Best Practices for Batch Processing in IBM App Connect Enterprise as a Service
In this article, we make recommendations for designing flows that use batch processing and include guidance on how to troubleshoot issues.
Join the DZone community and get the full member experience.
Join For FreeBatch processing is a capability of App Connect that facilitates the extraction and processing of large amounts of data. Sometimes referred to as data copy, batch processing allows you to author and run flows that retrieve batches of records from a source, manipulate the records, and then load them into a target system. This post provides recommendations for designing flows that use batch processing. It also includes a few pointers on how to troubleshoot any issues that you might see, and in particular which log messages to look out for.
Here's some more information about batch processing in App Connect:
- The article Introducing Batch Flows in IBM App Connect Enterprise as a Service on AWS introduces the batch processing function of App Connect and describes how to use it.
- The follow-on article, Deploying and monitoring batch flows in IBM App Connect Enterprise as a Service, describes how to use the public APIs to interact with your batches.
- You can read more about batch processing in the product documentation.
First Things First: Do You Need Batch Processing?
In addition to the Batch process node, App Connect has a For each node, with either sequential or parallel processing. So when should you use batch processing versus for-each processing?
You should use the for-each node for a small number of records that don't take long to process and have small memory requirements. Small here means less than 1000 but typically significantly less than that, more like a few or tens of records. The For each node is used to iterate over elements that are already in the payload, typically retrieved by a Retrieve node earlier in the flow.
You should use sequential for-each processing when the order in which you process the elements in the collection is significant. For example, you want to process April's sales after March's data. Use the for-each parallel processing option when the order isn't significant, which typically results in shorter running times for the flow.
For-each processing is simpler, synchronous, and executed as part of the flow. All of your processing and error handling is kept within a single flow, which is ideal if you're dealing with a smaller number of records.
You should use batch processing for large volumes of data. Each record will have its memory limit, and the time limit for processing applies to each record. Batch nodes are asynchronous, and only the initiation of the batch process is part of the initial flow. The Batch node processes records from a source system without adding all of them to the flow as a whole.
There's no way to specify the order in which the Batch node processes records, but you can add your logic to the flow that will be completed after all records in the batch have been processed.
Using batch processing might incur higher costs. For more information, see the pricing plans in the product documentation.
Triggering Batch Processing
Batch processing is often run on a schedule, typically by using the Scheduler from the Toolbox.
In the logs, you can filter messages based on your flow name and then query for “Batch process has been started” and check the timestamps. Is this the frequency that you expected? Note that there’s a restriction on how many concurrent batches (currently a maximum of 50) you can have running at a given moment for a flow.
If you’re using any other event as a trigger, check that this event is happening with the expected frequency. Batches typically contain a high volume of records, so they can add to your costs, so checking that they’re triggered at the intended cadence is good practice.
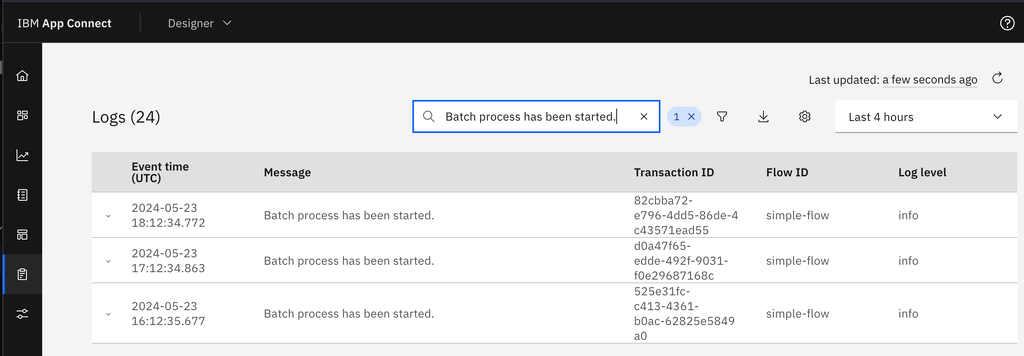
Batch processing is asynchronous. The triggering flow might be completed while the batch process continues until all the records have been processed. So it’s normal to see log messages that show that the flow is completed while the batch process is still running.
