Best Quality Management Strategies With Software Rollbacks
Having a sound release management plan, building servers over backups, and using Blue/Green deployments are just a few strategies that can help you manage quality.
Join the DZone community and get the full member experience.
Join For Freeit is the responsibility of data professionals to protect business data. changes to the structure and coding of software that is essential to organizational operations must be executed with little downtime or data loss. consequently, database administrators work tirelessly to prevent system crashes and data failures. however, the risk of failure in deployment, while possibly minimized, can still exist.
release management tends to anticipate positive results. however, real world technology at times brings about undesirable results when the release doesn’t go precisely as anticipated or planned. when you have tested software changes to the database before confirming changes into the system, and you have test automation integration , qa has performed analytics with refined testing metrics , and scripts have been tested in staging against a copy of the database, red error messages still may cascade down your testing screen, indicating a crash and burn of your hard work and concentrated efforts. what do you do now?
what are the options for getting back on track when operations respond to software releases with system crashes? do you use a backup to restore system functions? do you idealize the system with abstractions then switch back to the real-world issue? do you execute a software rollback to revert the deficiencies while preserving the database?
one way to carry on with software functionalities is to fix or patch specific software issues and execute another release. however, fixing the software only addresses the application deficiencies. software fixes do not approach the possibilities of system or interface errors.
therefore, when things go awry, software rollbacks are the all-inclusive manner of return to a point before the act-up occurred. rollbacks return the software database to a previous operational state.
to maintain database integrity, rollbacks are performed when system operations become erroneous. in worst case scenarios, rollback strategies are used for recovery when the structure crashes. a clean copy of the database is reinstated to a state of consistency and operational stability.
the transaction log, or history of computer actions, is one way to utilize the rollback feature. another is to rollback through multi-version currency control, an instantaneous method of concurrently restoring all databases.
at times rollbacks are cascading, meaning a failed transaction causes many to fail. all transactions which the failed transaction supports must also be rollbacked. practical database recovery strategies avert cascading rollbacks. enterprise, development, and qa departments therefore consistently seek to devise the best strategies for software rollbacks.
best practice strategies are to avert the need for software rollbacks through incremental and automated testing within development and qa environments. however, even with iterative testing, software and system failures do happen.
a sound release management plan
sound development, testing, deployment focused on the end user, and system performance are the fundamentals of release management. the release management team of developers, quality assurance teams , and it system administrators perform activities geared towards successfully completing deployment of software applications. release management teams must ensure that there is a plan to smoothly recover from deployment calamities. planning mechanisms focused on documented rollback procedures that effectively enable recovery from deficiencies in deployment.
- develop a policy for software versioning. assign singular version names, singular numbers, or singular digital logic states to each version. differentiate test versions from release versions with internal version and released version numbering.
- test new versions in a simulated production environment. simulations go far in tying down anticipated functionalities into near-actual performance over time. modeling the system reveals the key behaviors or functions of physical or abstract processes. the purpose is to demonstrate how processes will respond to real world input, interfaces, stresses, and system commands.
- use a build server which extracts data exclusively from the repository. data in this way is both traceable and reproducible and reduces the risk of code that is outdated and includes undocumented updates. when new coding is checked into the repository, the build server bundles the revised version within the software development environment. in addition, the build server allows deployment of bundles within different environments. build servers also allow deployment to be executed with a single command.
- maintain the configuration management database. to sustain it installations of data information technology warehouse assets and intellectual properties, as well as data interactions, the configuration management database must be consistently managed and updated.
- possibly add an abstraction layer to isolate certain functionalities and thereby separate the concerns of a computer program into distinct sections. the use of abstraction layers in this manner enhances system independence and the ability of a system to operate with other products or systems without restrictions.
build servers over backups
backups require sizable computer resources with uncertain success. backups themselves and backup recoveries are slow and tedious. backup strategies are also inconsistently verified with source code fundamentals and reliability, as well as with raw data. recovery with backups mean that there's a longer user-restricted mode to prevent data from being added. rollbacks require running transaction log backups in conjunction with recovery rather than quicker and more reliable rollbacks from a build server repository. the delays in recovery with transaction log rollbacks only increase as the size of the database increases.

