mode. In this case, the models are converted from Float32 to Float16, and there is a slight (often) loss of accuracy.
- Inference with quantization. In this case, the models are converted from Float32 to Int8, there is a loss of accuracy, sometimes quite noticeable.
Having received Float16 and Int8 variants for each model, we conducted measurements comparing the inference time on the CPU and NPU of the board. The results are presented below.

Thus, the requirements for inference speed were met. However, we also had to face problems with the quality of quantized models. It turned out that if you quantize absolutely all parts of the pipeline in Int8, the recognition accuracy will drop to almost zero.
After fiddling around for a couple of days, our specialists identified the optimal pipeline in terms of accuracy, in which:
- Face fitter is used in the Float 16 version
- Only the most labor-intensive part of the template extractor is quantized in Int8
And now, we still fit the speed requirements and have a minimal drop in the quality of the face recognition pipeline.

Despite the observed drop in face recognition quality, the Int8-quantized models still showed promising results after several experiments. In fact, these models can effectively be used in use cases such as access control (ACS), as evidenced by their successful performance on the LFW dataset.
Conclusion
To summarize, we note that the use of NPU has proven to be an effective way to speed up the inference of CV/ML models. At the same time, a small decrease in accuracy, which is not critical for access control tasks, is fully justified by compliance with face recognition time constraints.
Opinions expressed by DZone contributors are their own.
Comments