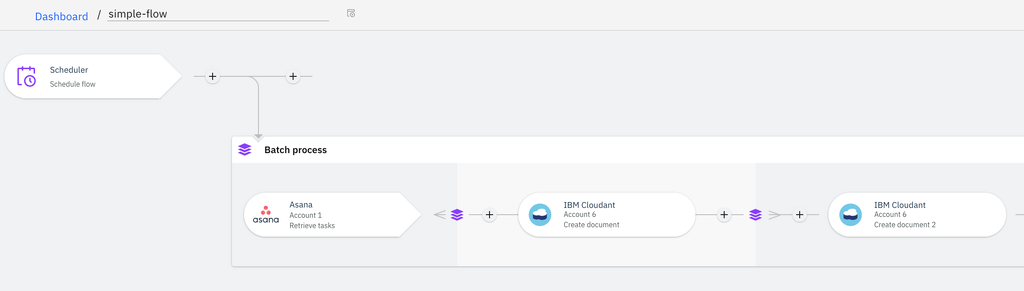
Batch Extraction Tips
A Batch node extracts and then processes records from a certain source. You have options to limit the number of records that you extract, by using filters or by specifying the maximum number of records that you want to process, depending on your business needs. It's more efficient to extract only the records that you're interested in rather than extracting everything and then processing only the records of interest.
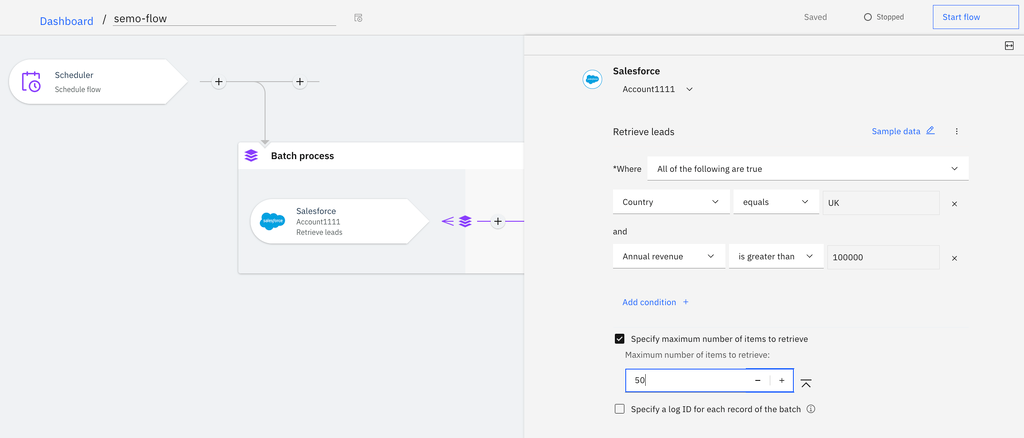
In the example above, 50 Salesforce leads from the UK with an annual revenue above a certain threshold are extracted for processing. The records are extracted from the source application (Salesforce) in groups of records called pages (the size of the pages is defined by Salesforce).
The extraction of records from the source system might fail, which could have a temporary or permanent cause. The temporary cause might be an unexpected load on the data source, rate-limiting errors, or momentary network outages. Permanent causes could be credentials for the source becoming invalid or the data source being taken offline.
If the extraction fails, the batch process is paused.
You can view the paused batches either in the UI or with the API, as described in the articles linked previously, or you can see the auto-paused message in the log.
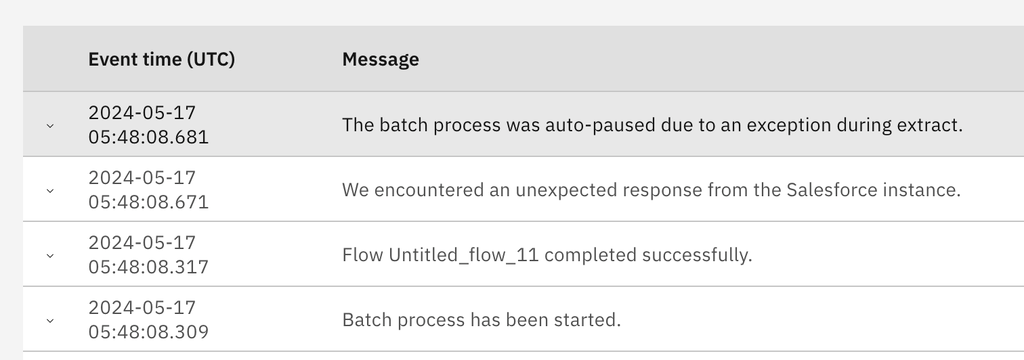
If the source system provides it, the reason for extraction failure is present in the logs:
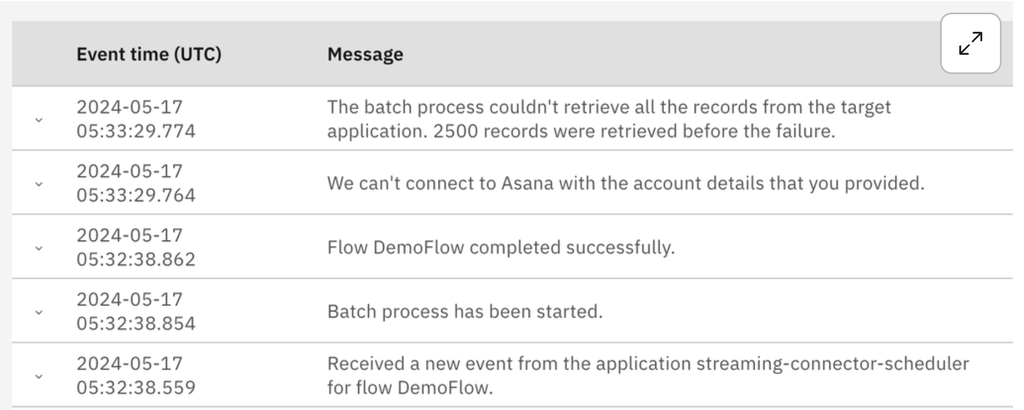
App Connect tries to restart the batch a fixed number of times at increasingly large intervals, before stopping after a specified interval. This resilience is built into the batch processing function to give it the best chance of completing without user intervention. The batch will resume when the extraction failure is temporary. If the extraction failure is permanent, clearly the batch process can't be resumed. If the cause of the pause is resolved, you can resume the batch process yourself, either in the UI or in the API, without waiting for the system to resume it.
Pausing a batch process pauses the extraction. The records that were extracted will be processed, but it's not possible to pause the processing itself.
You can also pause or even stop the batch process yourself in the UI or API as described in the linked posts. You might want to do this if you observe a mistake in the configuration of the Batch node or for any other business reason. You can also resume batches on demand.
When the first records have been extracted, the processing of those records begins.
Batch Processing Tips
The processing flow is triggered for each record in the batch. If all goes well, you will see successful log messages like these.
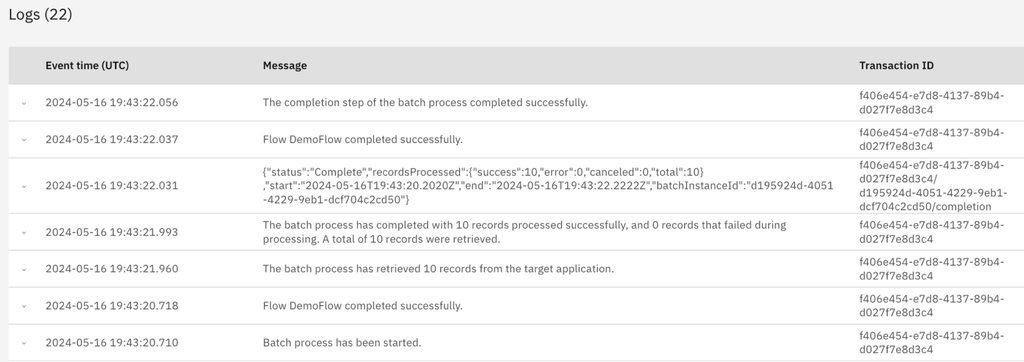
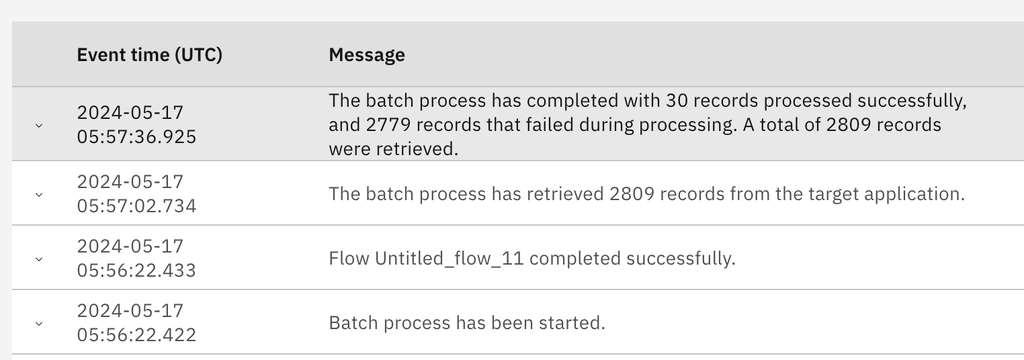
The processing of records might fail, which could be because an individual record has incorrect data or the target system is unavailable. The target system could be unavailable from the beginning of the batch or it could become unavailable during the running of the batch. You will see errors in the log for each failing record. The error messages might be different depending on the application.

There's no equivalent auto-pause function for record processing. Failing records are recorded as such and a summary log that's created when the batch is completed will tell you what has happened.
Batch Completion
It's good practice to add a batch completion flow that will run after all your records have been processed and either record the output of the batch process or take some action depending on the result.
The completion flow has a BatchOutput object, which provides a summary of the batch results.
You might have your own business rules for the number of acceptable errors in a batch. In some cases, the only successful outcome of the batch is if 0 errors are reported; in other cases, a small number of errors is acceptable.