automated scripts can be created with build servers, while with transaction log backups, scripts must be manually created and tested. rollback scripts are some of the most difficult aspects of application development and deployment to create and maintain, especially when data is updated. maintaining rollback scripts with structural data updates will likely require complex data migration scripts. finally, when errors are discovered during the release and new transactions are in place, backup rollbacks will cause the loss of data. rollbacks from build server repositories providing automated updates are much more reliable for system recovery.
more on abstraction layers
branching by abstraction to gradually change a software system to allow releases which are concurrent with changes is a fairly common coding practice. however, the method of introducing change to a system through the use of abstraction layers for the purpose of enabling supporting services to concurrently undergo substantial changes has not always been universally recognized as a rollback facilitator.
abstraction occurs without requiring changes to front-end coding unless desired. the built-in background database abstraction layer of stored procedures can work on top of the underlying system architecture to accommodate additional parameters (such as version numbers or flags within the rollback routine) to fulfill coding commands while both new and old software versions continue to function. updates to the structure and the abstraction layer that support structural change allow you to introduce new coding alterations while leaving existing code untouched. abstraction layers not only smooth deployment but also simplify rollbacks. with abstraction layers, rollbacks merely need to consider how the code path relates to the original functionality, which abstraction layers have left in place.
abstraction layers do however require a thorough, and preferably automated, test procedure to prevent errors when older code travels through newer abstraction paths. fundamental database functionalities are retained, requiring consideration of original coding stability.
blue/green deployment
blue/green deployments are automated. automating deployment reduces system resistance and delays. automated deployments implement continuous delivery and continuous integration with no downtime and very little risk. from two copies of the database, blue/green deployments deploy to one final copy. with two copies in blue mode, if one copy does not deploy well, there is the option to switch to the second copy, retaining all data. once you have validated that deployment is fully implemented the application can be switched in green mode to the database.
blue/green deployments simplify rollbacks in that the old database and old coding are never accessed. even when transactions have occurred after release, immediate switchbacks to the old system can occur, avoiding the restore process or the need for rollback scripts. one of the safest and most efficient deployment and rollback mechanisms are blue/green deployments.
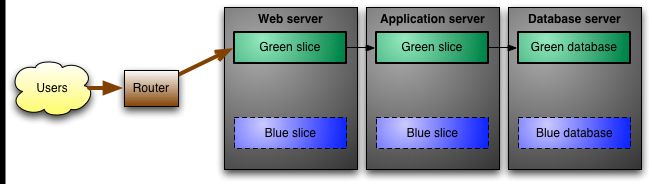
a blue/green deployment, however, requires a database that is small enough for two copies of the database to be accommodated on one server. in addition, reliable synchronization or reliable data migration creation and maintenance are required to sync data between databases.
an inherent issue with database deployment is retaining data when failures occur. combining rollback strategies with blue/green deployment can further reduce the risk of failed deployment, as well as better ensure complete and efficient rollback recoveries. combining strategies allows for more agility and flexibility for stable deployment or required rollbacks.
rollbacks and the enterprise
enterprise requirements for cost efficiency and roi dictate that software and system business functions are reliable. the length of time required for rollbacks necessarily becomes an enterprise issue. processing scenarios dealing with database updates, rollbacks, and recompiles are extremely efficient in avoiding and reducing the time required for rollbacks.
decentralized development even further dictates that the deployment pipeline be standardized per enterprise priorities. transparency in process and performance, as well as collaboration and enterprise test management , are crucial to communication with management concerns. diffused independent responsibilities, rather than centralized protocol, place reporting responsibilities and further obligations on developers, qa, and it administrators to continuously collaborate with business management and stakeholders.
rollback procedures must be executed within organizational boundaries with a discreet and defensive stance towards possibilities of risk. the process of rollbacks and recovery are direct in process and results. rollback operators, therefore, bear responsibility for directly communicating processes and collaborating on enterprise priorities in relation to executions. to assure that the rollback process only positively impacts business priorities, thorough and consistent collaboration is imperative between operational concerns and enterprise priorities.
theoretical or abstract considerations can commonly be overlooked as important for communication to management. however, theoretical rollback considerations can change the import or direction of deployment outcomes, which can pivot the objective away from business goals and priorities. reliable messaging and reporting, as well as face-to-face collaboration, is crucial within rollback activities.
the spectrum of rollback protocols in free and specialized domains can breathe new life into the stability of software and system interfaces. efficient rollback strategies reduce costs to the enterprise, enhance deployment time to market, and engage customer loyalty through efficient operations.
Published at DZone with permission of Sanjay Zalavadia. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments