Beyond Keywords: Modernizing Enterprise Search with Vector Databases
A modern search approach unlocks deeper insights, more relevant results, and boosts productivity across organizations; here's how AWS OpenSearch fits into this landscape.
Join the DZone community and get the full member experience.
Join For FreeIn the modern enterprise, data is everywhere — in emails, documents, customer records, support tickets, code repositories, and more. But as the volume and complexity of data grow exponentially, so does the challenge of finding the right information when you need it. Traditional search engines, based on keyword matching, are often frustrating and inefficient, returning irrelevant or incomplete results.
Fortunately, a new approach is transforming enterprise search: semantic search powered by vector databases. By understanding meaning rather than just matching words, this technology enables organizations to unlock deeper insights and dramatically improve efficiency.
Let’s explore how vector databases and semantic search work, why they outperform keyword-based search, and how enterprises are already benefiting from this breakthrough — including how AWS OpenSearch fits into this landscape.
The Problem With Traditional Keyword Search
At its core, most search engines scan documents for keywords that exactly match your query terms. For example, if you search for "cloud migration strategy," the system looks for documents containing those exact words.
This method is straightforward but has clear limitations:
- Context Ignorance: It treats words independently and lacks understanding of their context or intent. For instance, if you search for "Java," are you looking for the programming language, the Indonesian island, or coffee?
- Synonym and Phrase Blindness: If your document uses the phrase "lift and shift" but you search for "rehosting," a keyword-based search might miss relevant results because the terms differ.
- No Understanding of User Intent: Keyword search cannot infer that "how to move apps to AWS" is closely related to "cloud migration."
This means employees waste time sifting through irrelevant hits or worse, miss critical information entirely — a costly problem for enterprises.
Leveraging the Power of Vector Databases and Semantic Search
Vector databases store data as vectors — numerical representations of objects (like text or images) in a high-dimensional space. Each vector encodes the semantic meaning of the object, allowing the system to measure similarity by calculating distances between vectors.
How Does This Work in Practice?
Assume you want to find documents related to "automobile insurance" but don’t want to type exact keywords. Instead, the search engine converts your query into a vector that represents its overall meaning. It then compares this query vector against vectors representing all documents in the database and retrieves those that are closest in meaning — even if they don’t share the same words.
For example, documents mentioning "car insurance," "vehicle coverage," or "auto policy" could all be relevant and returned, despite the lack of exact keyword matches.
Creating Vector Embeddings: The Magic Behind the Scenes
How do we get from raw text or data to vectors?
This is done using embedding models — deep learning models trained on massive datasets to understand language nuances. Models like BERT, GPT embeddings, or Sentence Transformers analyze the text and convert it into dense numerical vectors, typically ranging from 128 to 768 dimensions or more.
For example, the sentence:
"How can we improve cloud security for multi-tenant SaaS applications?"
would be transformed into a vector capturing its overall meaning, relationships, and context — so it can be compared semantically against other sentences, questions, or documents.
Vector Search vs. Keyword Search: A Concrete Example
Imagine a customer support team searching for solutions to "email delivery failures." A traditional keyword search for "email delivery failure" might miss helpful articles titled:
-
"Troubleshooting SMTP errors"
-
"Why are my emails bouncing?"
-
"Fixing undeliverable mail problems"
Because these use different phrasing, they might rank low or be missed. A semantic vector search, however, recognizes these topics as closely related, retrieving all relevant documents that help solve the problem efficiently.
AWS OpenSearch: Bridging Keyword and Semantic Search
AWS OpenSearch Service (the successor to Amazon Elasticsearch Service) is a fully managed service that combines powerful traditional search capabilities with emerging support for vector search, making it an excellent option for enterprises looking to build semantic search capabilities within the AWS ecosystem.
Key Features Relevant to Semantic Search
-
Keyword and full-text search with advanced features like fuzzy matching, phrase search, and proximity queries.
-
Vector Search Support: Recent updates have introduced native support for vector similarity search, allowing you to index vector embeddings alongside traditional keyword indices.
-
Scalable, Managed Service: AWS handles infrastructure, scaling, backups, and security, enabling teams to focus on application logic.
-
Integration with AWS Ecosystem: Easily ingest data from AWS S3, Lambda, Kinesis, or custom pipelines, enabling seamless real-time indexing and search.
-
Hybrid Search Capabilities: You can combine keyword and vector search queries to balance precision and recall for your use case.
How AWS OpenSearch Fits into Enterprise Semantic Search
Enterprises often start with keyword-based search but want to add semantic layers without completely overhauling their infrastructure. OpenSearch allows incremental adoption of vector search by:
-
Generating vector embeddings using AWS AI services (like Amazon Comprehend or SageMaker-hosted models) or third-party models.
-
Indexing those vectors alongside keyword indexes.
-
Running combined queries that leverage both semantic and exact matching.
This hybrid approach enables enterprises to get the best of both worlds: familiar keyword search power with the intelligence of semantic vector search.
Note: Follow AWS Search set up from this aws guide.
How Semantic Vector Search Works in AWS OpenSearch?
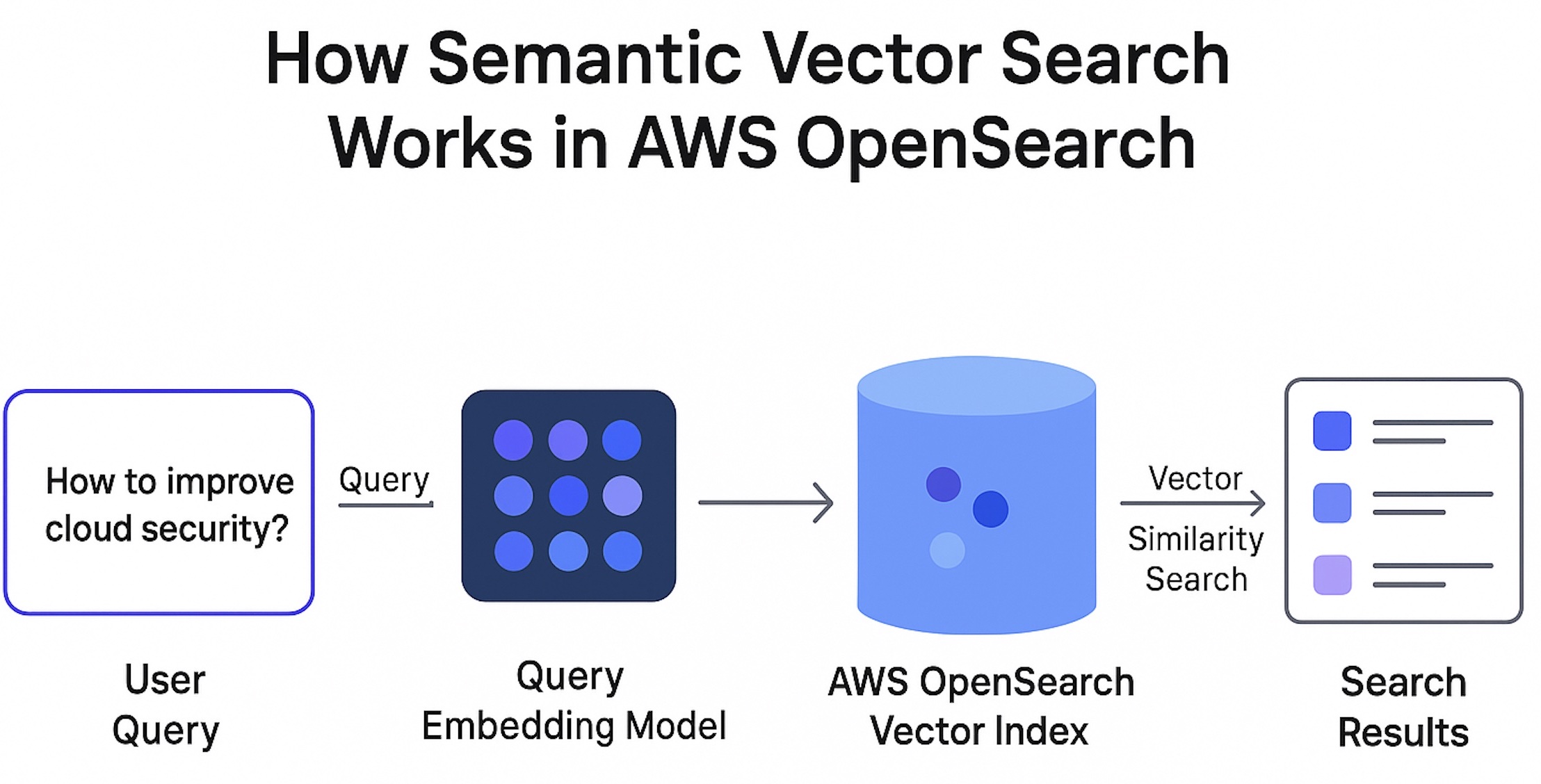
Sample Code: Vector Search with AWS OpenSearch
This example assumes you have:
-
An AWS OpenSearch domain set up with vector search enabled.
-
Embeddings generated for your documents using a model like Sentence-BERT or OpenAI embeddings.
-
Python
import requests import json from requests.auth import HTTPBasicAuth # Replace with your OpenSearch endpoint and credentials opensearch_url = "https://your-opensearch-domain.us-east-1.es.amazonaws.com" index_name = "enterprise-docs" username = "your-username" password = "your-password" # Example query embedding vector (e.g., 768-dimensional vector) query_vector = [0.12, -0.03, 0.56, 0.33, ...] # truncated for brevity # OpenSearch kNN query to find top 5 nearest vectors knn_query = { "size": 5, "query": { "knn": { "embedding_vector": { "vector": query_vector, "k": 5 } } } } # Search API endpoint search_url = f"{opensearch_url}/{index_name}/_search" # Perform the request response = requests.post( search_url, auth=HTTPBasicAuth(username, password), headers={"Content-Type": "application/json"}, data=json.dumps(knn_query) ) # Parse and print the results results = response.json() for hit in results['hits']['hits']: print(f"Score: {hit['_score']}") print(f"Document ID: {hit['_id']}") print(f"Source: {hit['_source']}") print("-----")Explanation
- embedding_vector is the field in your OpenSearch index that stores the document vectors.
- The knn query finds the top k=5 documents closest to the query vector by cosine similarity or Euclidean distance (depending on your index setup).
- Replace query_vector with the embedding of your user’s search query.
- The response returns matching documents with their relevance scores.
Advantages of Using Vector Databases in Enterprises
Improved Search Accuracy and Relevance
Because vector search understands meaning, it dramatically reduces irrelevant results. Users get precise, helpful answers faster, improving satisfaction and productivity.
Enhanced Discovery and Innovation
Employees can discover connections between concepts they hadn’t considered before, enabling new insights and better decision-making.
Multi-Modal Search Capabilities
Vector databases can store embeddings for images, audio, and other data types. For example, a product designer could search by sketch or image and find related design documents or assets.
Better Handling of Ambiguous Queries
Vector search infers intent better than keyword matching. For instance, a search for "Java performance issues" will prioritize results about the programming language, not the island or coffee.
Real-world use cases
Enterprise Knowledge Management
A global consulting firm implemented a vector-based semantic search to unify internal knowledge bases, emails, and project documentation. As a result, consultants could find relevant case studies or precedents in seconds, reducing project kickoff time by 30%.
Customer Support
A major telecom company used semantic search to enhance its support portal. Customers typing natural language questions found relevant FAQs and troubleshooting guides without needing exact keywords, increasing self-service rates by 25%.
Compliance Monitoring
Financial institutions leveraged vector databases to scan thousands of regulatory documents, identifying those related to emerging compliance issues even if terminology varied, helping avoid regulatory fines.
Challenges and Considerations
While vector databases and semantic search bring major advantages, enterprises should consider:
- Embedding Quality: The choice and tuning of embedding models heavily impact search accuracy.
- Compute Costs: Embedding generation and vector search can require significant computational resources.
- Data Privacy: Sensitive data embeddings need secure handling.
- Integration Complexity: Migrating or integrating semantic search with legacy systems requires planning.
Conclusion
The era of keyword-only enterprise search is ending. By embracing vector databases and semantic search, organizations can finally unlock the meaning behind their data, delivering faster, more accurate, and contextually rich results. AWS OpenSearch makes it easier than ever to bring semantic search into your existing infrastructure with scalable, managed, and hybrid search capabilities.
Opinions expressed by DZone contributors are their own.
Comments