You should look closely if all or most records have failed. The most common cause for this failure is that the target system has become inaccessible because either the target system is unavailable or the credentials are invalid.
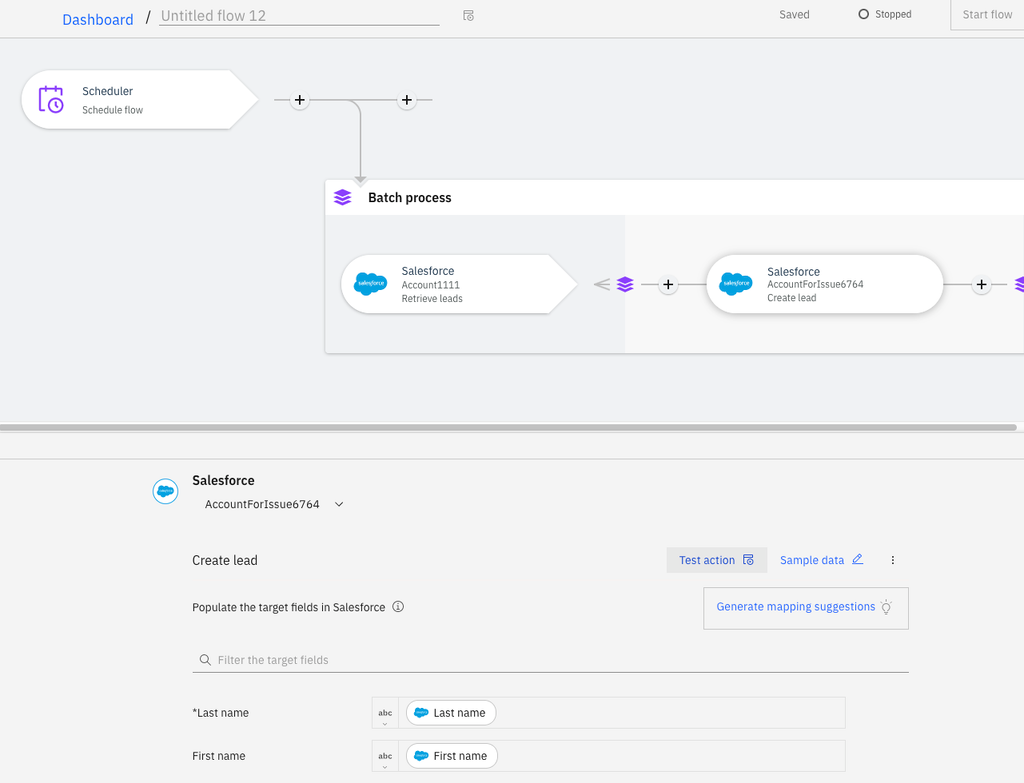
Log messages in this situation depend on the information that's provided by the third-party applications. So how can you check if failure is due to invalid credentials if that information isn't provided in the logs? The easiest way is to test each action in the batch process in stand-alone mode by using the Test action button.
Batch Process API
An API is available for interacting with batches. You can find details of how to use the API to monitor batch processing in Deploying and monitoring batch flows in IBM App Connect Enterprise as a Service.
Probably the most common use of the API for batch processing is to get batches for a flow that gives you a snapshot of the batches for an integration runtime at the moment the API call is made. The returned object is a JSON object that can be processed in any way. A common way is with a jq query. Here is an example of ordering batches by end date.
curl --url "$appConEndpoint/api/v1/integration-runtimes/<irName>/batches" … | jq -r '["id","status","start","end","expiry","retrieved","processed","succeeded","failed","canceled"], ((.batches | sort_by(.start) | reverse)[] | [.id, .state, ((.end // 0) / 1000 | todate), ((.end // 0) / 1000 | todate), ((.expiry // 0) / 1000 | todate), .extract.recordsExtracted, .recordsProcessed.total, .recordsProcessed.success, .recordsProcessed.error, .recordsProcessed.canceled]) | @tsv' | column -ts$'\t'

The API returns the state of the batch or batches at the moment when the API is executed. You will likely get different results if you run the API repeatedly.
If you’re seeing an error that indicates that you have a maximum number of running batches, then you run the API and get no running batches, the batches might have been completed since you ran the API. To check, sort by the “end” attribute as described above and check when the batches are finished.
“Where have my batches gone?” you might ask. “I checked yesterday and now they’re gone!”
Completed batches are cleared after a time interval. Attempts are made to resume paused batches a few times, then they’re expired and cleared after a time interval.
If you need to keep track of the batch runs, use the completion flow and add your own logic to persist information on the batch runs.
As the Spider-Man comics say “With great power comes great responsibility.” Use your batches wisely and they’ll do a great job at fulfilling your enterprise requirements.
Published at DZone with permission of Doina Klinger. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments